







简介:本项目将GraphQL和React结合,以提升Web应用中的数据交互效率。通过Apollo库和Material-UI组件库,项目实现了高效的数据请求和美观的用户界面。Node.js搭建后端,Apollo处理数据查询,而mLab的MongoDB提供数据存储。这个项目展示了多种技术的集成与协作,对于学习Web开发具有重要意义。 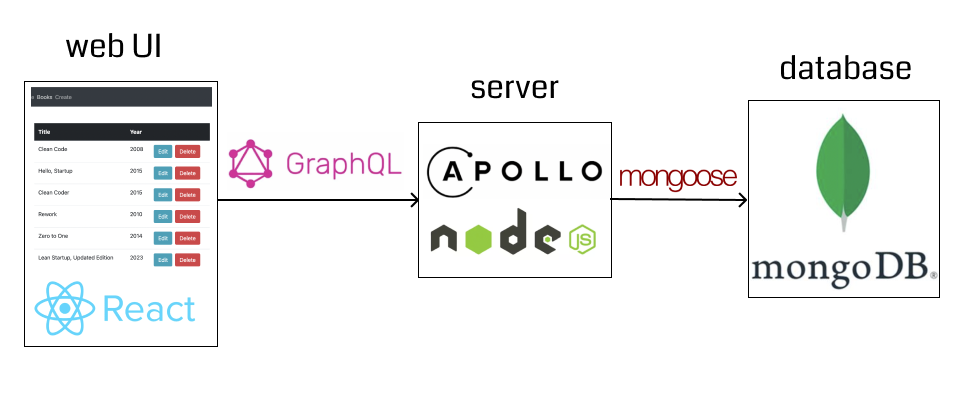
1. GraphQL的数据查询语言优势
1.1 GraphQL的基本概念解析
1.1.1 GraphQL的起源与设计哲学
GraphQL是一种由Facebook开发的用于API的查询语言,它允许客户端精确地指定所需数据的结构,而不是传统的REST API那样对服务器端的数据结构有严格的依赖。其设计哲学强调客户端驱动的数据获取方式,避免过度获取或不足获取数据的问题,旨在提高效率和灵活性。
1.1.2 GraphQL与REST的对比分析
与REST相比,GraphQL提供了一种更集中和声明式的查询方式。REST基于资源,通常会返回多余的字段,而GraphQL则允许开发者只获取他们真正需要的数据,实现了更高效的网络传输。GraphQL还允许版本化API的无版本化演化,开发者可以添加新的特性而无需修改现有的查询方式。
1.2 GraphQL的核心特性详解
1.2.1 强类型和类型系统
GraphQL使用强类型和类型系统确保在开发过程中能尽早发现数据结构的错误。类型系统定义了可供查询的数据类型和查询方式,为API的使用提供了清晰的规范,减少了文档的需要并允许开发者使用自动化的工具。
1.2.2 无需版本化的API演化
传统的API设计需要通过版本号来管理不同版本的接口,这种方式通常会导致维护多个接口的问题。GraphQL的查询语言使得API可以随着应用程序的发展而演化,而无需创建新的版本,因为它确保了向后兼容性。
1.2.3 单一数据源与高效的数据获取
GraphQL可以有效地从多个数据源中获取数据,而只需要单一的端点。这意味着应用程序可以从不同的服务中查询数据,并通过合并这些数据来减少网络延迟,从而实现更高效的查询执行和数据加载。
1.3 GraphQL在React中的应用展望
1.3.1 GraphQL与React的协同效应
React是一个流行的前端框架,它与GraphQL配合使用可以发挥出极大的效果。React的组件化特性与GraphQL的数据查询能力相结合,可以为开发者提供更多的灵活性,并能够优化前端与后端之间的数据流。
1.3.2 前瞻:GraphQL与React未来的融合方向
随着前端技术的发展和React生态的壮大,未来GraphQL可能会成为React应用中API通信的主流选择。开发者社区已经在探索利用React和GraphQL进行声明式数据流管理,以及如何与前端状态管理库如Redux或Hooks更好地集成。
以上内容从GraphQL的基础概念、核心特性到在React中的应用展望,进行了细致的解析和分析,以期为IT行业从业者提供深入的了解和实践的参考。
2. React构建用户界面及组件化
2.1 React组件化设计模式
在现代Web开发中,组件化设计已成为构建大型应用的标准方法论。React作为这一理念的实践者,将其设计模式提升到新的高度。通过将UI分解为可复用和可组合的组件,React为开发者提供了构建用户界面的强大工具。
2.1.1 组件的生命周期和状态管理
组件的生命周期是指组件从创建到挂载、更新、以及销毁的过程。React的类组件通过一系列生命周期方法来控制这个过程,例如 componentDidMount 在组件挂载后执行, componentDidUpdate 在组件更新后执行。
``` ponent { constructor(props) { super(props); this.state = {date: new Date()}; }
componentDidMount() { this.timerID = setInterval( () => this.tick(), 1000 ); }
componentWillUnmount() { clearInterval(this.timerID); }
tick() { this.setState({ date: new Date() }); }
render() { return (
Hello, world!
It is {this.state.date.toLocaleTimeString()}.
在上面的例子中,`tick`函数每秒更新组件状态`date`,而`componentDidMount`和`componentWillUnmount`分别用于启动和停止这个定时器。这确保了组件在其生命周期内的资源被正确管理。
#### 2.1.2 高阶组件(HOC)与渲染属性
高阶组件(HOC)是React中复用组件逻辑的一种高级技术。一个HOC是一个接受一个组件并返回一个新组件的函数。
```javascript
function withAuthentication(WrappedComponent) {
***ponent {
componentDidMount() {
// 检查用户是否已认证
}
render() {
if (/* 用户未认证 */) {
// 返回登录组件
return <Authenticating />;
}
// 否则,返回原始组件
return <WrappedComponent {...this.props} />;
}
}
}
而渲染属性(render props)则是一种允许组件通过属性(props)传递一个渲染函数的方式,使组件之间可以共享数据和行为。
// 父组件传递render prop给子组件
<SomeComponent render={(props) => <div>渲染结果:{JSON.stringify(props)}</div>} />
2.1.3 函数式组件与Hooks的兴起
函数式组件和Hooks的引入,是React 16.8版本中的重大更新。它使开发者无需使用类就能使用状态和生命周期功能,使得组件定义更加简洁。
function FunctionalComponent() {
const [count, setCount] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={() => setCount(count + 1)}>
Click me
</button>
</div>
);
}
在以上代码中,使用了 useState Hooks来管理组件的内部状态,这种方式比传统的类组件简洁且易于理解。
2.2 React用户界面的构建技巧
2.2.1 JSX语法与元素渲染原理
JSX是JavaScript的一个扩展,它允许开发者编写类似HTML的结构来描述React元素树。JSX最终会被Babel转换为标准的JavaScript函数调用,如 React.createElement 。
const element = <h1>Hello, world!</h1>;
在编译后,这个JSX元素将变成如下形式:
const element = React.createElement('h1', null, 'Hello, world!');
React的虚拟DOM(VDOM)会与实际的DOM进行对比,只有当VDOM和实际DOM存在不一致时,React才会进行最小限度的更新,以提高性能。
2.2.2 React Router的动态路由配置
React Router是React应用中实现路由的主要方式。通过动态路由配置,我们可以根据URL的不同显示不同的组件。
<Router>
<Route exact path="/" component={Home} />
<Route path="/about" component={About} />
<Route path="/topics" component={Topics} />
</Router>
以上代码展示了如何根据用户访问的路径来渲染不同的组件。 exact 属性确保了只有当路径完全匹配时, Home 组件才会被渲染。
2.2.3 从设计到实现的响应式布局
响应式布局使Web应用能够适应不同的屏幕尺寸和分辨率。在React中,可以使用CSS-in-JS库(如styled-components)或CSS模块来实现响应式样式。
const ResponsiveComponent = styled.div`
display: flex;
flex-direction: column;
align-items: center;
padding: 10px;
@media (min-width: 600px) {
flex-direction: row;
}
`;
function App() {
return (
<ResponsiveComponent>
{/* 一些响应式布局的组件 */}
</ResponsiveComponent>
);
}
通过媒体查询, ResponsiveComponent 能够根据屏幕宽度改变其布局,从而实现响应式设计。
2.3 React项目中的状态管理
2.3.1 Redux状态管理基础
Redux是React生态系统中广泛使用的状态管理库,它通过一个集中的存储(store)来管理应用中的状态。在Redux中,状态的改变只能通过派发(dispatch)一个action来触发。
const reducer = (state = initialState, action) => {
switch (action.type) {
case 'TOGGLE':
return {
...state,
visible: !state.visible
};
default:
return state;
}
};
const store = createStore(reducer);
// 派发一个action
store.dispatch({type: 'TOGGLE'});
2.3.2 使用MobX提升状态管理灵活性
MobX是一个易于使用的状态管理库,它允许开发者声明应用状态的响应式数据,并自动进行状态更新。
import { observable, action } from 'mobx';
class Counter {
@observable count = 0;
@action increment() {
this.count++;
}
}
const counter = new Counter();
autorun(() => {
console.log('The count is now:', counter.count);
});
在这个例子中, autorun 会自动监听 count 属性的变化并执行相关逻辑。
2.3.3 新兴状态管理库的对比分析
随着React生态系统的发展,出现了许多新兴的状态管理库,例如Recoil、Rematch等。它们各自以不同的方式优化了状态管理的开发体验。
// 使用Recoil的示例
const counterState = atom({
key: 'counter',
default: 0,
});
function Counter() {
const [count, setCount] = useRecoilState(counterState);
return (
<div>
Count: {count}
<button onClick={() => setCount(count + 1)}>Increment</button>
</div>
);
}
在以上代码中,Recoil使用了 atom 来定义状态,并通过 useRecoilState 钩子在组件中使用这个状态。Recoil的设计目标是提供更简单和更可预测的状态管理。
通过分析和应用这些不同的状态管理策略,开发者可以针对具体的项目需求和开发团队的偏好来选择最合适的解决方案。
3. Node.js作为后端服务环境
Node.js自从被发明以来,它以事件驱动、非阻塞I/O模型以及轻量级的特点,成为了构建高性能后端服务环境的热门选择。Node.js的生态系统非常丰富,拥有大量成熟的第三方库和框架,这使得开发者可以在Node.js平台上快速搭建起满足各种业务需求的应用程序。接下来,让我们深入了解Node.js的基础架构、核心模块,以及如何实现异步编程模型,并探讨它在企业级应用中的实践方式。
3.1 Node.js的基础架构与核心模块
3.1.1 Node.js的事件驱动与非阻塞I/O
Node.js的核心特性之一是其事件驱动架构,这种架构可以应对大量的并发连接,尤其适合网络服务与I/O密集型应用。Node.js采用单线程模型,并利用其非阻塞I/O操作,能够在处理大量并发连接时避免频繁创建和销毁线程的开销。
Node.js的非阻塞I/O机制依赖于libuv库,这是一个跨平台的C库,提供了对非阻塞I/O的支持。当发起一个I/O请求后,Node.js不会等待数据返回,而是继续执行后续代码。一旦I/O操作完成,相应的事件会被触发,事件处理函数随后执行。
示例代码如下:
const http = require('http');
http.createServer((req, res) => {
res.writeHead(200, {'Content-Type': 'text/plain'});
res.end('Hello World\n');
}).listen(8080);
console.log('Server running at ***');
在这个例子中,我们创建了一个HTTP服务器,当接收到请求时,服务器会立即响应,而不会因为处理请求而阻塞主线程。
3.1.2 核心模块(如fs, http, net)的使用
Node.js提供了许多核心模块,它们涵盖了各种用途,包括文件系统操作(fs模块)、HTTP服务(http模块)、TCP/IP套接字(net模块)等。
举一个文件系统操作的例子:
const fs = require('fs');
fs.readFile('/path/to/file', 'utf8', (err, data) => {
if (err) {
console.error('读取文件出错:', err);
return;
}
console.log('文件内容:', data);
});
这里演示了如何使用fs模块的readFile方法异步读取文件内容。
3.1.3 Node.js包管理器npm与项目初始化
npm是Node.js的包管理器,几乎每个Node.js项目都会用到npm来管理依赖。npm允许开发者通过简单的命令安装、更新和删除包。
初始化一个Node.js项目的基本步骤如下:
- 创建一个新文件夹作为项目目录。
- 在项目根目录下打开命令行界面,运行
npm init。 - 按照提示填写项目信息,这将生成一个package.json文件。
- 使用
npm install 包名命令安装所需的包。 - 在package.json中的"scripts"部分定义脚本命令。
一个典型的package.json文件示例如下:
{
"name": "nodeproject",
"version": "1.0.0",
"description": "我的Node.js项目",
"main": "index.js",
"scripts": {
"start": "node index.js"
},
"dependencies": {
"express": "^4.17.1"
}
}
3.2 Node.js的异步编程模型深入
3.2.1 回调函数与事件循环
Node.js的异步编程是通过回调函数来实现的。回调函数是在I/O操作或其他耗时任务完成之后,系统用来通知调用者的一种方式。
Node.js的事件循环是其处理并发的核心机制。事件循环让Node.js能够同时处理多个异步任务。在Node.js的事件循环中,主要包含以下阶段:
- timers
- pending callbacks
- idle, prepare
- poll
- check
- close callbacks
每个阶段都有相应的队列来处理事件。在执行到poll阶段时,Node.js将尝试从队列中取出并执行回调函数,直到队列清空或者达到系统允许的上限。这使得Node.js能够在没有阻塞主线程的情况下,有效处理大量的并发连接。
3.2.2 Promises与async/await的优雅解决方案
为了改善基于回调的异步编程模型的可读性和可维护性,ECMAScript 6引入了Promises,它是一种表示异步操作最终完成或失败的对象。在Node.js中,所有的异步API最终都可以返回一个Promise对象。
async/await是基于Promises的语法糖,它允许开发者以同步的方式编写异步代码,这让异步编程模型更加直观易懂。例如:
const fs = require('fs').promises;
async function readFile(path) {
const data = await fs.readFile(path, 'utf8');
return data;
}
readFile('/path/to/file').then(data => {
console.log('文件内容:', data);
}).catch(error => {
console.error('发生错误:', error);
});
3.2.3 异步流控制库(如async.js, co)的应用
在处理多个异步任务时,开发者可能需要实现任务之间的复杂依赖关系。为了简化异步流控制,社区推出了async.js这样的库。async.js提供了大量方便的函数,如parallel、series、waterfall等,用于控制异步操作的流程。
const async = require('async');
async.parallel([
function(callback) {
fs.readFile('/path/to/file1', callback);
},
function(callback) {
fs.readFile('/path/to/file2', callback);
}
], function(err, results) {
if (err) {
console.error('并发读取文件时发生错误:', err);
} else {
console.log('读取的结果:', results);
}
});
另一个流行的库是co,它使得基于生成器的异步流程控制变得更加容易。使用co,开发者可以编写看起来几乎像同步代码的异步函数:
const co = require('co');
const fs = require('fs');
co(function* () {
const file1 = yield fs.readFile('/path/to/file1', 'utf8');
const file2 = yield fs.readFile('/path/to/file2', 'utf8');
console.log(file1 + file2);
});
3.3 Node.js在企业级应用中的实践
3.3.1 企业环境下的部署与监控
Node.js在企业环境下的部署需要考虑可靠性、扩展性和监控。在生产环境中,通常使用诸如PM2这样的进程管理器来运行和管理Node.js应用程序。
# 使用PM2启动应用
pm2 start app.js
监控Node.js应用通常涉及到日志记录、性能监控和错误追踪。常用的工具有New Relic、Sentry和ELK Stack(Elasticsearch、Logstash、Kibana)等。
3.3.2 微服务架构与容器化部署(Docker/Kubernetes)
随着微服务架构的流行,Node.js也非常适合构建微服务。通过Docker容器化,可以快速部署和扩展微服务。Docker的镜像可以快速创建,而且Kubernetes提供了对容器的编排和管理功能。
3.3.3 Node.js的安全性考量与最佳实践
安全性是企业应用开发中不可忽视的部分。在Node.js中,开发者需要关注的常见安全问题包括输入验证、防止跨站脚本攻击(XSS)、保护敏感数据和使用HTTPS。
对于安全方面的最佳实践,应该使用安全的模块,避免使用已知有漏洞的依赖,及时更新Node.js和其依赖包到最新版本。在代码中要避免直接将用户输入拼接在SQL查询中,而应使用参数化查询或ORM来防止SQL注入攻击。
通过以上实践,Node.js能够在企业级应用中提供高效、灵活且可扩展的后端服务环境。接下来,我们将探讨如何在React中使用Apollo客户端和服务器端来构建现代化的Web应用程序。
4. Apollo客户端和服务器端的使用
Apollo作为一个强大的 GraphQL 客户端和服务器端解决方案,它提供了一套完整的工具集来处理数据查询、状态管理和前端缓存。本章将详细介绍Apollo的架构与核心组件,并展示如何使用Apollo构建服务器端以及如何在React项目中集成Apollo客户端。
4.1 Apollo的基本概念与架构
4.1.1 Apollo的由来及核心组件
Apollo是专为 GraphQL 设计的客户端解决方案,它让开发者可以更容易地与 GraphQL API 进行交互。Apollo Client 支持 React、Angular 和 Vue 等多个前端框架,为构建复杂的单页面应用提供了一种强大的状态管理解决方案。它通过本地缓存和内存中的状态管理,减少了对后端 API 的重复调用,提升了应用性能。
核心组件包含:
- Apollo Client:负责与后端的 GraphQL API 进行交互,并管理应用的缓存状态。
- Apollo Server:用于快速搭建可扩展的 GraphQL 服务器端,支持多种后端语言。
- Data Graph:Apollo 的数据缓存,基于不可变数据图来维护应用状态。
4.1.2 Apollo Client的安装与配置
在 React 项目中安装 Apollo Client,可以通过以下步骤进行:
首先,在项目中安装 apollo-boost 和 graphql:
npm install apollo-boost graphql
接下来,配置 Apollo Client 并与 React 应用集成:
import ApolloClient from 'apollo-boost';
const client = new ApolloClient({
uri: '你的 GraphQL 服务端点',
});
// 将 Apollo Client 集成到 React 应用中
import { ApolloProvider } from '@apollo/react-hooks';
import { render } from 'react-dom';
render(
<ApolloProvider client={client}>
<App />
</ApolloProvider>,
document.getElementById('root')
);
这里, uri 属性应指向你的 GraphQL 服务器端点。 ApolloProvider 是 Apollo Client 的 React 高阶组件,它将 Apollo Client 作为上下文提供给你的应用。
4.2 构建Apollo服务器端
4.2.1 GraphQL模式定义与解析器
在 Apollo Server 中,定义 GraphQL 模式(schema)是核心任务。模式定义了客户端可以查询或变更的数据类型,以及这些类型之间的关系。解析器(resolvers)则是实际执行数据查询或变更逻辑的函数。
const { ApolloServer, gql } = require('apollo-server');
const typeDefs = gql`
type Query {
greeting: String
}
`;
const resolvers = {
Query: {
greeting: () => 'Hello, Apollo!'
}
};
const server = new ApolloServer({ typeDefs, resolvers });
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});
在上面的例子中,定义了一个简单的查询类型 Query ,它包含一个返回字符串 "Hello, Apollo!" 的 greeting 字段。
4.2.2 Apollo Server的集成与数据源
Apollo Server 可以轻松地与现有的 Node.js 服务集成。此外,你可以将各种数据源连接到 Apollo Server,这包括数据库、REST API 或其他服务。
const { ApolloServer, gql } = require('apollo-server');
const fetch = require('node-fetch');
const typeDefs = gql`
type User {
id: ID!
name: String
}
`;
const resolvers = {
Query: {
users: () => fetch('***').then(res => res.json())
}
};
const server = new ApolloServer({ typeDefs, resolvers });
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});
这里,我们用 fetch 来从 REST API 获取用户列表数据,并返回给客户端。
4.2.3 高级特性:中间件与插件系统
Apollo Server 提供了中间件和插件系统,以增强服务器的功能。例如,通过使用认证中间件,你可以在执行查询或变更之前进行用户认证。
const { ApolloServer, gql } = require('apollo-server');
const jwt = require('jsonwebtoken');
const typeDefs = gql`
# 定义你的模式...
`;
const resolvers = {
// 定义你的解析器...
};
const server = new ApolloServer({
typeDefs,
resolvers,
context: ({ req }) => {
const token = req.headers.authorization || '';
try {
const user = jwt.verify(token.replace('Bearer ', ''), 'secret');
return { user };
} catch (err) {
return {};
}
}
});
server.listen().then(({ url }) => {
console.log(`🚀 Server ready at ${url}`);
});
这个例子展示了如何在请求上下文中传递用户身份,以便在解析器中访问当前用户的信息。
4.3 Apollo客户端在React中的集成
4.3.1 使用Apollo Client与React连接
Apollo Client 在 React 中的集成非常直观。通过使用 useQuery 和 useMutation 等 React Hooks,可以轻松地与 GraphQL API 交互。
import { useQuery, gql } from '@apollo/react-hooks';
const GET_USERS = gql`
query getUsers {
users {
id
name
}
}
`;
function UsersList() {
const { loading, error, data } = useQuery(GET_USERS);
if (loading) return <p>Loading...</p>;
if (error) return <p>Error :(</p>;
return (
<ul>
{data.users.map(({ id, name }) => (
<li key={id}>{name}</li>
))}
</ul>
);
}
这个组件使用了 Apollo Client 的 useQuery Hook 来执行 GET_USERS 查询,并将查询结果渲染到列表中。
4.3.2 状态管理与缓存机制
Apollo Client 自带一个强大的状态管理缓存机制。这个缓存不仅可以本地保存查询结果,还可以在执行多个查询或变更时智能地合并和更新数据。
const client = new ApolloClient({
cache: new InMemoryCache(),
// 其他配置...
});
你可以通过自定义 InMemoryCache 的配置来控制缓存行为。
4.3.3 实现数据的实时更新与订阅
Apollo 支持实时更新,这通过 GraphQL 的订阅机制实现。客户端可以订阅特定的事件,并在事件发生时收到实时数据更新。
const SUBSCRIBE_TO_NEW_USERS = gql`
subscription onNewUser {
newUser {
id
name
}
}
`;
function NewUsersSubscription() {
const { data, loading, error } = useSubscription(SUBSCRIBE_TO_NEW_USERS);
if (loading) return <p>Subscribing...</p>;
if (error) return <p>Error :(</p>;
return (
<div>
New User: {data newUser.name}
</div>
);
}
在这个订阅示例中,每当有新用户注册, useSubscription Hook 会接收到更新。
通过这些章节,我们可以看到 Apollo 如何在客户端和服务器端提供丰富的功能,使得构建与 GraphQL 兼容的应用程序变得更为简单和高效。无论是前端状态管理还是后端服务器搭建,Apollo 都提供了一套完整的解决方案来满足现代应用的开发需求。
5. Material-UI的UI组件库应用
5.1 Material-UI库概述与设计理念
5.1.1 Material-UI的发展历程与核心优势
Material-UI库是React前端开发中广泛使用的UI组件库之一,它受到了Google的Material Design设计语言的启发。Material-UI不仅仅是一个UI库,它更是一个能够帮助开发者快速构建高质量、响应式设计的应用程序的工具集。自2014年首次发布以来,Material-UI经历了多个版本的迭代,逐渐成为前端开发领域中的一个主流选项。
Material-UI的核心优势在于其丰富的组件集合、高度的可定制性以及良好的社区支持。它提供了一整套构建用户界面所需的基本和高级组件,如按钮、输入框、选择器、图表等,这使得开发人员可以快速搭建出既美观又功能丰富的用户界面。此外,Material-UI的组件在设计上遵循Material Design规范,这意味着用户界面在视觉上看起来会非常和谐和现代化。
// 示例代码:安装Material-UI
// 使用npm安装最新版本的Material-UI
npm install @material-ui/core
在核心优势方面,Material-UI还提供了主题定制功能,允许开发者自定义组件的样式和行为,从而确保UI的一致性和品牌识别度。它还支持对旧版浏览器的兼容性,使得开发者可以构建跨平台的应用程序。
5.1.2 响应式设计与主题定制
Material-UI的一大特色是其响应式设计的能力。响应式设计意味着应用程序能够适应不同的设备和屏幕尺寸,从而提供更佳的用户体验。Material-UI通过灵活的布局组件,如Grid、Container、Paper等,帮助开发者轻松实现响应式设计。例如,使用Grid组件可以让布局在不同屏幕尺寸下自动调整,通过属性设置可以控制每种屏幕尺寸下的网格表现。
主题定制是Material-UI的另一亮点。开发者可以通过创建和应用一个自定义的MUI主题来全局修改应用程序的配色方案、排版、间距、边距等属性。这个过程不需要修改每一个组件的样式,只需定义一次主题即可。在应用中使用主题时,可以利用ThemeProvider组件包裹整个应用或者特定组件,如下所示:
// 示例代码:使用Material-UI的主题定制
import { ThemeProvider } from '@material-ui/core/styles';
import { createMuiTheme } from '@material-ui/core/styles';
const theme = createMuiTheme({
palette: {
primary: {
main: '#007bff', // 定义主要颜色为蓝色
},
},
});
function App() {
return (
<ThemeProvider theme={theme}>
{/* 应用程序组件 */}
</ThemeProvider>
);
}
通过这种方式,开发者可以轻松地为应用程序赋予一致的视觉风格,而不必担心样式冲突或主题一致性问题。
6. mLab MongoDB的数据存储功能
随着应用程序的发展,数据存储的需求也在不断增长。mLab 提供的 MongoDB 作为一种流行的 NoSQL 数据库,其易扩展性和灵活的数据模式正变得越来越受欢迎。MongoDB 不仅提供了传统数据库的存储功能,还提供了丰富的查询和索引优化能力。
6.1 MongoDB的基础知识与特性
6.1.1 非关系型数据库MongoDB简介
MongoDB 是一个面向文档的数据库管理系统,它由C++编写的。使用类似 JSON 的格式存储数据,这让它与传统的关系型数据库(如 MySQL 或 PostgreSQL)有所不同。MongoDB 的文档存储模型允许开发者在数据库中存储复杂的数据结构,比如数组和嵌套文档。它还支持强大的查询功能,如范围查询、正则表达式匹配等。
6.1.2 MongoDB的数据模型与索引优化
MongoDB 的数据模型是基于“文档”的。每个文档都是一个由字段和值对组成的 JSON 对象。这些文档被存储在“集合”中,相当于关系型数据库中的表。为了提高查询效率,MongoDB 提供了多种索引类型,如单键索引、复合索引、文本索引和地理空间索引。索引可以显著减少查询所需的时间,但同时也需要占用额外的存储空间。因此,在设计索引时,需要权衡查询效率和存储成本。
{
"_id": ObjectId("..."),
"name": "John Doe",
"age": 30,
"address": {
"street": "123 Main St",
"city": "Anytown",
"zip": "12345"
}
}
6.2 MongoDB在Node.js项目中的集成
Node.js 和 MongoDB 可以说是现代 Web 开发的“黄金组合”。Node.js 的异步操作和事件驱动模型与 MongoDB 的高性能和灵活的数据模型相得益彰。
6.2.1 Node.js与MongoDB的连接与操作
要在 Node.js 中连接 MongoDB,可以使用流行的 ODM (Object Document Mapping) 工具,如 Mongoose。Mongoose 为 MongoDB 的操作提供了一种更高级的抽象,帮助开发者管理数据模型和验证数据。
const mongoose = require('mongoose');
mongoose.connect('mongodb://localhost:27017/yourDatabase', { useNewUrlParser: true, useUnifiedTopology: true });
const schema = new mongoose.Schema({
name: String,
age: Number,
address: {
street: String,
city: String,
zip: String
}
});
const Person = mongoose.model('Person', schema);
6.2.2 Mongoose ODM的使用与优势
使用 Mongoose 不仅可以简化数据模型的定义,还可以通过模式验证确保数据的一致性和完整性。Mongoose 支持钩子(hooks)和中间件(middleware),这些是处理数据生命周期事件的有用工具。
6.2.3 数据库的迁移与版本控制
随着应用的发展,数据库的结构可能需要发生变化。Mongoose 提供了迁移工具,可以帮助开发者维护数据库的版本控制。这有助于自动化数据库结构的变更和数据迁移过程。
const mongoose = require('mongoose');
const Schema = mongoose.Schema;
const newSchemaVersion = new Schema({...}, { versionKey: false });
// 定义数据库模式的新版本...
6.3 MongoDB的性能优化与监控
性能优化是任何数据库应用的重要方面。MongoDB 提供了多种工具和方法来优化性能,并保持数据库的健康。
6.3.1 数据库性能调优技巧
为了优化性能,开发者可以对数据库执行各种操作,例如,通过添加索引来加速查询、优化查询语句、调整内存使用和优化数据存储结构。开发者还可以监控和分析查询性能,以找到瓶颈并进行调整。
6.3.2 实时监控与故障诊断
MongoDB 提供了实时监控工具,比如 MongoDB Atlas 或 mongostat/mongotop,这些工具可以监控数据库的性能指标和系统资源的使用情况。通过这些工具,开发者可以对数据库进行故障诊断,并在出现问题时迅速响应。
6.3.3 备份策略与数据恢复流程
数据备份是保障业务连续性的重要策略。MongoDB 提供了多种备份方法,包括全备份和增量备份。开发者可以根据业务需求制定备份策略,并通过定期恢复数据来测试恢复流程,确保在发生数据丢失时能够迅速恢复。
mongodump --db yourDatabase --out /path/to/backup
# 备份数据库
mongorestore --db yourDatabase --drop /path/to/backup
# 从备份中恢复数据
通过上述内容的详细介绍,我们可以看到 MongoDB 在数据存储方面的强大功能以及如何与 Node.js 集成。下一章节将重点介绍如何通过这些技术构建一个综合性的案例应用。
7. GraphqlReactApp的综合案例分析
7.1 案例项目的需求分析与架构设计
7.1.1 确定应用的业务需求与功能范围
在开始构建GraphqlReactApp之前,首先需要明确应用的业务需求和功能范围。我们假设GraphqlReactApp是一个在线的个人学习平台,用户可以创建个人资料,加入课程,提交作业,获取成绩,并跟踪学习进度。
为了满足这些需求,我们需要实现以下核心功能:
- 用户认证与授权
- 个人资料管理
- 课程内容展示
- 作业提交与批改
- 成绩与进度跟踪
每项功能都需要通过API与数据库进行交互,而GraphQL的强类型系统可以帮助我们清晰地定义这些交互的数据模型。
7.1.2 设计系统的整体架构与技术选型
接下来,我们需要设计整个系统的架构,并确定所使用的技术栈。基于GraphQL的优势和React在前端构建方面的流行度,我们决定采用以下技术:
- 前端:React,利用GraphQL Apollo客户端进行状态管理和数据查询
- 后端:Node.js,搭配Express框架构建RESTful API,并集成Apollo Server
- 数据库:MongoDB,存储用户数据和课程内容
- 认证系统:使用JWT(JSON Web Tokens)进行安全的用户认证
通过模块化和组件化的设计,我们的架构将拥有良好的扩展性。同时,通过RESTful API的抽象,我们能够保持后端与前端的松耦合。
7.2 从零开始构建GraphqlReactApp
7.2.1 前端React界面的设计与实现
React界面的设计和实现,从构建基础组件开始,例如用户登录和注册组件。在React中,这些组件可能会这样实现:
function Login({ onLoginSuccess }) {
const [username, setUsername] = useState("");
const [password, setPassword] = useState("");
const handleLogin = () => {
// 使用Apollo客户端与后端进行登录操作
// 登录成功后调用onLoginSuccess
};
return (
<div>
<input type="text" value={username} onChange={(e) => setUsername(e.target.value)} />
<input type="password" value={password} onChange={(e) => setPassword(e.target.value)} />
<button onClick={handleLogin}>Login</button>
</div>
);
}
7.2.2 后端Node.js服务的搭建与配置
在Node.js后端服务中,我们将设置一个简单的API来处理登录请求:
app.post('/login', async (req, res) => {
const { username, password } = req.body;
// 验证用户名和密码(伪代码)
const user = await User.findOne({ username, password });
if (user) {
// 登录成功,设置JWT令牌
const token = generateToken(user);
res.json({ token });
} else {
// 登录失败
res.status(401).send('Invalid credentials');
}
});
7.2.3 数据库MongoDB的整合与数据建模
最后,我们需要整合MongoDB数据库,并根据业务需求进行数据建模:
const mongoose = require('mongoose');
const { Schema } = mongoose;
// 用户模型
const userSchema = new Schema({
username: { type: String, required: true },
password: { type: String, required: true },
// 其他字段...
});
const User = mongoose.model('User', userSchema);
module.exports = User;
7.3 系统测试与优化部署
7.3.* 单元测试、集成测试与端到端测试
单元测试是针对独立模块的测试,以确保每个部分按预期工作。集成测试检查不同模块之间的交互。端到端测试(E2E)验证整个应用的流程。例如,使用Jest和React Testing Library编写单元测试:
import { render, fireEvent } from '@testing-library/react';
import Login from './Login';
test('renders login inputs and button', () => {
const { getByPlaceholderText, getByText } = render(<Login />);
const usernameInput = getByPlaceholderText('Username');
const passwordInput = getByPlaceholderText('Password');
const loginButton = getByText('Login');
expect(usernameInput).toBeInTheDocument();
expect(passwordInput).toBeInTheDocument();
expect(loginButton).toBeInTheDocument();
});
7.3.2 性能测试与用户体验优化
性能测试确保应用在高负载下仍能稳定运行。我们可以通过Lighthouse这类工具来评估前端性能,并进行优化。例如,优化图片加载时间、减少不必要的HTTP请求和使用代码分割。
7.3.3 容器化与CI/CD流程的实现
容器化可以提高开发和部署的效率。使用Docker容器化React前端和Node.js后端服务,然后在CI/CD流程中自动化部署。例如,使用GitHub Actions来自动化测试和部署:
name: CI/CD Pipeline
on: [push, pull_request]
jobs:
build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Setup Node.js
uses: actions/setup-node@v1
with:
node-version: '14'
- name: Install Dependencies
run: npm ci
- name: Run Tests
run: npm test
- name: Build App
run: npm run build
- name: Deploy to AWS
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
run: aws s3 sync build/ s3://your-bucket-name --delete
通过这些步骤,我们可以构建一个高效、可维护且易于扩展的GraphqlReactApp应用。
简介:本项目将GraphQL和React结合,以提升Web应用中的数据交互效率。通过Apollo库和Material-UI组件库,项目实现了高效的数据请求和美观的用户界面。Node.js搭建后端,Apollo处理数据查询,而mLab的MongoDB提供数据存储。这个项目展示了多种技术的集成与协作,对于学习Web开发具有重要意义。















 1281
1281

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









