







P389: RISC(Reduced) 和 CISC(Complex)的细节对比
(文中提到,两者的区别已经逐渐模糊。RISC发展至今也有数百指令,其中也有多周期指令。而CISC也借鉴了RISC的优势,也可使用pipeline structure。)
ARM中的R指的就是RISC。Advanced RISC machine.
在引入pipeline之前,each hardware unit is only active for a fraction of the total clock cycle.
流水线的问题:
1.各环节的处理时间应当相近(可能有瓶颈);

比如上图,A、B、C环节的处理时间不相近,只有B环节能满载运转,A、C都有空档。理想情况是进一步分割B环节。然而,some of the hardware units in a processor, such as the ALU and the memories, cannot be subdivided into multiple units with shorter delay. This makes it difficult to create a set of balanced stages.
2.每个顾客/工件应该乐意接受一样的流程。
这要求每条指令的处理过程是类似的,即不会有一些只需要一个环节就能完成的指令(如果有的话,这些简单指令将做无意义的排队)。我想,early RISC的提出就是因为这个,让每条指令的处理过程尽可能一样。
3.逻辑依赖问题(下一条指令的输入是上一条指令的输出(数据依赖),或者控制依赖(条件跳转))。此问题可能导致执行结果错误,因为指令拿到的输入可能不是最新数据。
为了同时处理更多的指令,pipeline depth(也就是流水线的级数)应该要更大。
我的理解是throughput取决于第一个环节的长度,而各个环节的长度都与第一个环节的长度相近。如果想最大化throughput,那就应该尽可能缩短各环节的长度,自然就要有更多的级数。
更多的级数会导致更长的延迟,因为每个环节过后都需要将结果暂存到寄存器,这一动作会有延迟。
这是throughput和latency的trade-off。
分支预测的策略,always-taken,never-taken,backward-taken-forward-not-taken(因为backward通常是循环,所以真实taken的几率较大)
除了conditional jmp需要预测,ret也需要预测。一般来说,ret的预测成功率很高,可以借助hardware stack快速获取之前call的下一条指令的位置(相应地,每次调用call都会将call的下一条指令的地址加入hardware stack)。但call和return不匹配时就会预测错误。
stall解决pipeline的第三个问题(即data hazard问题):
When the addq instruction is in the decode stage, the pipeline control logic detects that at least one of the instructions in the execute, memory, or write-back stage will update either register %rdx or register %rax. Rather than letting the addq instruction pass through the stage with the incorrect results, it stalls the instruction.
foward也可以解决pipeline的第三个问题(data hazard):
通过额外的硬件连接,可以提前把之前的结果拿来用(如下图,虽然结果还没有进入Writeback阶段,但已经可以取出来。)

ret的处理:

load/use hazard的解决:

分支预测错误时的解决:

用CPI来衡量PIPE的性能(评估设计的好坏)
上面提到了三种需要插入bubble的处理,We can measure this inefficiency by determining how often a bubble gets injected into the pipeline, since these cause unused pipeline cycles. A return instruction generates three bubbles, a load/use hazard generates one, and a mispredicted branch generates two. We can quantify the effect these penalties have on the overall performance by computing an estimate of the average number of clock cycles PIPE would require per instruction it executes, a measure known as the CPI (for “cycles per instruction”).
忽略开头的数个时钟周期,W阶段每个周期都会执行,可以认为每个周期都会完成一条指令。但因为bubble的存在,CPI会略超过1。
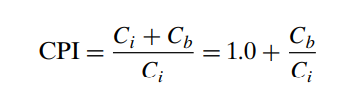
都说集成电路产业有三个环节,设计、制造、封装。我想,这一章讲的就是最基本的设计。设计对于最终的性能来说太重要了。
关于异常处理:
Handling exceptions correctly is a challenging aspect of any microprocessor design. They can
occur at unpredictable times, and they require creating a clean break in the flow of instructions through the processor pipeline.
Exceptions can be generated either internally, by the executing program, or externally, by some outside signal. Our instruction set architecture (Y86-64) includes three different internally generated exceptions, caused by (1) a halt instruction, (2) an instruction with an invalid combination of instruction and function code, and (3) an attempt to access an invalid address, either for instruction fetch or data read or write.
异常处理应该考虑到的三个问题:
First, it is possible to have exceptions triggered by multiple instructions simultaneously. 处于pipeline中靠后工序的指令会被优先上报给操作系统。
A second subtlety occurs when an instruction is first fetched and begins execution, causes an exception, and later is canceled due to a mispredicted branch. 这种时候exception不应该被上报。
发生异常之后,状态不应该被更新。
同时解决上述三个问题的方法:
When an exception occurs in one or more stages of a pipeline, the information is simply stored in the status fields of the pipeline registers. The event has no effect on the flow of instructions in the pipeline until an excepting instruction reaches the final pipeline stage, except to disable any updating of the programmer-visible state (the condition code register and the memory) by later instructions in the pipeline. Since instructions reach the write-back stage in the same order as they would be executed in a nonpipelined processor, we are guaranteed that the first instruction encountering an exception will arrive first in the write-back stage, at which point program execution can stop and the status code in pipeline register W can be recorded as the program status. If some instruction is fetched but later canceled, any exception status information about the instruction gets canceled as well. No instruction following one that causes an exception can alter the programmer-visible state. The simple rule of carrying the exception status together with all other information about an instruction through the pipeline provides a simple and reliable mechanism for handling exceptions.
教科书模型(不管是本书的Y86-64还是我曾学的MIPS)跟实际的两方面差距:
浮点运算、整数的乘除的Execution不能在1 cycle内解决。除法尤其慢(可能需要数十个cycle)。pipeline如果只有一条,整体效率就会被这些多周期指令严重拖累。因此,实际的CPU都有用于应付多周期指令的额外硬件。
Better performance can be achieved by handling the more complex operations with special hardware functional units that operate independently of the main pipeline. Typically, there is one functional unit for performing integer multiplication and division, and another for performing floating-point operations. As an instruction enters the decode stage, it can be issued to the special unit. While the
unit performs the operation, the pipeline continues processing other instructions. Typically, the floating-point unit is itself pipelined, and thus multiple operations can execute concurrently in the main pipeline and in the different units.
系统与系统之间也要保持同步,具体的手段还是stall、forward。
Memory环节其实也未必能在1 cycle内解决。Another type of cache memory, known as a translation look-aside buffer, or TLB, provides a fast translation from virtual to physical addresses. Using a combination of TLBs and caches, it is indeed possible to read instructions and read or write data in a single clock cycle most of the time.
From the perspective of the processor, the combination of stalling to handle short-duration cache misses and exception handling to handle long-duration page faults takes care of any unpredictability in memory access times due to the structure of the memory hierarchy.














 2118
2118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









