







 本文记录了在Windows环境下,使用Anaconda、Python3.6、CUDA10.0和Pytorch1.5复现CSRNet深度学习模型的过程。详细步骤包括设置开发环境、获取和导入项目、准备ShanghaiTech数据集、处理json文件、训练和测试模型,并解决了在训练过程中遇到的问题。最后分享了模型权重文件的下载链接。
本文记录了在Windows环境下,使用Anaconda、Python3.6、CUDA10.0和Pytorch1.5复现CSRNet深度学习模型的过程。详细步骤包括设置开发环境、获取和导入项目、准备ShanghaiTech数据集、处理json文件、训练和测试模型,并解决了在训练过程中遇到的问题。最后分享了模型权重文件的下载链接。
一、开发环境
windows10+Anaconda3+Python3.6+CUDA10.0+Pytorch1.5+Pycharm
提醒:pytorch1.0版本很有可能会在训练的时候报错,所以建议使用pytorch1.5
二、论文代码
三、导入项目
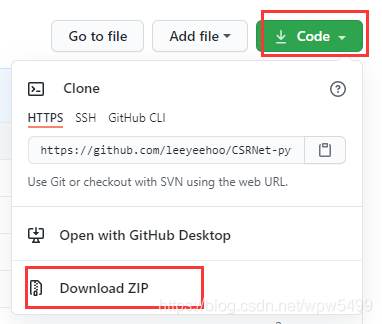
1、通过git下载或者zip网页下载,二选一
2、导入项目至pycharm
四、数据准备
1、数据集
ShanghaiTech
百度网盘:https://pan.baidu.com/s/1cC4wkHAWfJ15VKwG2qjJ6A
提取码:i0xa
2、导入数据集到项目
新建dataset目录,导入数据

3、.ipynb文件转换成.py文件
.ipynb文件,pycharm中无法正常查看和运行,故需要处理成.py文件。
操作步骤:如何使用jupyter 打开.ipynb文件参考教程
- Anaconda中的jupyter notebook打开.ipynb后缀的文件
- 把.ipynb文件中代码拷贝至项目中新建的同名的.py文件中
- 比如make_dataset.ipynb,用jupyter notebook打开,然后在项目下新建make_dataset.py,把make_dataset.ipynb中的代码拷贝到make_dataset.py
- 按照这个方法,生成make_dataset.py、val.py
- 为什么没有make_model.py?因为make_model.ipynb和model.py是等价的,直接删掉make_model.ipynb即可
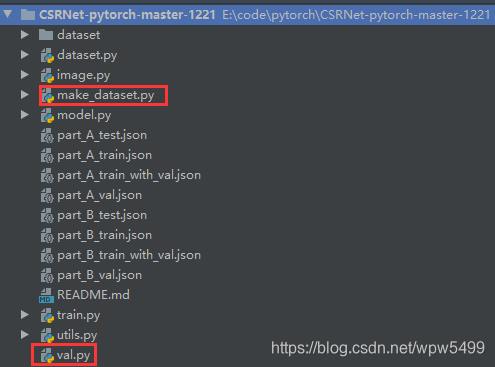
- 替换之后,目录如下
4、处理json文件
- 作者给出的json文件中包含着SHHA,SHHB两个数据集文件的路径信息
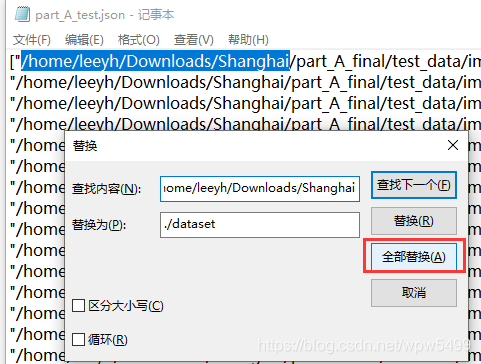
- 这里我使用最简单暴力的方法,在文件目录中使用记事本打开json文件
- 替换成自己的相对路径
- 图示如下
- 使用这种方法,把剩下的json文件都安排好
5、生成GroundTruth文件
- 这里需要用到make_dataset.py文件,修改路径为dataset

- 运行该脚本,漫长的等待之后,会在groundtruth文件夹中生成.h文件
- 这.h文件就是生成的GroundTruth密度图文件
五、训练模型
打开终端,输入命令(每解决一个问题,就重新执行一次命令)
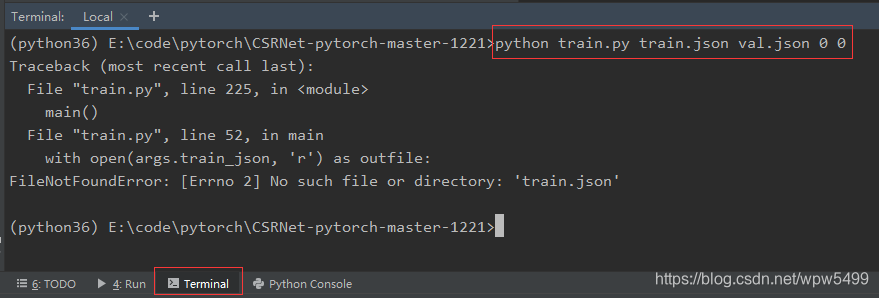
- 错误1:No such file or directory: ‘train.json’
- 解决1:确实找不到文件,因为根本就没有train.json、val.json这两个文件。这两个其实是统称。
train.json指代part_A_train.json,part_B_train.json
val.json指代part_A_train_with_val.json,part_A_val.json,part_B_train_with_val.json,part_B_val.json
对于SHHB的执行命令:python train.py part_B_train.json part_B_val.json 0 0
对于SHHA的执行命令:python train.py part_A_train.json part_A_val.json 0 0
其后跟着的第一个数字0,表示使用序号为0的GPU;第二个0表示的是线程数。 - 错误2:这里我选择SHHB的命令运行,model.py第18行报错NameError: name ‘xrange’ is not defined
- 解决2:这是新旧版本的历史遗留问题,将其改成range即可。另外下面19行,还有一个问题,需要转成list才能支持切片操作,故两边都使用list包裹。

- 错误3:image.py报错:TypeError: integer argument expected, got float。
- 解决3:需要改成双斜杠,整除。

- 成功进入到训练模型的流程。
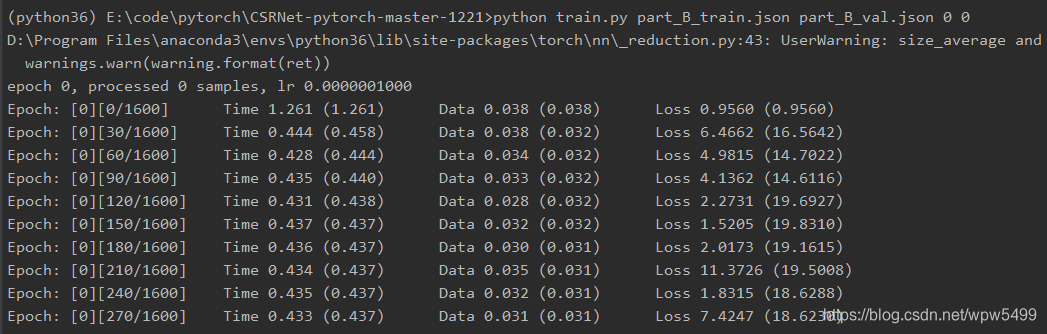
六、测试模型
1、经过漫长的训练时间,训练出了一个在SHHB上的模型
- 该权重文件上传百度云,有需要的同学自取。
- https://pan.baidu.com/s/1HZsemMo_S2nS1aOVX1ueaQ 提取码:0x9c

2、打开val.py - 修改路径,和模型权重文件的路径


- 接着右键运行val.py,得出结果

tips:
- 我刚开始使用的pytorch1.0,报错不能正常训练模型。在查了一些资料后,改成了pytorch1.5的版本,能够成功训练。
- ok各位,以上就是这篇文章的全部内容了,非常感谢你能看到这里。如果你觉得这篇文章对你有所帮助求赞求收藏求评论求转发,别忘了点一个大大的关注,各位的支持就是我最大的动力,再见!邮箱:734140820@qq.com


















 2918
2918

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











