







cuBLAS是一个线性代数子程式。与cuSPARSE不同的是,cuBLAS是一个传统线性代数库的接口,即基本线性代数子程序库(BLAS)。与BLAS类似,基于cuBLAS子程序操作的数据类型,对这些子程序进行了分类。第一类包含仅有向量参与的操作,如向量加法。第二类包含矩阵与向量之间的操作,如矩阵-向量乘法。第三类包含矩阵与矩阵之间的操作,如矩阵乘法。与cuSPARSE不同,cuBLAS不支持多种稀疏数据格式,它仅支持并善于优化稠密矩阵的操作。
由于最初的BLAS库使用FORTRAN语言编写的,因此它使用的是以列优先的数组存储和以1为基准的索引。列优先是指多维矩阵在一维地址空间中的存储方式。cuSPARSE是对稠密矩阵进行以行优先的压缩。在列优先的压缩格式中,在处理下一列之前会先遍历该列中的所有元素并将其存储在连续的地址空间中。因此,同一列的元素在内存中的位置是相邻的,而同一行的元素是不相邻的。这与行优先的cuBLAS的C/C++语义有很大差别,也就是说同一行中元素的存储位置是彼此相邻的。下图是同样的过程,但是是按列优先的顺序排列的。
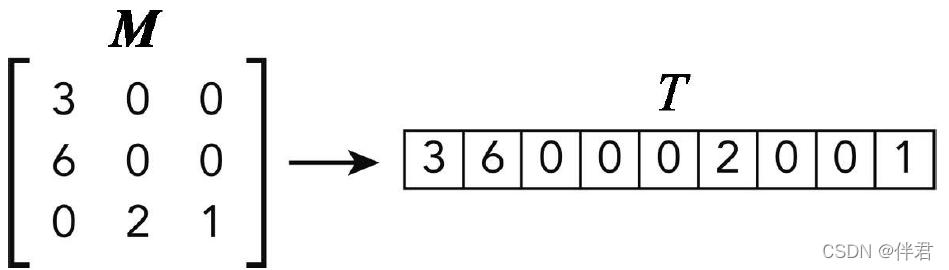
出于兼容性的考虑,cuBLAS库也选择使用列优先的存储方式。所以对于习惯了C/C++中行优先的数组布局的程序员来说,这是一个令人苦恼的问题。另一方面,以1为基准的索引意味着数组中第一个元素的引用是1而不是0,这在C语言和其他程序中常遇到。也就是说,一个N元数组中最后一个元素的引用是N而不是N-1。然而,cuBLAS库不能决定C/C++编程语言的构建,所以他必须使用从零开始的索引。这时FORTRAN BLAS库适用的列有限的规则就会出现一种混乱的情况,而以1为基准的索引规则就不会。
cuBLAS库有两个API。cuBLAS Legascy API是cuBLAS最原始的一个实现,现在已经不用了。现在的cuBLAS API用于所有的应用程序开发工作。在大多数情况下,它们之间的差别是很小的,但要注意的是,差别虽然小但仍然存在。
管 理 cuBLAS 数 据
与cuSPARSE相比,cuBLAS的数据格式和类型的注意事项相对少很多。所有操作都是在稠密cuBLAS向量或矩阵上完成的。使用cudaMalloc分配连续的设备内存给这些向量和矩阵,但是使用自定义的cuBLAS函数,如cublasSetVector/cublasGetVector和cublasSetMatrix/cublasGetMatrix,在主机和设备之间传输数据。尽管我们可以将这些特殊函数看作是cudaMemcpy周围的封装器,但它们可以更好地传输连续和不连续地数据。以下是对cublasSetMatrix函数的一次调用:cublasStatus_t cublasSetMatrix(int rows,int cols,int elementSize,const void *A,int lda,void *B,int ldb);前四个参数不需要特别说明:它们定义了要传输矩阵的维度,矩阵中每个元素的大小,以及主机内存中列优先的源矩阵A的内存位置。第六个参数B定义了设备内存中目标矩阵的位置。第五个和第七个参数的用途还不太清楚。lda和ldb指定源矩阵A和目标矩阵B的主维度。所谓主维度就是矩阵各自的总行数。如果主机内存中只有一个矩阵的子矩阵被传送到GPU的话,这个方法就很有用。也就是说,如果传输的是存储在A和B中的整个矩阵,那么lda和ldb应该相等,且等于M。如果传输的是子矩阵,lda和ldb的值应该是全矩阵的行长度。lda和ldb应该总是大于或等于行数。
如果给定一个主机端列优先的稠密二维矩阵A,其元素是单精度浮点类型,矩阵大小为M×N,则使用cublasSetMatrix来传输矩阵:cublasSetMatrix(M,N,sizeof(float),A,M,dA,M);我们还可以使用cublasSetVector来将矩阵A中的单个列传给设备端的向量dV:cublasStatus_t cublasSetVector(int n,int elemSize,const void *x,int incx,void *y,int incy);x是主机端的源位置,y是设备端的目标位置,n是要传输的元素数量,elemSize是以字节为单位的每个元素的大小,incx/incy是传输元素之间的地址间隔。使用下列命令将长度为M行优先的矩阵A的某一列传给向量dV:cublasSetVector(M,sizeof(float),A,1,dV,1);我们也可以使用cublasSetVector将矩阵A的某一行传给设备上的向量dV:cublasSetVector(N,sizeof(float),A,M,dV,1);这个函数可以跳过M个元素将A中的N个元素复制给向量dV。由于矩阵A是一个列优先的矩阵,这个命令可以将矩阵A的第一行复制给设备端。
总之,这是一个比cuSPARSE展示的简单得多的数据模型。除非应用程序对稀疏的数据结果需求较大,否则利用cuBLAS在提升性能的同时,也能提高开发效率。
cuBLAS 功 能 示 范
简单的cuBLAS示范
GPU比优化的主机端BLAS库的计算速度要快15倍以上,用cuBLAS进行开发的工作量仅略微大于传统的BLAS的实现。使用cuBLAS比较简单,它包含以下步骤:
1.用cublasCreateHandle创建一个cuBLAS句柄;
2.使用cudaMalloc可以分配用于输入输出的设备内存;
3.使用cublasSetVector和cublasSetMatrix向分配好的设备内存填充输入数据;
4.调用cublasSgemv库来让GPU执行矩阵向量乘法操作;
5.使用cublasGetVector从设备内存中取回结果;
6.使用cudaFree和cublasDestroy来释放CUDA和cuBLAS资源。
//代码片段
// Create the cuBLAS handle
cublasCreate(&handle);
// Allocate device memory
cudaMalloc((void **)&dA, sizeof(float) * M * N);
cudaMalloc((void **)&dX, sizeof(float) * N);
cudaMalloc((void **)&dY, sizeof(float) * M);
// Transfer inputs to the device
cublasSetVector(N, sizeof(float), X, 1, dX, 1);
cublasSetVector(M, sizeof(float), Y, 1, dY, 1);
cublasSetMatrix(M, N, sizeof(float), A, M, dA, M);
// Execute the matrix-vector multiplication
cublasSgemv(handle, CUBLAS_OP_N, M, N, &alpha, dA, M, dX, 1,
&beta, dY, 1);
// Retrieve the output vector from the device
cublasGetVector(M, sizeof(float), dY, 1, Y, 1);
BLAS库的程序移植
将BLAS库中C语言实现的传统应用程序移植到cuBLAS也是很简单的。移植过程主要包括4个步骤:
1.为任何输入输出向量或矩阵的应用程序添加设备内存分配调用(cudaMalloc)和设备内存释放调用(cudaFree);
2.在主机和设备之间添加输入输出向量或矩阵状态的方法(如cublasSetVector,cublasSetMatrix,cublasGetVector,cublasGetMatrix)。
3.将实际对BLAS库的调用转换为调用相应的cuBLAS库,这可能需要对传入的参数进行细微的改变。前面的示例使用的是以下cuBLAS函数:cublasStatus_t cublasSetVector(int n,int elemSize,const void *x,int incx,void *y,int incy);等价的BLAS命令是:void cblas_sgemv(const CBLAS_ORDER order,const CBLAS_TRANSPOSE TransA,const MKL_INT M,const MKL_INT N,const float alpha,const float *A,const MKL_INT lda,const float *X,const MKL_INT incX,const float beta,float *Y,const MKL_INT incY);两个命令有许多参数是相同或相似的,BLAS包含的是有序参数(使输入可以使行优先也可以使列优先),同时,cuBLAS添加了cuBLAS句柄。还要注意,BLAS中的alpha和beta参数并不像cuBLAS中那样以引用的形式进行传递。这些都是细微的差别,这并不是移植BLAS应用程序到cuBLAS中的主要障碍。
4.最后,我们也可以在程序移植成功后优化新的cuBLAS程序,这个步骤可能包括:
a.对于每次的cuBLAS调用,复制内存分配空间,而不是重复进行内存分配和释放;
b.对于矩阵和向量,除去设备到主机之间拷贝的冗余数据,这些冗余数据就是下一次cuBLAS调用时复用的输入数据;
c.使用cublasSetStream添加基于流的执行,以实现异步传输。
cuBLAS 发 展 中 的 重 要 主 题
如果我们常用的是行优先的编程语言,用cuBLAS进行开发可能需要多关注细节。使用最熟悉的编程模式会比较容易,例如,使用行优先的索引来压缩一个数组。为了方便起见,我们可以定义宏来自动实现以0为基准的行优先索引到列优先索引的转换:#define R2C(r,c,nrows) ((c) * (nrows) + (r)),但是即使使用这样的宏,也需要更多考虑循环次序问题。许多C/C++程序员倾向于使用以下命令:
for(int r = 0; r < nrows; r++){
for(int c = 0; c < ncols; c++){
A[R2C(r,c,nrows)] = ...
}
}
虽然这段代码是正确的,但不是最优的,因为他没有线性扫描数组A中的内存位置。例如,如果数组A从内存为0的位置开始,这个循环完成的前三个引用将位于0,nrows和2*nrows这三个位置。鉴于nrows可能非常大,所以以很大间隔分隔开的内存访问可能会导致很差的缓存局部性。因此,当使用列优先的数组时,必须将循环倒置:
for(int c = 0; c < ncols; c++){
for(int r = 0; r < nrows; r++){
A[R2C(r,c,nrows)] = ...
}
}
这样做时要小心,因为可能会无意中导致分配空间的右侧有较差的缓存局部性。cuBLAS最吸引人的地方是从传统BLAS库转换后的易用性。在这种情况下,唯一的主要变化是设备内存管理和CUDA调用转移的增加。

















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









