







文章目录
Dynamic Programming(DP)指一组可以用来计算最优策略的算法。这些算法给出了一个完整的环境模型,即 MDP。
经典DP需要假设模型是完整的(即完全可知),且计算量大,在RL实际应用中有限。DP和一般RL的关键思想:使用值函数来组织和构造对好的策略的搜索。
动态规划(DP)对复杂的问题来说,可能不具有可行性。主要原因是问题状态的数量很大,导致计算代价太大。
1、Policy Evaluation
首先,考虑任意策略
π
\pi
π的状态值函数
v
π
v_\pi
vπ的计算——Policy Evaluation / prediction problem:
对于所有的
s
∈
S
s \in S
s∈S
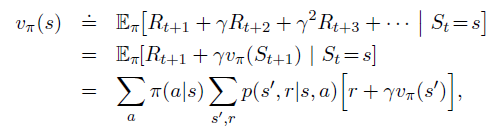
迭代求解:
- 考虑近似值函数序列: v 0 , v 1 , . . . v_0,v_1,... v0,v1,...
- 随机初始化 v 0 v_0 v0 (如果状态是终止状态,v=0)
- 使用贝尔曼方程逐次逼近
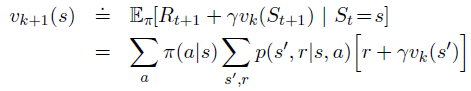
算法:

2、Policy Improvement
计算
V
(
s
)
V(s)
V(s)是为了找到更好的策略
π
\pi
π。
假设对于任意确定性策略
π
\pi
π,有确定性的值函数
v
π
v_\pi
vπ。
对于一些状态s,我们想知道 是否应该改变策略以确定性地选择一个动作
a
≠
π
(
s
)
a \not = \pi(s)
a=π(s),已知
v
π
(
s
)
v_\pi(s)
vπ(s) 得到的状态s的策略是好的,但是不知道下一个新的策略是否也是好的?
解决方法:使用
q
π
(
s
,
a
)
q_\pi(s,a)
qπ(s,a)
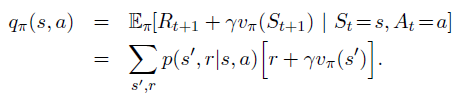
如果:
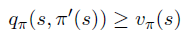
则,
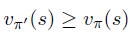
证明:

根据q值中最大的对应的动作为新的策略——greedy policy
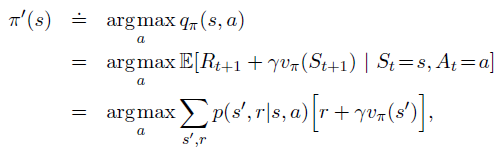
3、Policy Iteration
策略迭代:寻找最优策略的方法

算法:

策略迭代缺点:每个迭代都涉及policy evaluation 和 policy improvement,因此计算量很大。
Policy Iteration代码实现(gridworld环境)
4、Value Iteration
策略迭代的简化,仅在一次扫描之后停止policy evaluation——值迭代
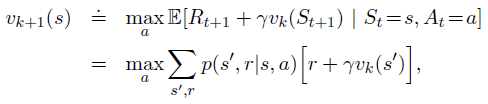
值迭代参考了贝尔曼方程:
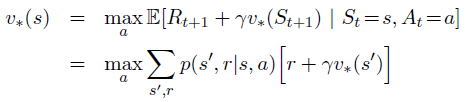
算法:

值迭代在每次扫描中有效的结合了一次 policy evaluation 和 policy improvement,收敛更加快。
5、Generalized Policy Iteration(GPI)
GPI 是一个强化学习的核心思想,影响了几乎所有的强化学习方法。
策略迭代由两个同步的、交互的过程组成:
- 一个使值函数与当前策略一致(policy evaluation)
- 一个使策略对当前值函数做贪婪(policy improvement)
















 2796
2796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









