







 本文提出了一种新的主动领域自适应方法TQS,结合可转移的多模型投票、不确定性评估和域难分性,有效选择在存在域偏移情况下最有价值的目标样本进行标注,实验证明其在Office-31、Office-Home和VisDA-2017数据集上优于现有UDA和ADA。
本文提出了一种新的主动领域自适应方法TQS,结合可转移的多模型投票、不确定性评估和域难分性,有效选择在存在域偏移情况下最有价值的目标样本进行标注,实验证明其在Office-31、Office-Home和VisDA-2017数据集上优于现有UDA和ADA。
论文:Transferable Query Selection for Active Domain Adaptation
代码:https://github.com/thuml/Transferable-Query-Selection
摘要
无监督领域自适应(Unsupervised domain adaptation, UDA)将知识从有完整标注的源域传递到一个未标记的目标域。近年来UDA取得了一系列进展,但是与使用有完整标注的目标数据相比性能差距仍然很大。主动领域自适应(Active domain adaptation, ADA)可以通过选择少量目标数据进行标注,将标注成本降至最低。由于域偏移问题,之前的主动学习方法无法有效地选择最有价值的目标域数据。本文提出了可转移查询选择策略(Transferable Query Selection, TQS),针对域偏移(domain shift)问题综合了三个评价标准(可转移的多模型投票机制、可转移的不确定性、可转移的域难分性)选择信息量最大的样本标注,并使用随机化的采样算法来增强所选样本的多样性。在不同领域自适应数据集上的实验表明本文提出的算法可以在域偏移的情况下选择信息量最大的目标样本,显著优于之前的UDA和ADA方法。
1. 介绍
无监督领域自适应(UDA)受到了广泛关注,它在带标注的源域数据上训练并将所学的模型迁移到未标记的目标域数据。然而,UDA在准确性方面仍远远落后其对应的监督学习。在[19]中,目标标记数据的“市场价值”比源标记数据的大的多,甚至少量目标标记数据就可以显著提高领域自适应能力。因此,一个新的DA范式被提出,用于对一小部分目标数据进行标注使领域自适应模型最大限度地受益。这种学习模式被称为主动领域自适应(ADA)。
目前常见的主动学习方法主要是在一个无标注的数据池中选择最有标注价值的样本(pool-based)。目前主要的深度主动学习主要是基于三个标准:多模型投票机制、不确定性和代表性。文章认为之前在单个域上成功的主动学习方法,由于存在域偏移问题不能迁移到跨域的样本选择上。
本文针对以上的问题,提出了可转移查询选择策略,在面对域偏移的情况下,综合了三个评价标准,即域间可转移的多模型投票机制、可转移的不确定性和可转移的域难分性,给出高价值样本标注。在提出可转移的投票制时,通过训练对抗样本使多个分类识别在目标域数据低密度区的样本;根据多分类器的结果,通过组合多分类器的结果计算样本的不确定性,减小不确定性的方差。提出的可转移域难分性决定了一个目标样本是否为离群点,最后使用了随机初始化机制提高采样的多样性。总结本文的贡献为:
- 提出了可转移查询选择(TQS),一种用于主动域自适应的新查询选择标准,一个集合可转移的多模型投票制、不确定性和域难分性的评价样本标注价值的指标。
- 设计了一种随机抽样机制,以增加标注样本的多样性,防止选择的样本提供冗余的信息。
- 在多个DA基准上的实验结果表明,与无监督领域自适应、主动学习和主动领域自适应方法相比,所提出的TQS准则选择了信息量最大的目标样本,实现了更高的精度。
2. 相关工作
领域自适应(Domain Adaptation, DA):目前提出的无监督领域自适应算法,性能普遍比不过给一定目标域标注训练的算法,所以半监督领域自适应(Semi-Supervised Domain Adaptation, SSDA) 和 小样本领域自适应(Few-Shot Domain Adaptation, FSDA)被提出解决这个问题,本文研究如何选择最有价值的目标样本做标注,从而有效的对以上两种训练范式进行增益。
主动学习(Active Learning, AL):目前的主动学习方法,主要可以划分为基分为于多模型投票制、基于样本不确定性和基于样本代表性的方法,本文认为在存在域偏移的情况下目前提出的主动学习方法并不能选择到最有价值的目标域样本。
主动域适应(Active Domain Adaptation, ADA):主动域适应刚开始被提出是一种two-stage的训练模式,或者说是一种基于置信度的评价方法,容易受到训练模式单一的限制。它把熵和域相似性作为不确定性和代表性的依据。本文认为以上评价标准在存在域偏移的情况下都是没有效果的。
3. 方法
3.1 可转移的多模型投票机制
之前的主动学习算法中使用多模型投票机制,相关工作如McDropout,将多个模型的预测结果中最矛盾的作为不确定的样本送给专家标注。本文认为以上算法在跨域问题上是不准确的,多分类器C1-4在源域上都分类准确均落在数据低密度区,由于存在域偏移这些多分类器迁移到目标域数据就趋向于落在数据高密度区,此时一部分确定的样本在目标域上也被选中了(下图左下)。为了解决以上问题,本文的基本思路就是通过训练迁移对抗样本,提高分类器C1-4的可转移性,通过最小化分类器间的分歧收拢不同分类边界(下图右上),最终用投票制得到真正为不确定的样本。
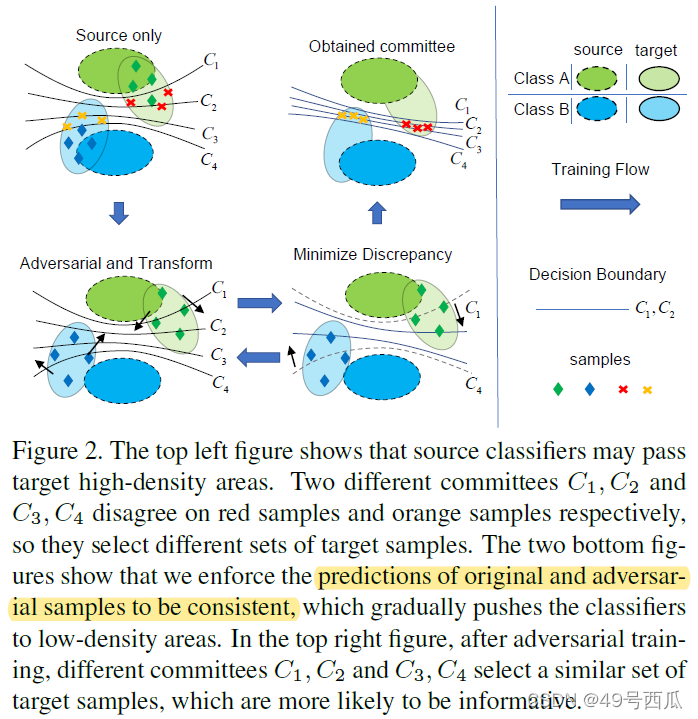
查找对抗样本的方式为,针对目标域样本
x
t
x_{t}
xt,在一定扰动范围内,找到让每个分类器
C
m
C_{m}
Cm的预测概率变化最大的作为对抗样本,原图和对抗样本之间的概率差即为可转移投票制损失(
L
c
o
m
L_{com}
Lcom)。
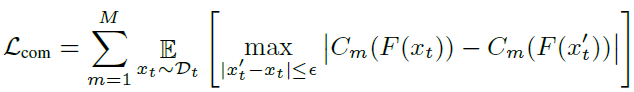
基于以上训练好的分类器,用多分类器的分歧作为每个目标域样本的可转移投票制分数(transferable committee criterion, TQSc):
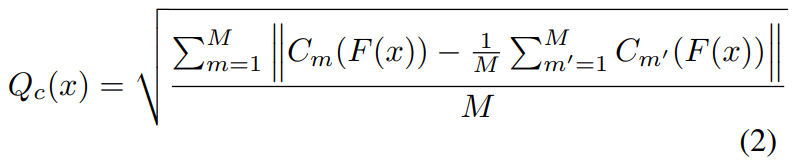
3.2 可转移的不确定性
训练多分类器时,对他们采用不同的初始化,训练仍然用的传统的交叉熵损失:
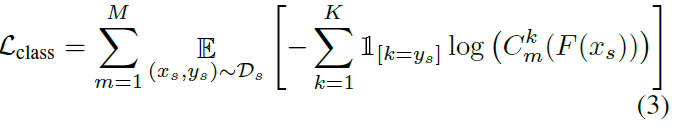
在衡量可转移不确定性时,本文使用了每个分类器最大和第二大预测概率差作为不确定性(主动学习中Margin的思想):
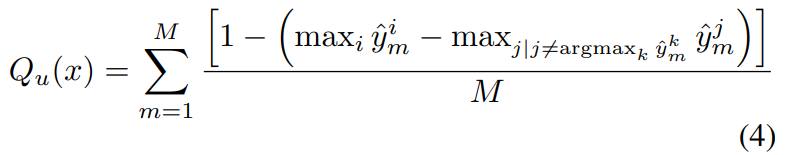
3.3 可转移的域难分性
目标域离群点对样本选择无用甚至有害,所以需要筛选出这些离群点。所以在这里提出了可转移的域难分性,作为判定样本是否能代表目标域性质的依据,首先训练一个域判别器D,D的输出为样本属于目标域的概率:
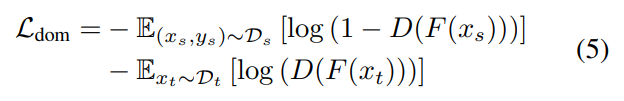
基于域判别器D的输出概率,概率趋近于0则最像源域样本,概率趋近于1则最倾向于目标域离群点,两种样本都应该被排除。采用高斯函数形式作为样本的可转移的域难分性
Q
d
(
x
)
Q_{d}(x)
Qd(x):
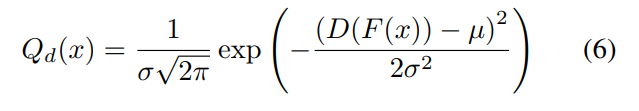
跟据高斯函数的性质,针对源域样本:
lim
D
(
F
(
x
)
)
→
0
Q
d
(
x
)
=
0
\lim\limits_{D(F(x))\rightarrow0}Q_{d}(x)=0
D(F(x))→0limQd(x)=0
目标域离群点样本:
lim
D
(
F
(
x
)
)
→
1
Q
d
(
x
)
=
0
\lim\limits_{D(F(x))\rightarrow1}Q_{d}(x)=0
D(F(x))→1limQd(x)=0
综上,选择
Q
d
(
x
)
Q_{d}(x)
Qd(x)大于一定阈值的即可以排除以上两种样本。
3.4 最终的可转移查询选择指标
为了排除公式(1)的干扰,额外训练一个只有交叉熵损失的分类器
C
C
C,在训练数据阶段的损失函数为:当前源域数据和已标注目标域数据在纯净分类器损失
L
L
L、多分类器的损失
L
c
l
a
s
s
′
L_{class}^{'}
Lclass′、可转移的多模型投票机制损失
L
c
o
m
L_{com}
Lcom,可转移的域难分性损失
L
d
o
m
L_{dom}
Ldom:
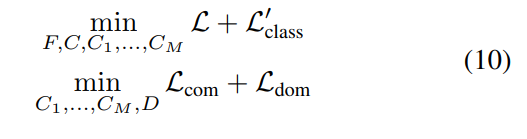
每轮选择样本标注时,最终的价值评价指标
Q
Q
Q为:
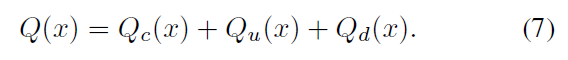
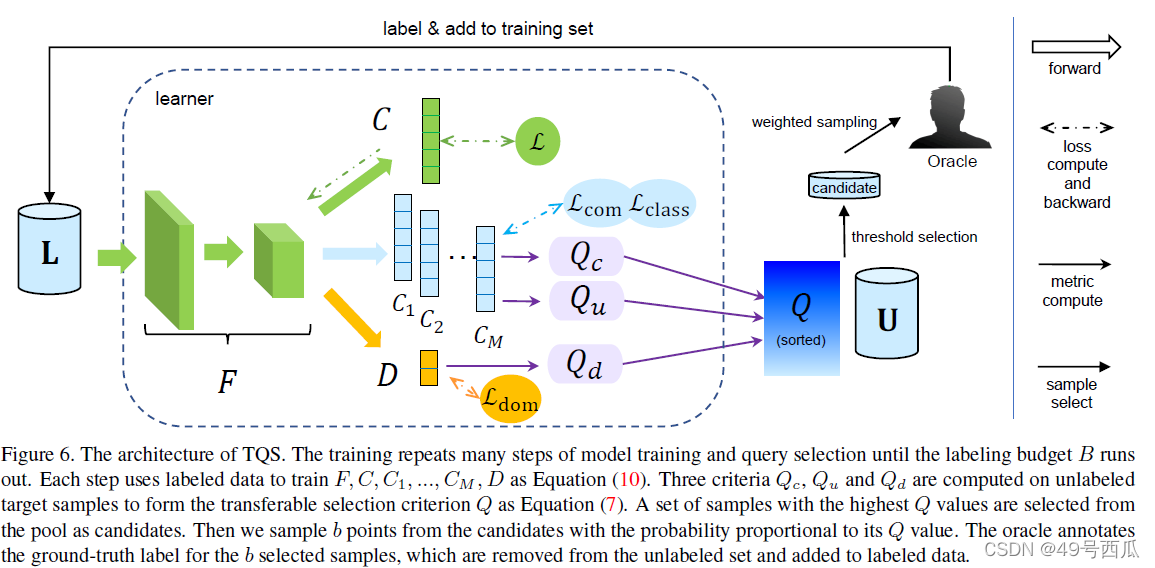
总结本文的框架如下图所示。每一步都使用带标签的数据根据等式(10)训练特征提取器F、分类器C、C1…M以及域判别器D。对未标记的目标样本计算Qc、Qu和Qd形成总指标Q。从中选择一组具有最高Q值的样本作为标注候选,然后我们从候选样本中以与其Q值成正比的概率抽取b个送给专家标注,再对应的更新已标注和未标注样本集。重复上述过程,直到达到标注数量限额为止。
4. 实验
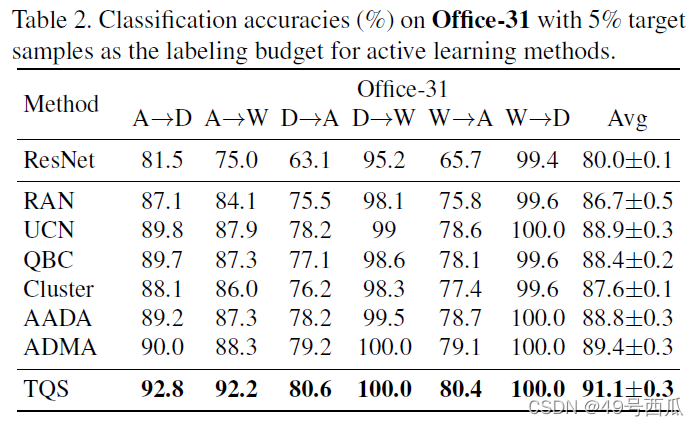
在三个数据集Office-31、Office-Home和VisDA-2017上进行实验,统一只能标注目标域数据中的5%,最后一列的Avg代表准确率的平均方差。在Office-31数据集的结果如下表所示:
在Office-Home和VisDA-2017数据集上的结果如下:
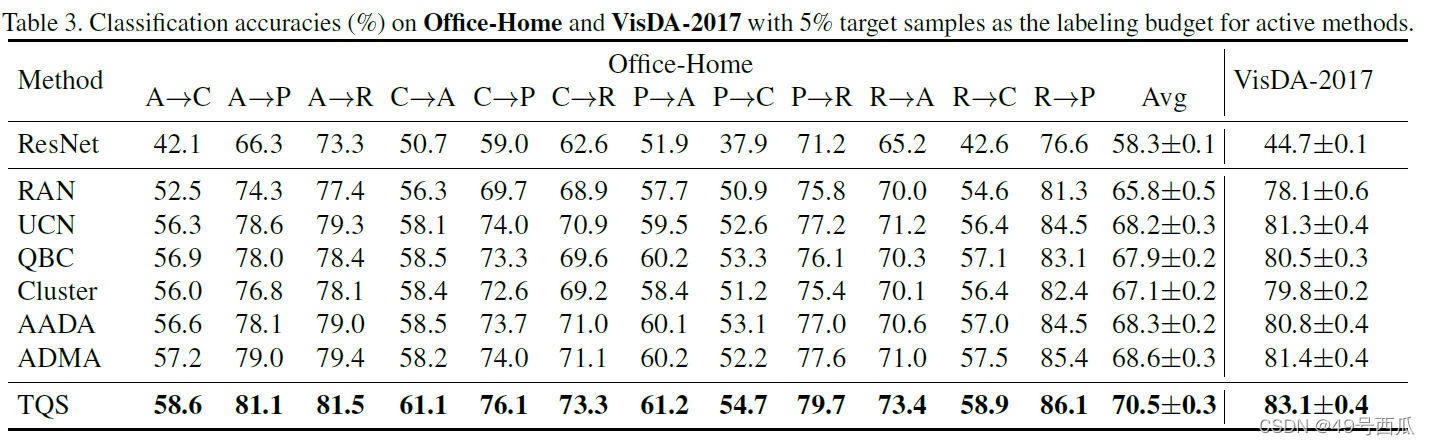
实验结果表明:(1)随机选择目标域样本标注比原先UDA中全监督的ResNet要强,说明了主动领域自适应可以作为一种提升性能的方法;(2)本文提出的算法超越了其他主动学习策略以及其他无监督领域自适应的sota方法,说明了所提算法的有效性。
5.结论
本文提出了一种新的可转移查询选择(TQS)方法用于主动领域自适应问题,该选择策略由可转移的不确定性、可转移的领域性和可转移的多模型投票制组成,在存在域偏移的情况下能选择信息量最大的目标样本标注。在三个基准数据集上的实验结果表明,TQS是作为有效的主动域自适应方法,可以用于不同的标记数量限额,并有机会与无监督和半监督的领域自适应方法协作,以进一步提高性能。

















 56
56

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









