







csrnet:用于理解高度拥挤场景的扩张卷积神经网络
针对复杂场景的拥挤场景理解我们提出了一个 CSRNet 网络,该网络主要包括两个部分,前端使用一个 卷积网络用于 2D 特征提取,后端用一个 dilated CNN。 该网络在几个常用的公开人群密度估计数据库上取得了不错的效果。
我们提出了一种用于拥塞场景识别的网络,称为CSRNet,以提供一种数据驱动的深度学习方法,该方法可以了解高度拥塞的场景并执行准确的计数估计,并提供高质量的密度图。 拟议的CSRNet由两个主要组成部分组成:卷积神经网络(CNN)作为2D特征提取的前端,而膨胀的CNN作为后端,其使用膨胀的内核传递更大的接收场并代替池化操作。 -tions。 CSRNet具有纯卷积结构,因此是易于训练的模型。 我们在四个数据集(ShanghaiTech数据集,UCFCC50数据集,WorldEXPO’10数据集和UCSD数据集)上演示了CSRNet,并提供了最新的性能。 在上海科技的PartB数据集中,CSRNet的均值绝对误差(MAE)比以前的最新方法低47.3%。 我们扩展了针对其他对象的目标应用程序,例如TRANCOS数据集中的车辆。结果表明,CSRNet与以前的最新方法相比,MAE降低了15.4%,从而显着提高了输出质量。
1. Introduction
已开发出越来越多的网络模型[1、2、3、4、5],以提供有希望的解决方案,以进行人群监控,装配控制和其他安全服务。 当前的拥挤场景分析方法已从简单的人群计数(在目标图像中输出人数)发展到密度图预显示(显示人群分布的特征)[6]。 由于相同数量的人可能具有完全不同的人群分布(如图1所示),因此这种发展遵循了实际应用的需求,因此仅计算人群数量是不够的。 分布图可帮助我们获取更多准确而全面的信息,这对于在踩踏和骚乱等高风险环境中做出正确的决定可能至关重要。然而,产生精确的分布模式是一项挑战。其中困难之一来自预测方式:因为生成的密度值遵循逐像素预测,所以输出密度图必须包括空间相干性,以便它们能够呈现最近像素之间的平滑过渡。此外,多种多样的场景,例如不规则的人群遮挡和不同的摄像机视角,将使任务变得困难,特别是对于使用没有深层神经网络的传统方法。拥塞场景分析的最近发展依赖于基于DNN的方法,因为它们在语义分割任务[7、8、9、10、11]中实现了高精度,并且它们在视觉显著性[12]中取得了显著进展。。使用域名的额外好处来自热情的硬件社区,在那里,域名可以在通用处理器[13、FPGA[14、15、16和ASICs [17上快速调查和实施。其中,低功耗、小尺寸方案特别适合部署拥挤的场景分析确保监控设备。
3.1 CSRNet architecture
遵循[19,4,5]中类似的想法,我们选择VGG-16 [21]作为CSRNet的前端,因为它具有强大的传递学习能力和灵活的体系结构,可以轻松地将后端连接起来以生成密度图。在CrowdNet [19]中,作者直接从VGG-16雕刻前13层,并添加1×1卷积层作为输出层。缺少修改会导致非常弱的性能。其他体系结构,例如[4],在将输入图像发送到MCNN的最合适列之前,使用VGG-16作为密度级别分类器来标记输入图像,而CP-CNN [5]将分类结果与功能结合在一起来自密度图生成器。在这些情况下,VGG-16可以用作辅助设备,而不会显着提高最终精度。在本文中,我们首先删除VGG-16的分类部分(全连接层),然后在VGG-16中构建带有卷积层的拟议CSRNet。该前端网络的输出大小是原始输入大小的1/8。如果我们继续堆叠更多的卷积层和池化层(VGG-16中的基本组件),则输出大小将进一步缩小,并且很难生成高质量的密度图。在文献[10,11,40]的启发下,我们尝试将扩展卷积层作为后端,以提取更深层的显著性信息,并主要保持输出分辨率。
3.1.1 Dilated convolution
我们设计的关键组件之一是相关卷积层。二维扩张卷积可定义为:
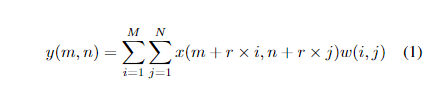
y(m,n)是输入x(m,n)和滤波器(i,j)的扩展卷积的输出,其长度和宽度是随机的。参数决定扩张率。如果r=1,则扩张卷积变为正常卷积。
扩张的卷积层已经被证明可以有效地提高分割精度[10,11,40],它是池化层的一个很好的选择。尽管池化层(例如最大池化和平均池化)被广泛用于维护不变性和控制过度拟合,但它们也显着降低了空间分辨率,这意味着要素地图的空间信息会丢失。去卷积层[41、42]可以减轻信息的损失,但是额外的复杂性和执行延迟可能并不适合所有情况。扩张卷积是一个更好的选择,它使用稀疏内核(如图3所示)来交替池化和卷积层。该特征在不增加参数数量或计算量的情况下扩大了接收场(例如,增加更多的卷积层可以使更大的接收场但引入更多的操作)。扩张卷积,具有k×kfilter的小核通过扩张式跨步放大为tok +(k-1)(r-1)。因此,它允许灵活地聚合多尺度上下文信息,同时保持相同的分辨率。可以在图3中找到示例,其中正常卷积得到3×3的接收场,而两个膨胀的卷积分别提供5×5和7×7的接收场。
为了保持特征图的分辨率,与使用卷积+池化+反卷积的方案相比,扩张式卷积显示出明显的优势。我们在图4中选择一个例子来说明。输入是一个群体的图像,通过两种方法分别处理,生成具有相同大小的输出。在第一种方法中,输入由具有因子2的最大池化层进行下采样,然后将其传递到a3×3Sobel内核的卷积层。由于生成的特征图仅是原始输入的1/2,因此需要通过反卷积层(双线性插值)对其进行上采样。(??)在另一种方法中,我们尝试膨胀卷积,并将相同的3×3 Sobel核与因子= 2步幅的膨胀核相适应。输出与输入共享相同的尺寸(意味着不需要池化和反卷积层)。最重要的是,dilated卷积的输出包含更详细的信息(指的是我们放大的部分)。
3.1.2 Network Configuration
我们在表3中提出了CSRNet的四种网络配置,它们的前端结构相同,但后端的扩张速率不同。在前端方面,我们采用了VGG-16网络[21](全连接层除外),并且仅使用3×3内核。根据[21],当以相同大小的接收场为目标时,使用更多具有小核的卷积层比使用较少具有大核的层更有效。

表3.CSRNET的配置。所有卷积层都使用填充来保持先前的大小。卷积层的参数表示为“conv-(核大小)-(滤波器数 目)-(膨胀率)”,最大池层在2×2pixel窗口上进行,步长为2。
通过删除完全连接的层,我们尝试确定VGG-16中需要使用的层数。最关键的部分是在精度和资源开销(包括训练时间,内存消耗和参数数量)之间进行权衡。实验表明,将VGG-16的前十层保留三个池化层,而不是五个,可以达到最佳折衷,从而抑制了池化操作对输出精度的不利影响。由于CSRNet的输出(密度图)较小(输入大小的1/8),我们选择因子为8的双线性插值进行缩放,并确保输出与输入图像有相同的分辨率。在相同大小的情况下,使用PSNR(峰值信噪比)和SSIM(图像中的结构相似度[43]),CSR-Net生成的结果可与地面真实结果相媲美。
3.2 训练方法
在本节中,我们提供了培训的具体细节。利用常规cnn网络(无分支结构),csrnet易于实现,部署速度快。
3.2.1 Ground truth generation
按照[18]中生成密度图的方法,我们使用几何自适应核来处理高度拥挤的场景。通过使用高斯核(将其标准化为1)模糊每个头部注释,我们考虑了来自每个数据集的所有图像的空间分布,生成了地面真相。几何自适应内核定义为:
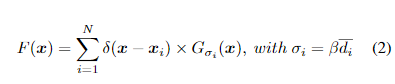
对于地面真值δ中的每个目标物体xi,我们使用di表示k个最近邻居的平均距离。为生成密度图,我们将δ(x-xi)与具有参数σi(标准差)的高斯核进行卷积,其中x为图像中像素的位置。在实验中,我们遵循[18]中的配置,其中β= 0.3,k =3。对于稀疏人群的输入,我们使高斯核适应平均头部大小以模糊所有注释。表2中显示了不同数据集的设置。
3.2.2 Data augmentation
我们从每个图像的不同位置裁剪9个补丁,大小为原始图像的1/4。前四个面片包含图像的四分之四,没有重叠,而其他五个面片则从输入图像中随机裁剪。在那之后,我们镜像补丁,这样我们就可以使训练集增加一倍了
3.2.3 Training details
我们使用一种简单的方法将CSRNet训练为端到端的结构。前十个卷积层是从训练有素的VGG-16 [21]进行微调的。对于其他层,初始值来自具有0.01标准偏差的高斯初始化。训练期间以1e-6的固定学习率应用随机梯度下降(SGD)。同样,我们选择欧几里得距离来测量地面真相和我们生成的估计密度图之间的差异,这与其他著作相似[19,18,4]。损失函数如下:
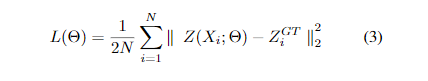
其中Nis为训练批次的大小,Z(Xi;Θ)为CSRNet生成的输出,参数显示为Θ。Xire表示输入图像,ZGT表示输入图像Xi的真实结果。
4. Experiments
我们在五个不同的公共数据集中展示了我们的方法[18,3,22,23,44]。与以前的最新方法[4,5]相比,我们的模型更小,更准确并且更易于训练和部署。在本节中,将介绍评估指标,然后对ShanghaiTech PartA数据集进行消融研究,以分析我们模型的配置(如表3所示)。在进行消融研究的同时,我们评估了我们提出的方法,并将其与所有这五个数据集中的最新技术方法进行了比较。我们模型的实现基于Caffe框架[13]。
4.1. Evaluation metrics评价指标
mae和mse用于评估,定义为
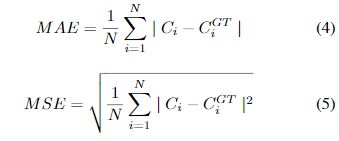
其中N是一个测试序列中的图像数量,而CGTi是计数的基本事实.Ci表示估计的计数,定义如下
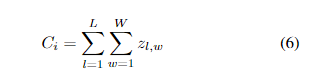
L和W分别表示密度图的长度和宽度,而zl,w是生成的密度图的(l,w)处的像素.Ci表示图像Xi的估计计数。
我们还使用PSNR和SSIM来评估ShanghaiTech PartA数据集上输出密度图的质量。要计算PSNR和SSIM,我们遵循[5]给出的预处理,其中包括密度图大小调整(与原始输入大小相同),以及地面真实性和预测密度图的插值和归一化。
4.2. Ablations on ShanghaiTech PartA
在本小节中,我们将进行消融研究,以在上海科技PartA数据集上分析CSRNet的四种配置[18],这是一个新的大规模人群计数数据集,其中包括482张拥挤场景的图像,其中有241,667位带注释者。由于场景非常拥挤,视角各异且解析度不固定,因此很难从这些图像中进行计数。这四种配置如表3所示。CSRNetA是所有扩展速率均为1的网络。
CSRNet B和D的后端分别保持2和4的扩展率,而CSRNet C组合了2和4的扩展率。这四个模型的参数数量与16.26M相同。我们打算通过使用不同的扩张率来比较结果。使用第二节中提到的方法对Shanghai PartA数据集进行训练后。3.2,我们执行在第二节中定义的评估指标。4.1。我们尝试使用dropout [45]来防止潜在的过拟合问题,但是并没有明显的改进。因此,我们不在模型中包括dropout。详细的评估结果显示在表4中,其中CSRNet实现了最低的误差(最高的准确性)。因此,我们使用CSRNet B作为拟议的CSRNet进行后续实验。
4.3. Evaluation and comparison
4.3.1 ShanghaiTech dataset
上海科技人群统计数据集共包含1198幅标注图像,共计330165人[3],该数据集由两部分组成,A部分包含482幅从互联网上随机下载的高度拥挤场景图像,B部分包含716幅从上海街头拍摄的相对稀疏人群场景图像。对本文的方法进行了评价,并与其他六篇最新的工作进行了比较,结果如表5所示。结果表明,与其他方法相比,我们的方法获得了最低的MAE(最高的准确度),并且我们得到的MAE比最先进的CP-CNN解决方案低7%。与CP-CNN相比,CSRNET的MAE也降低了47.3%。为了评估生成密度图的质量,我们使用PartA数据集将我们的方法与MCNNA和CP-CNN进行了比较,并遵循SEC中的评估指标。3.2条。测试用例的样本可以在图5中找到。结果如表6所示,表明CSRNET达到了最高的SSIM和PSNR。我们也将上海科技数据集的质量结果报告在表11中。


4.3.2 UCFCC50 dataset
UCFCC50数据集包括50幅不同透视和分辨率的图像[22]。每张图像的批注人员数从94到4543不等,平均数为1280。按照[22]中的标准设置进行5倍交叉验证。结果mae与mse比较见表7,生成的密度图质量见表11


mae和mse见表7,生成的密度图质量见表11。
















 7413
7413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









