







几种网络模型的演进
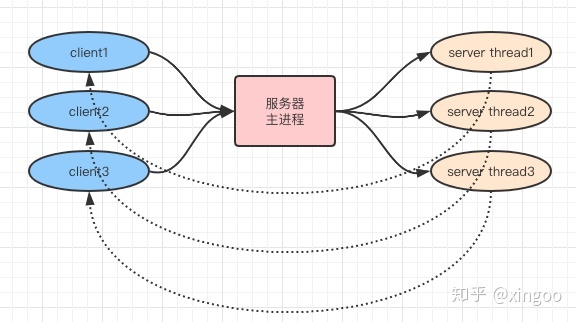
BIO,blocking IO,阻塞IO,服务器端接收到请求后,为该请求新建一个线程提供服务,当提供服务时,如果发现存在IO操作,需要等待IO完成再执行业务响应。缺点是线程等待时间过长,一般会在服务器端启动线程池来提供服务,一方面线程资源可以进行复用,另一方面避免线程无限膨胀压垮服务器。
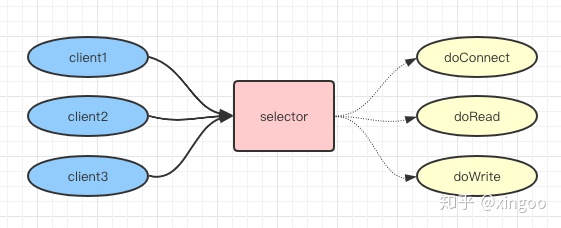
NIO,non-blocking IO,非阻塞IO,服务器端采用事件模型接收请求,比如在执行某个连接操作时,可以同时执行其他的读写操作。优点是通过一个服务端线程可以同时处理多个客户端的响应。
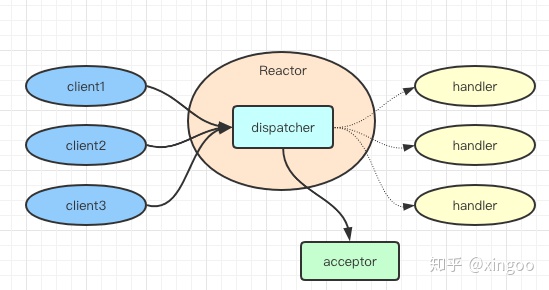
Reactor则以更优雅的模型设计实现了NIO,在Reactor中,一般会有几种角色:Reactor用于处理事件分发,Acceptor用于注册感兴趣的事件,Handler用于执行读写任务。一般为了加快事件响应的速度,会采用线程池来进行事件的分发。
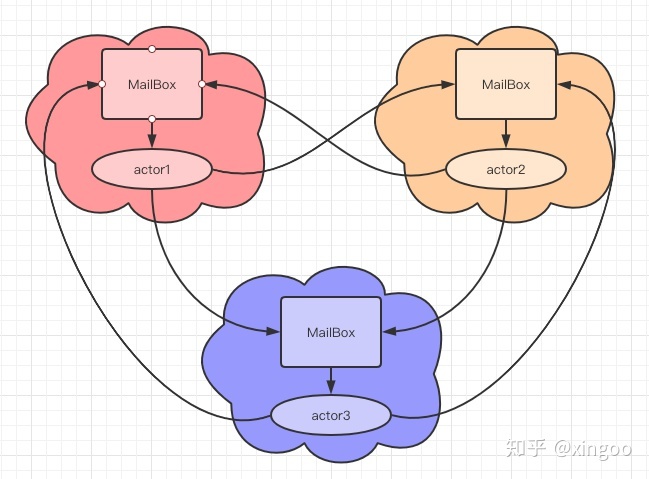
在Actor模型中每个Actor是一个基本的单元,即可作为消息的发送方也可以作为接收方。Actor之间彼此独立,互不影响。从模型上每个Actor都有一个MailBox,用于接收其他Actor发送过来的消息。
基本概念
Spark在2.0之前的版本是基于Akka做的通信,由于akka的版本经常与用户的业务代码中的akka冲突,因此在2.0之后基于netty自己实现了一套RPC框架。但是整体的设计还是保留了Akka的风格,采用RpcEndpoint模拟Actor, RpcEndpointRef模拟ActorRef, RpcEnv模拟ActorSystem。
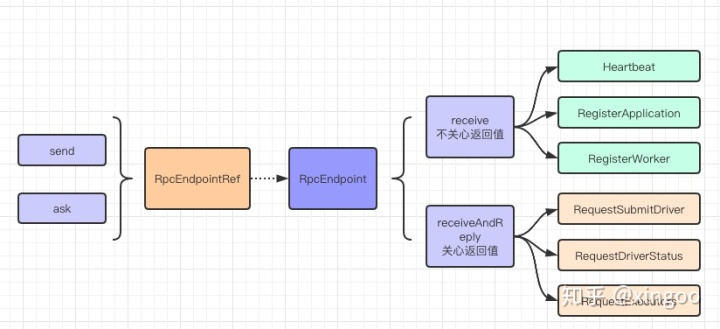
先来看看RpcEndpoint和RpcEndPointRef这两个基本的组件,其中RpcEndpointRef是RpcEndpoint的客户端,说是客户端其实就是包含了对应Endpoint的访问地址而已。Ref有两个主要的方法,send和ask;Endpoint在实现时一般会有receive和receiveAndReply两个实现。以Master为例,receive中包含了大部分状态更新和心跳的消息,receiveAndReply中包含提交应用、请求Executor等消息的处理。
再来看一下Spark通信中的基本组件:
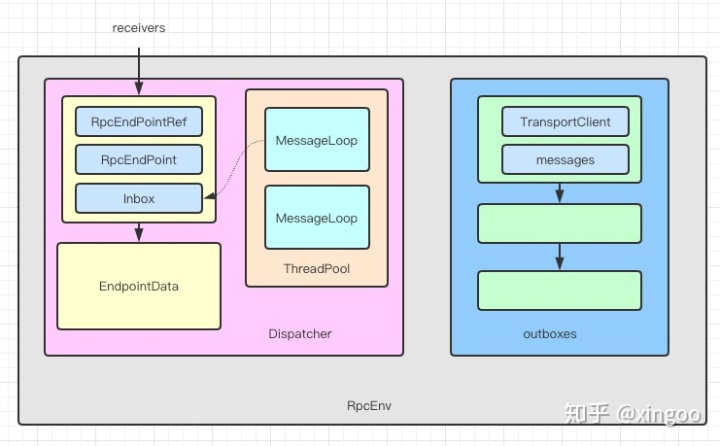
简单描述下他们的作用: - RpcEnv,RPC通信的基础,内部包含作为服务端和接收消息组件以及作为客户端发送消息的组件。每个单独的进程会创建一个RpcEnv,目前2.x+的版本都是NettyRpcEnv。 - Dispatcher,用于服务端接收分发消息。内部使用receivers数组缓存接收到的消息,并用线程池轮训处理。 - outboxes,向外发送消息,内部根据不同的endpointref组织到不同的outbox中,即同一接收者的消息会一起存放在相同的outbox中。
Spark服务端
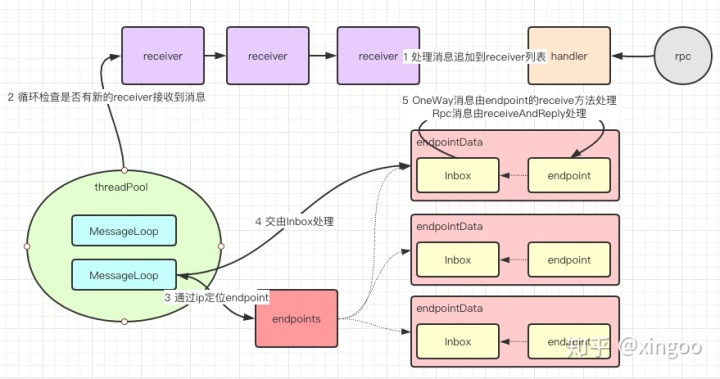
首先消息的入口通过handler处理,统一追加到receiver接收链表中,receiver接收者包含了对应的endpoint以及一个Inbox用于接收消息。Dispatcher内部会创建一个线程池,用于扫描这个链表,并调用对应的Inbox处理方法,Inbox会根据消息的类型使用对应endpoint的不同方法进行处理。
其中比较关键的技术点:
线程池的相关配置:线程池大小默认为max(2, Runtime.getRuntime.availableProcessors())。 消息的类型与处理:OneWayMessage会使用endpoint的receive方法响应,RpcMessage会使用endpoint的receiveAndReply方法响应。
Spark客户端
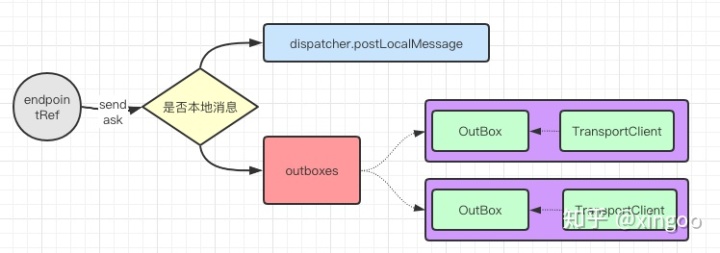
发送消息时,用户会获取到对应的endpointRef,调用send方法可以实现不关心返回值的请求,调用ask实现关心返回值的请求。如果发送的目标就是本机,可以直接调用dispatcher进行内部消息的转发;如果发送的目标是远程主机,则会从Outboxes Map中获取目标主机对应的outbox,outbox内部维护了当前主机到目标主机的连接客户端,基于该客户端发送消息。














 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









