







最近,国产大模型 DeepSeek 凭借其强大的性能和广泛的应用场景,迅速成为 AI 领域的焦点。然而,随着用户数量的激增,DeepSeek 的在线服务时常面临访问压力,导致响应延迟甚至服务中断的情况。幸运的是,DeepSeek 作为一款开源模型,为用户提供了本地部署的解决方案。
为什么选择本地部署 DeepSeek?
- 稳定高效:无需担心网络波动或服务器压力,本地部署确保模型始终高效运行。
- 隐私安全:数据完全存储在本地,避免敏感信息外泄,保障用户隐私。
- 灵活便捷:支持离线使用,随时随地调用模型,满足多样化需求。
- 开源自由:DeepSeek 的开源特性让用户可以根据需求自定义优化,打造专属 AI 工具
1. 安装Ollama
我们可以访问 https://ollama.com/ 进入 Ollama 官网下载 Ollama ,下载时有三个系统的安装包可选择,这里只需要选择下载我们电脑对应的操作系统版本即可,这里我选择的是 Mac 版本。
Ollama 安装包下载完成后直接双击安装即可。
安装成功验证
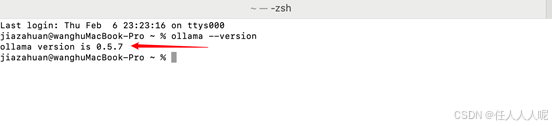
1、 Ollama 安装完成后需要打开电脑的终端 ,也就是命令提示符,输入 ollama --version 并按回车键,这个操作是为了验证这个软件是否安装成功,如果显示如下版本提示说明安装成功。
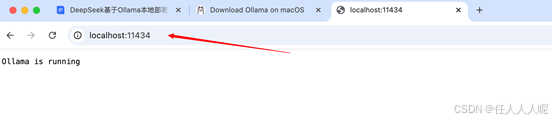
2、浏览器输入 http://localhost:11434/ 也可以验证Ollama安装成功,如果安装失败检查11434端口是否被占用。
2.下载部署 Deepseek 模型
回到 https://ollama.com/ 网址中,在网页上方搜索框中输入 Deepseek-r1,这个 Deepseek-r1 就是我们需要本地部署的一个模型。
点击 Deepseek-r1 后会进入详情界面,里面有多个参数规模可供选择,从 1.5b 到 671b 都有。
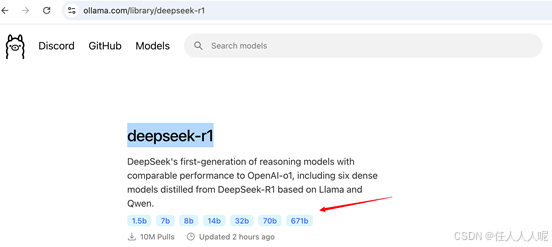
需注意的是,这里我们需要根据自己电脑的硬件配置来选择模型大小。其中,具体用多少B的模型主要需要看内存(M芯片用户)。(windows用户看显卡显存)。
- 8G内存:1.5B (1.1GB模型大小)
- 16G内存:8B及以下(4.9GB模型大小)
- 32G内存:14B及以下(9GB模型大小)
- 64G内存及以上:32B及以下(20GB模型大小)
我是想要电脑低负载一点去长期跑,所以我这里就用8B模型了。
2.1 通过Ollama下载模型
注意根据自己电脑的配置,在终端(命令提示符)进行复制相应的命令去执行下载。
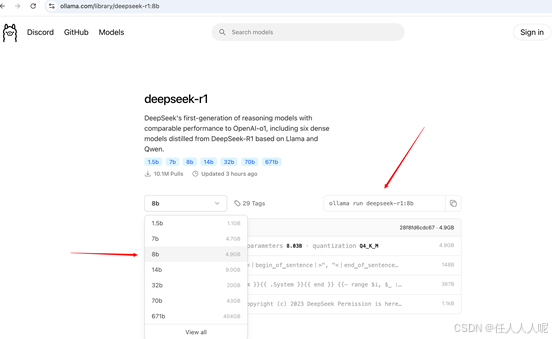
由于我下载的deepseek-r1:8b模型,对应就是 ollama run deepseek-r1:8b 命令
![]()
如果发现下载速度奇慢,可以根据contrl+c键取消本次下载,然后重新输入部署命令。只要没有退出Ollama,下载可以断点续传。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 584
584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









