










前言
本篇主要讲解常用的几个窗口函数,以及如何自定义函数
常用的普通函数,比如
类型转换 cast(field as type) 将某列值(字符串)转换为某个类型 比如double
例:cast('10' as int)
或者 to_unix_timestamp(field,'yyyy-MM-dd') 将某列值(字符串)转换为timestamp 单位为s
slect to_unix_timestamp('2020-08-08','yyyy-MM-dd');
+-------------+
| _c0 |
+-------------+
| 1596844800 |
+-------------+
或者日期格式化函数date_format 这些 普通的函数,忘记的时候可以百度查一下api或者去spark sql文档中去找一找,参照一下demo就可以使用了

介绍
而窗口函数在实际应用中也比较广泛(据说强如clickhouse之后的计划中也要支持窗口函数了)
窗口函数,在进行分组聚合以后 , 我们还想操作集合以前的数据 使用到窗口函数
可以这么理解,在列记录的后面安装了一双眼睛或者一个窗口来监视指定范围内的行 主要是over 这个参数
over()括号内可以指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
常见的窗口函数有:
1)普通聚合 加 over() 比如 sum(field) over()
2)编号函数 加over() 比如rank() over() 、 dense_rank() over() 、 row_number() over
3) 其他函数 加over()
lag、lead、first_value、last_value
下面对几个函数加以阐述实践
普通聚合加over()
光只有sum(field)的话我们知道是对某个字段进行聚合求和,一般是在对数据进行事实分组之后 ,sum某列
那么结合着over 加窗口之后如何使用呢
先来看看窗口范围指定:over
起始行 unbounded preceding
当前行 current row
前n行 n preceding
后n行 n following
结束行 unbounded following
例:有数据
id,dt,score
"guid01,2020-01-20,3", "guid01,2020-01-20,9", "guid02,2020-01-20,1", "guid03,2020-01-20,1", "guid01,2020-01-20,7", "guid01,2020-01-20,109"spark.sql( """ |select |guid,dt,score, |sum(score) over(partition by guid order by score desc rows between unbounded preceding and current row) as flag |from |tb_login |""".stripMargin).show()窗口函数 按照 guid分区,我们就举guid03这个例子来说
按照guid分区,并按照分数降序排序
窗口的范围是起始行到当前行
guid01,2020-01-20,3
guid01,2020-01-20,7
guid01,2020-01-20,9
guid01,2020-01-20,109
sum(score)求分数的和,范围时起始行到当前行,如果不加rows between 默认是起始行到当前行
最后的结果应该是
guid01,2020-01-20,109,109
guid01,2020-01-20,9,118
guid01,2020-01-20,7,125
guid01,2020-01-20,3,128
执行程序,查询结果


编号函数
row_number() 不会有重复,不会有并列 1 2 3 4 5
rank() 有并列,1 1 3 但没有第二名
dense_rank 有并列,有第二名 1 1 2 3 4 5
面试题:
说一下row_number,rank和dense_rank的区别
row_number:不管排名是不是有相同的,都按照顺序1,2,3…..n
rank:排名相同的名次一样,同一排名有几个,后面排名就会跳过几次,如1 2 2 2 5 6 6 8
dense_rank:排名相同的名次一样,且后面名次不跳跃 如 1 2 2 2 3 4 4 5
举例说明:
uid,score
"guid01,98", "guid02,98", "guid03,99", "guid04,67", "guid05,100", "guid06,100"按照学生成绩进行排名
row_number
+------+-----+---+
| guid|score|num|
+------+-----+---+
|guid05| 100| 1|
|guid06| 100| 2|
|guid03| 99| 3|
|guid01| 98| 4|
|guid02| 98| 5|
|guid04| 67| 6|
+------+-----+---+即无论是否有并列的成绩,排名不会重复,且不会跳过,班上有58个同学,名次就有58位
rank
+------+-----+---+
| guid|score|num|
+------+-----+---+
|guid05| 100| 1|
|guid06| 100| 1|
|guid03| 99| 3|
|guid01| 98| 4|
|guid02| 98| 4|
|guid04| 67| 6|
+------+-----+---+即有重复成绩,名次也会有重复,且重复的有几个,后续排名会跳过几个
dense_rank
+------+-----+---+
| guid|score|num|
+------+-----+---+
|guid05| 100| 1|
|guid06| 100| 1|
|guid03| 99| 2|
|guid01| 98| 3|
|guid02| 98| 3|
|guid04| 67| 4|
+------+-----+---+即有重复成绩,名次也会重复,但不会跳过名次排名

其他窗口函数
first_value(field) over()
求出在同一分区内截止到当前行的第一行的值
例:
"江苏省,98", "江苏省,17", "江苏省,32", "湖北省,67", "上海市,90", "上海市,98", "上海市,89"
+------+-----+---+
| pro|score|num|
+------+-----+---+
|湖北省| 67| 67|
|上海市| 98| 98|
|上海市| 90| 98|
|上海市| 89| 98|
|江苏省| 98| 98|
|江苏省| 32| 98|
|江苏省| 17| 98|
+------+-----+---+即求出同一组内到当前行为止的范围内第一行的某个字段的值
last_value(field) over()
原理同first_value(field) over()
lag(field,n,default) over()
将上一行的某个字段下压n行,若上一行没有(即分区内第一行)则置为default默认值
例:
"江苏省,2020-08,98", "江苏省,2020-08,17", "江苏省,2020-09,32", "湖北省,2020-08,67", "上海市,2020-08,90", "上海市,2020-09,98", "上海市,2020-10,89"
+------+-------+-----+-------+
| pro| dt|score| num|
+------+-------+-----+-------+
|湖北省|2020-08| 67| null|
|上海市|2020-09| 98| null|
|上海市|2020-08| 90|2020-09|
|上海市|2020-10| 89|2020-08|
|江苏省|2020-08| 98| null|
|江苏省|2020-09| 32|2020-08|
|江苏省|2020-08| 17|2020-09|
+------+-------+-----+-------+面试真题之美团sql题
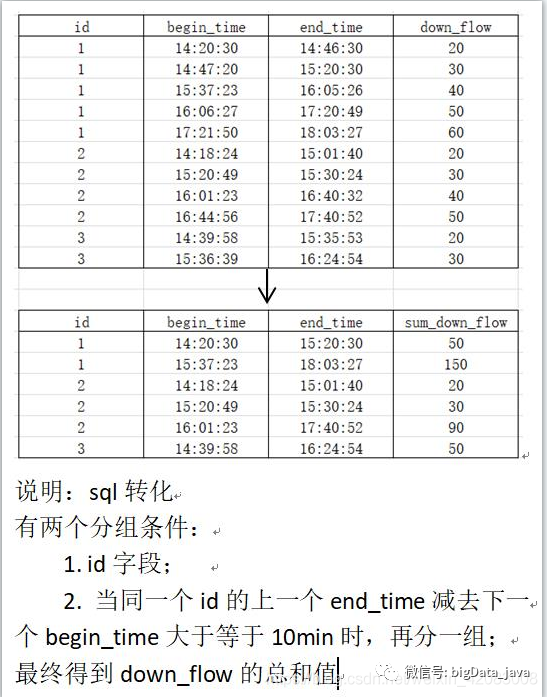
现有数据如下:
uid,start_dt,end_dt,flow
1,2020-02-18 14:20:30,2020-02-18 14:46:30,20
1,2020-02-18 14:47:20,2020-02-18 15:20:30,30
1,2020-02-18 15:37:23,2020-02-18 16:05:26,40
1,2020-02-18 16:06:27,2020-02-18 17:20:49,50
1,2020-02-18 17:21:50,2020-02-18 18:03:27,60
2,2020-02-18 14:18:24,2020-02-18 15:01:40,20
2,2020-02-18 15:20:49,2020-02-18 15:30:24,30
2,2020-02-18 16:01:23,2020-02-18 16:40:32,40
2,2020-02-18 16:44:56,2020-02-18 17:40:52,50
3,2020-02-18 14:39:58,2020-02-18 15:35:53,20
3,2020-02-18 15:36:39,2020-02-18 15:24:54,30
要求如下图:
sql实现:
spark.sql("""||select| uid,| min(start_dt) as start_dt,| max(end_dt) as end_dt,| sum(flow) as flow|from|(|select|uid,|start_dt,|end_dt,|sum(lag_num) over(partition by uid order by start_dt)as flag,|flow|from|(|select|uid,|start_dt,|end_dt,|if((to_unix_timestamp(start_dt)-to_unix_timestamp(lag_time))/60>10,1,0) as lag_num,|flow|from|(|select|uid,|start_dt,|end_dt,|flow,|lag(end_dt,1,start_dt) over(partition by uid order by start_dt) as lag_time|from v_flow|)t1 )t2 )t3 group by uid,flag|""".stripMargin).show()lead(field,n,default) over()
将上一行的某个字段上提n行,若上一行没有(即分区内第一行)则置为default默认值,原理同lag


自定义函数
hive中分为三大函数,UDF、UDAF、UDTF三种
面试题:
UDTF UDAF UDF 有什么区别?
UDF操作单个数据行 ,返回一个数据行作为输出 返回对应值 1对1
UDAF 接受多个输入数据行,会产生一个数据行并输出 比如 count或者sum这样的聚合函数 返回聚合值 多对1
UDTF 操作单个数据行,返回多个数据行 返回拆分值 1对多 比如lateral view explode()
这里我只举例自定义聚合函数UDAF,UDTF一般很少用到
package cn.project import java.io.{ByteArrayOutputStream, DataOutput, DataOutputStream} import org.apache.spark.sql.{Encoder, Encoders} import org.apache.spark.sql.expressions.{Aggregator, UserDefinedAggregateFunction} import org.roaringbitmap.RoaringBitmap import utils.RrBitMapUtils /** * @author:tom * @Date:Created in 23:23 2021/1/17 */ object AggUserFlow extends Aggregator[Array[Byte], Array[Byte], Array[Byte]] { //初始值 override def zero = { val bitmap = new RoaringBitmap() val out = new ByteArrayOutputStream() val output = new DataOutputStream(out) bitmap.serialize(output) out.toByteArray } //局部聚合逻辑 override def reduce(b: Array[Byte], a: Array[Byte]): Array[Byte] = { val inputRrBytes = b val bufferRrBytes = a // 反序列化 val inputRr = RrBitMapUtils.de(inputRrBytes) val bufferRr = RrBitMapUtils.de(bufferRrBytes) // 或操作 bufferRr.or(inputRr) RrBitMapUtils.ser(bufferRr) } //全局汇聚聚合逻辑 override def merge(b1: Array[Byte], b2: Array[Byte]): Array[Byte] = { reduce(b1, b2) } //最终输出 override def finish(reduction: Array[Byte]): Array[Byte] = { reduction } //中间缓存的Encoder override def bufferEncoder: Encoder[Array[Byte]] = { Encoders.BINARY } //最终输出的Encoder override def outputEncoder: Encoder[Array[Byte]] = { Encoders.BINARY } }
要是用的时候,进行一下注册:
spark.udf.register("rrbm_agr_or", udaf(AggUserFlow))更多学习、面试资料尽在微信公众号:Hadoop大数据开发















 1148
1148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









