







论文链接:https://arxiv.org/abs/1509.06461
由于深度神经网络提供了灵活的函数逼近与低渐近逼近误差的潜力,DQN 在 Atari 2600 游戏中的带来了更好的性能。但是,DQN有时也会大大高估行动的价值。使用 DQN的改进版本(Double DQN)能够产生更准确的值估计,减少 DQN 的过高估计,从而在游戏中获得更高的分数。
给定策略
π
\pi
π ,在状态 s 采用动作 a 的真实值为:
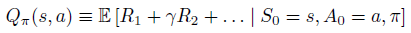
标准 Q-learning 算法的参数更新方式:
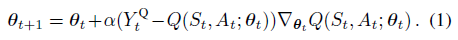
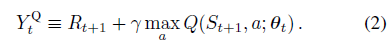
DQN 的目标Y值为:
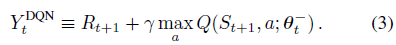
标准 Q-learning 和 DQN 的目标Y值计算中使用了 max 操作(公式2和3),其使用了相同的值来选择和估计动作。这使得它更有可能选择高估计的值,从而导致值的高估计。为了避免这种情况的发生,将选择动作和求值进行解耦。这就是 Double DQN 的核心。
Double DQN 使用行为网络选择出value最大的action,用目标网络来估计它的值。对应的,公式(2)的目标改写为:
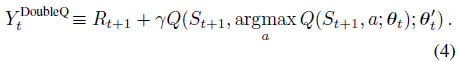
Double DQN 的算法伪代码与 DQN 一致,仅仅是目标Y的公式进行了修改:

















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









