







前言:该论文来自于华南理工大学的研究者发表于interspeech2021上,作者首次将GIN网络用于实现SER,得到比以往的网络更好的性能。
一、基础信息
作者:Jiawang Liu , Haoxiang Wang
单位: 华南理工大学,计算机科学与工程学院
语料库: IEMOCAP
特征:低水平特征集(The LLDs feature set)
使用的模型:LSTM-GIN(Long Short-Term Memory,Graph Isomorphism Network, 长短期记忆网络-图同构网络)
评价指标:未加权准确率,加权准确率
二、作者的贡献
To the best of our knowledge, this is the first try of using spatial-based GCN for SER. The SER task is turned into a graph classification problem by transforming an utterance into a graph, in which nodes are represented by frame-level features and connections are defined according to temporal relations between frames.
We compare the proposed LSTM-GIN model with different implementations using both spatial-based GCNs and spectral-based GCNs. Experimental results reveal that spatial-based GCNs, especially GIN, can conduct very competitive accuracy in SER task.
Our proposed LSTM-GIN model achieves 64.65% of WA and 65.53% of UA on the IEMOCAP dataset, which surpasses other state-of-the-art SER models.
(1)第一次将基于空间的GCN(graph convolutional network)网络用于SER;
(2)将提出的 LSTM-GIN 模型与使用基于空间的 GCN 和基于光谱的 GCN 的不同实现进行较。 实验结果表明,基于空间的 GCN,尤其是 GIN,可以在 SER 任务中进行非常有竞争力的准性。
(3)所提的LSTM-GIN 方法的取得的识别流分别为;WA:64.65%;UA: 65.53%,识别率超过其他最好的SER模型。
三. 实验过程
3.1 特征提取
The LLDs feature set contains PCM loudness, F0 Envelope, LSP Frequency, Melfrequency cepstral coefficients (MFCCs), jitter, etc. Every five frames are averagely down-sampled into one to decrease the complexity of computation. Finally, we get a feature size of 120 × 78 with longer utterances are cut and shorter ones are padded with zeros.
通过openSMILE工具包提取到120 × 78的特征,对于长的进行剪切,不足的进行补零操作, 且通过对每五帧进行了求平均,来减小计算的复杂度。
We use the bidirectional LSTM as the deep features extraction block given the excellent capacity of long-range dynamic dependencies modeling. 128 memory cells are included in each direction to encodes the left and right sequence contexts
鉴于长期动态依赖建模的出色能力,我们使用双向 LSTM 作为深度特征提取块。 每个方向包含 128 个记忆单元,用于对左右序列上下文进行编码。
Then GIN is used to further integrate global emotional information.
然后再用GIN来实现全局情感信息的整合。
3.2 对比的模型
(1)在 IEMOCAP 数据集上与基于图的方法进行比较。
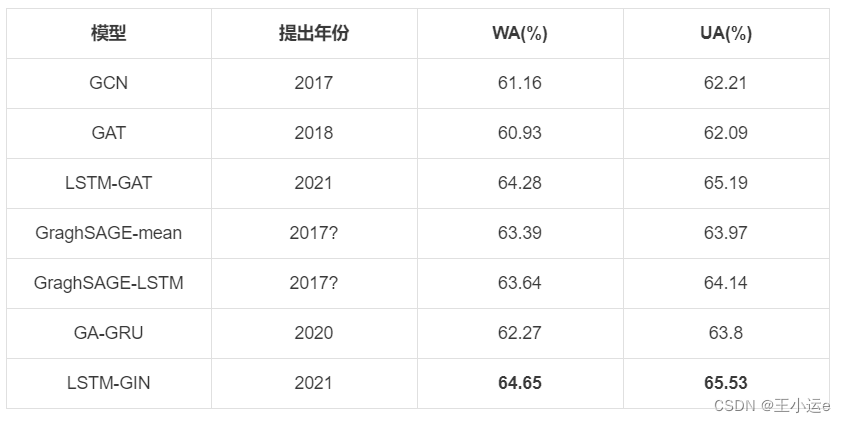
(2)在IEMOCAP语料库上与深度学习方法的比较
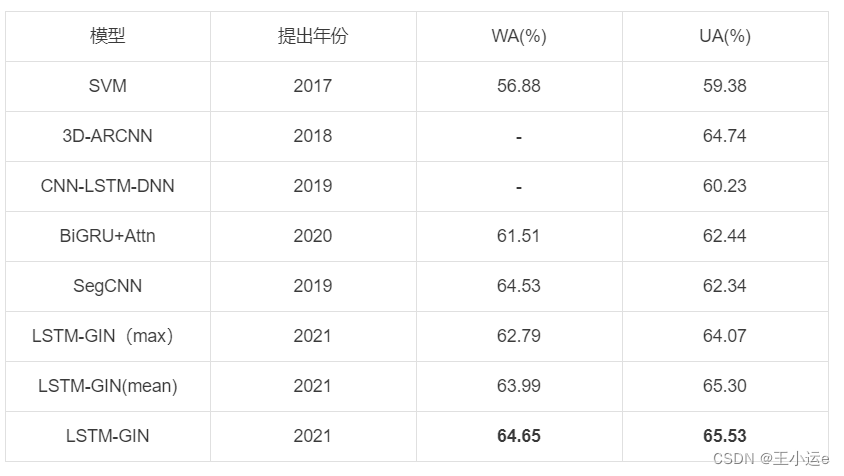
四、结果
The proposed LSTM-GIN model achieves 64.65% of WA and 65.53% of UA on the IEMOCAP dataset, which surpasses other graph-based GCN models and common deep neural networks such as CNN and LSTM
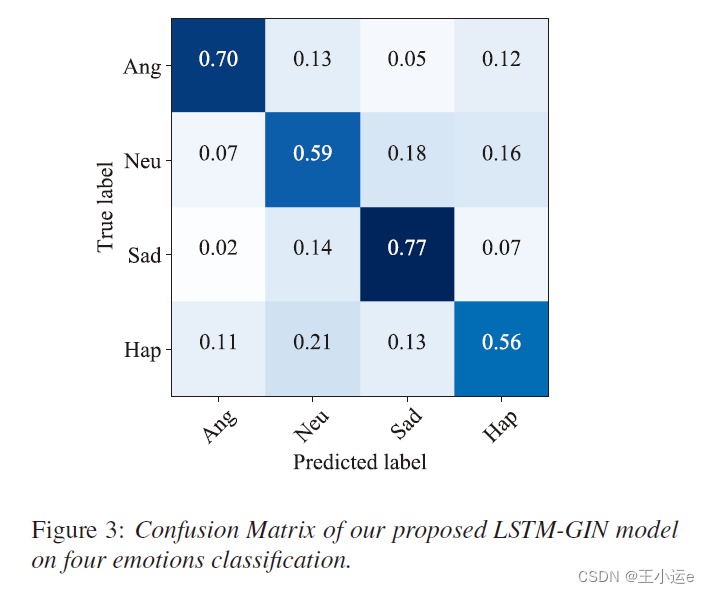
知识点:
一:LLDs特征和HSFs特征
(1)LLDs(low level descriptors)LLDs指的是手工设计的一些低水平特征,一般是在一帧语音上进行的计算,是用来表示一帧语音的特征。
(2)HSFs(high level statistics functions)是在LLDs的基础上做一些统计而得到的特征,比如均值,最大值等等。HSFs是对utterance上的多帧语音做统计,所以是用来表示一个utterance的特征。
参考博客:论文笔记:语音情感识别(五)语音特征集之eGeMAPS,ComParE,09IS,BoAW
二、GIN网络
参考博客:Graph Isomorphism Network















 6781
6781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









