







目前看来,基于深度学习是在人脸识别领域效果比较出色的机器学习方法。
但从学术的角度来讲,“最好”是一个谨慎的词语,深度学习从以往不被认可逐渐成长为机器学习的主流,同样,也难保未来会有其它方法会取代深度学习。
1、对于许多应用程序,使用更简单的算法像逻辑回归和支持向量机可以工作的很好,而使用深度神经网络只会使事情变得复杂。
2、然而深度神经网络(deep belief networks )是最好的一个不可知域算法,如果你有领域知识的话,那么使用其他算法,如用于语音识别的HMM、用于图形压缩并识别的小波算法等,就可以表现更好。已经有一些工作把这些领域知识合并到神经网络模型,但是这还是不足以完全取代所有其他的模型和算法。
作者:云从科技
链接:https://www.zhihu.com/question/26434245/answer/221761953
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作者:小Q
链接:https://www.zhihu.com/question/26434245/answer/1263872084
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
作为一个资深AI应用开发者,市面上的开源算法以及一些AI企业开放的算法基本都有涉猎,总结来说有:
一、各个人脸识别公司、系统简介
1.1 虹软
虹软:比较推荐和喜欢的一家,有详细的Demo,文档信息等,更重要的是算法免费,而且作为商业算法,它非常简单容易上手。
人脸检测:检测人脸位置、锁定人脸坐标。
人脸跟踪:精确定位并跟踪面部区域位置。
人脸比对:比较两张人脸的相似度。
人脸查询:在人脸库中查询相似的人脸。
人脸属性:检测人脸性别、年龄等属性。
活体检测:检测是否真人,预防恶意攻击。
点击前往官网->

1.2 云脉
云脉-OCR SDK:OCR及人脸识别对比等,各项都有。
1.3 腾讯AI
腾讯AI-人脸与人体识别:各项功能都有,可直接去腾讯在线试下
1.4 1MB轻量级人脸检测模型
一个很火的轻量级人脸检测模型,在github和gitee上均有项目,研究的话可以试试,如果商用就不推荐了。
1.5 SeetaFace-科院计算机所开源项目
SeetaFace:中科院计算机所开源项目,仅做了解了一些,未做深入研究。
二、基于虹软的Java人脸识别
2.1 人脸识别SDK
基于虹软的免费SDK:
官网首页 -> 右上角开发者中心 -> 选择“人脸识别” -> 添加SDK,会生成APPID、SDK KEY后续会用到,根据需要选择不同的环境(本文基于windows环境),然后下载SDK是一个压缩包。
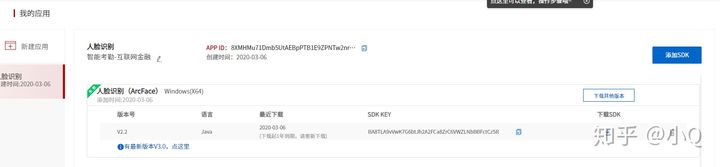
2.2 Java项目搭建
从GitHub上clone一个ArcSoft的Java版本Demo。
2.2.1 下载Demo项目
github地址:chengxy-nds/ArcSoftFaceDemo
本地搭建数据库,创建表:user_face_info。这个表主要用来存人像特征,其中主要的字段 face_feature 用二进制类型 blob 存放人脸特征。
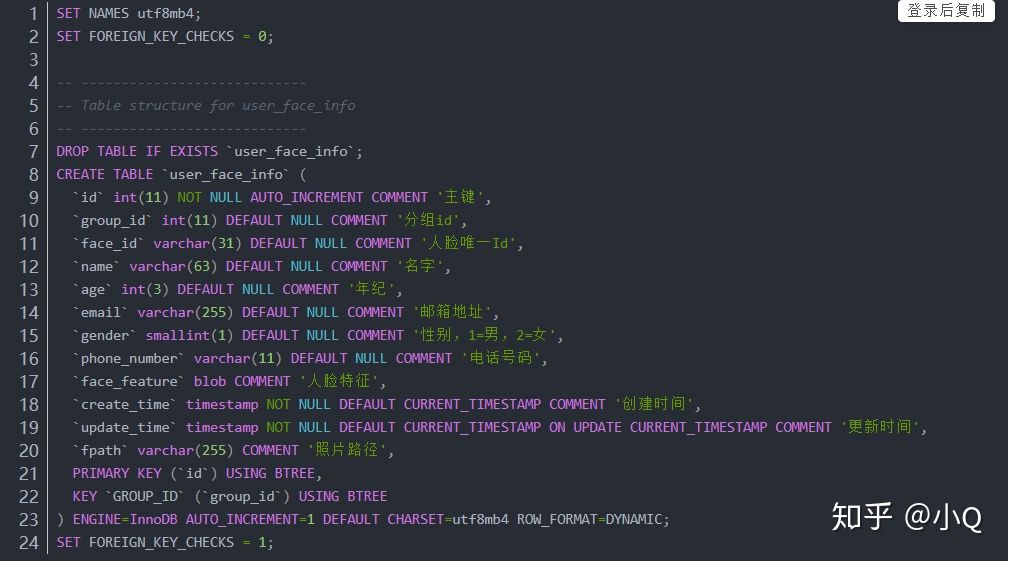
2.2.2 修改application.properties文件
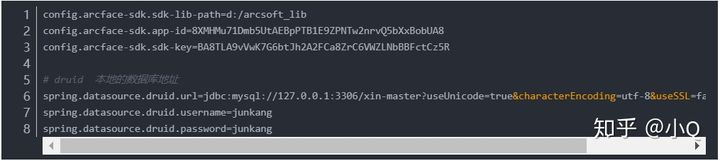
整个项目还是比较完整的,只需改一些配置即可启动,但有几点注意的地方,后边会重点说明。
config.arcface-sdk.sdk-lib-path: 存放SDK压缩包中的三个.dll文件的路径
config.arcface-sdk.app-id : 开发者中心的APPID
config.arcface-sdk.sdk-key :开发者中心的SDK Key
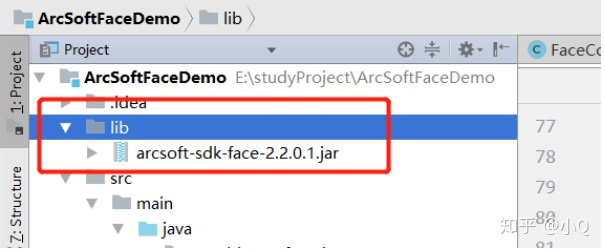
2.2.3 根目录创建lib文件夹
在项目根目录创建文件夹 lib,将下载的SDK压缩包中的arcsoft-sdk-face-2.2.0.1.jar放入项目根目录:
2.2.4 引入arcsoft依赖
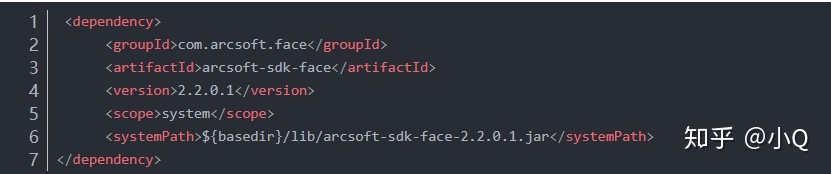
pom.xml文件要配置includeSystemScope属性,否则可能会导致arcsoft-sdk-face-2.2.0.1.jar引用不到。
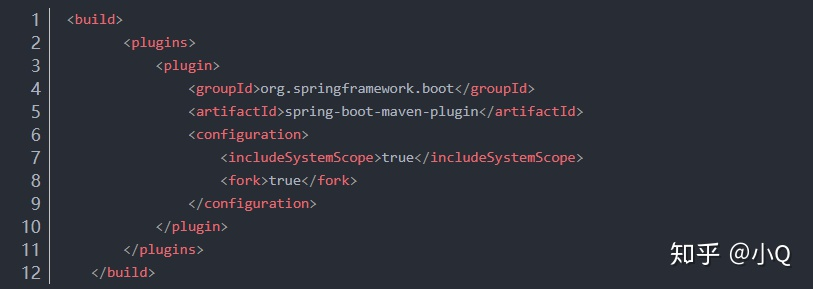
2.2.5 启动项目
run Application文件启动
测试一下:http://127.0.0.1:8089/demo,如下页面即启动成功。
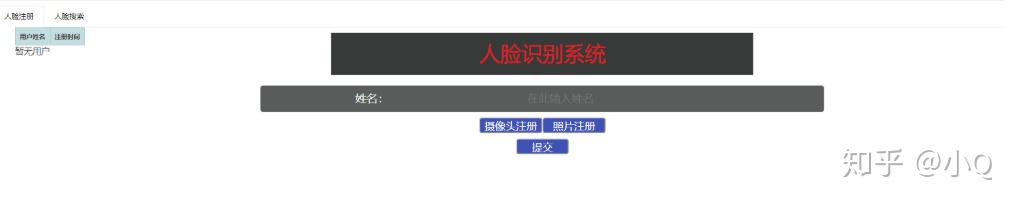
2.3 操作测试
2.3.1 录入人脸图像
页面输入名称,点击摄像头注册调起本地摄像头,提交后将当前图像传入后台,识别提取当前人脸体征,保存至数据库。
2.3.2 人脸对比
录入完人脸图像后测试一下能否识别成功,提交当前的图像,然后会出现对比结果。
2.4 源码分析
2.4.1 JS调起本地摄像头拍照,上传图片文件字符串
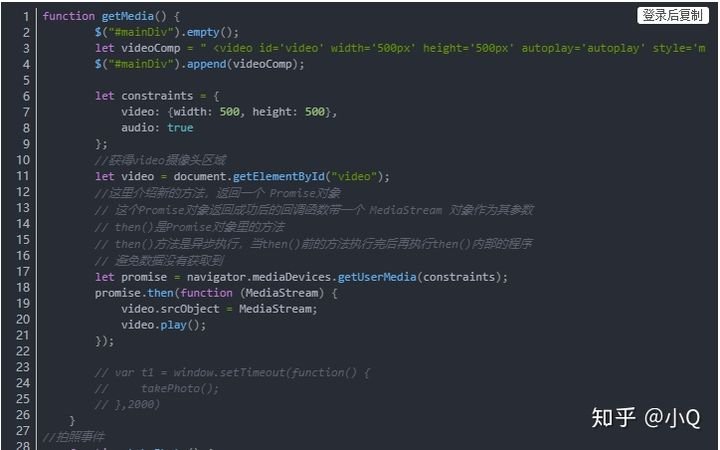
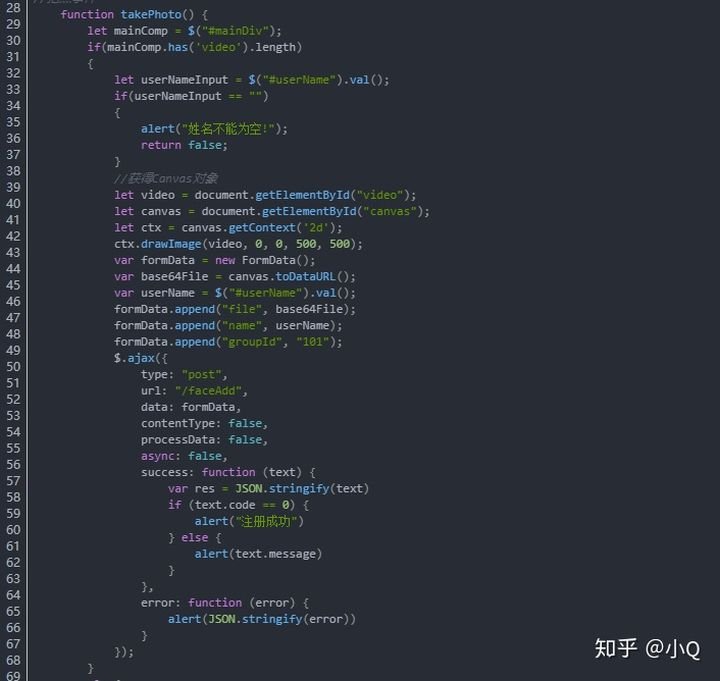
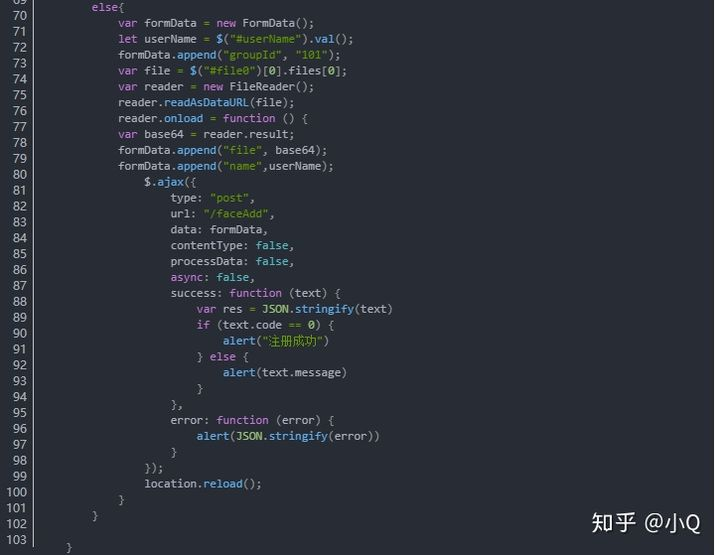
2.4.2 后台解析图片,提取人像特征
台解析前端传过来的图片,提取人像特征存入数据库,人像特征的提取主要是靠FaceEngine引擎。
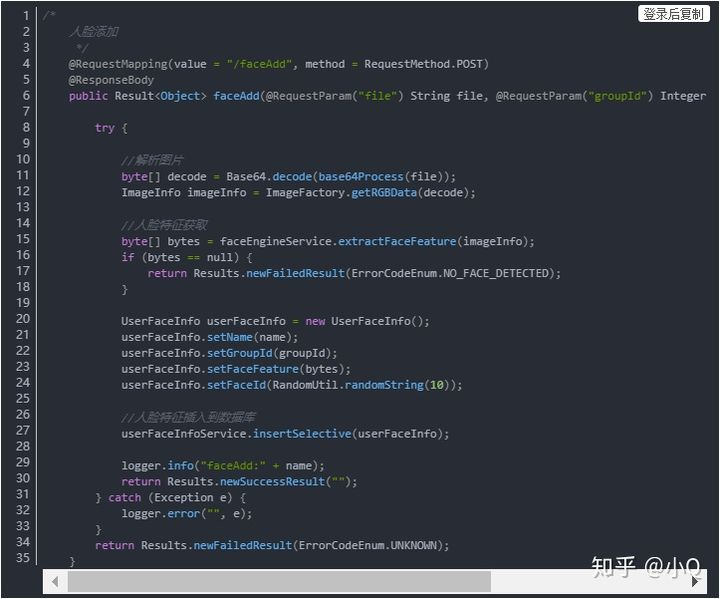
2.4.3 人像特征对比
人脸识别:将前端传入的图像经过人像特征提取后,和库中已存在的人像信息对比分析。
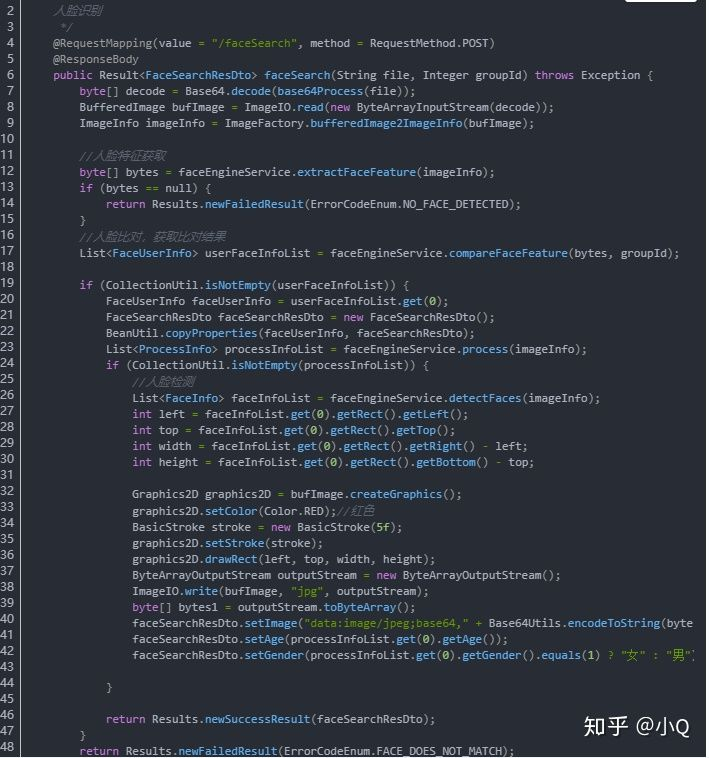
整个人脸识别功能的大致流程图如下:
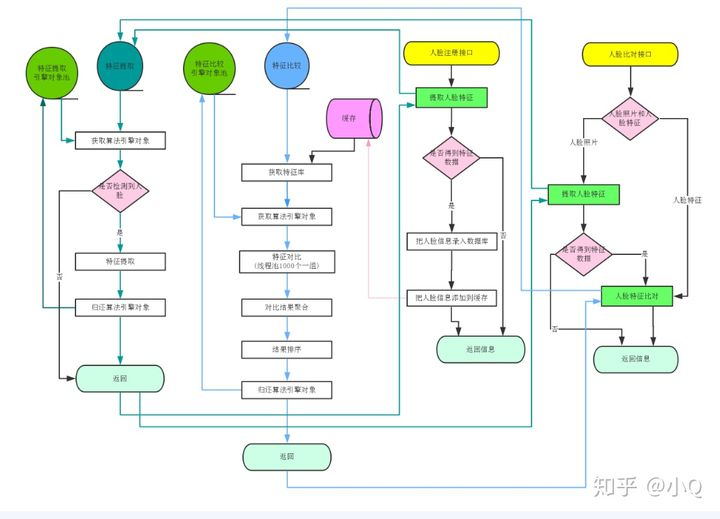
作者:中软高科
链接:https://www.zhihu.com/question/26434245/answer/242126185
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
支持向量机是在高维空间找一个最优分隔平面来进行分类的一种方法。人脸图像一般维度很高,至少上万,如果你用支持向量机,通过核函数继续投影到更高维空间,非常耗时,性能也很差。
神经网络的话,直接用来人脸识别也是不现实的。常用的方法有神经网络的升级版本:深度学习(deep learning)。百度也成立了深度学习的研究院。深度学习的人脸识别,效果非常好,成为了现今研究的热门。
还有就是几何特征识别方法,这些方法都是十几年前的方法了,现在许多简单的方法都比基于规则的几何特征方法来的容易地多,也方便地多。这是一种快被淘汰的方法。
接着,说说我的理解:
人脸识别也是机器学习,人工智能的一个领域。我们把人脸图像的每个像素作为一个特征,便可以用机器学习的方法特征提取与分类。
人脸识别遇到的主要问题是小样本问题。所谓的小样本问题就是人脸图像的维度太高了,一般的照片动则百万像素,而人脸图像的样本一般情况下,也就几十,上百张,相比于百万是很少的。根据经验风险结构风险(http://blog.csdn.net/ice110956/article/details/14002791),以及VC维的知识,对于一般的特征与分类方法都不适用。
于是,人脸识别的相比于其他机器学习不同,其主要研究是如何降维。
相应的方法有子空间方法。所谓的子空间方法,简单的说就是把人脸映射到一个低维的子空间上面,得到维度少的多的特征。简单的子空间方法有PCA(http://blog.csdn.net/ice110956/article/details/14250745),LDA等等。还有基于纹理的LBP(http://blog.csdn.net/ice110956/article/details/10241351),SIFT(http://blog.csdn.net/ice110956/article/details/9373239)等等方法。
最近几年,基于sparse编码以及deep learning的方法在人脸上的运用非常广泛,效果也非常高。
sparse也称为稀疏编码。它是模拟人眼视觉细胞的方法,用很少的样本线性组合为图像。
deep learing(http://blog.csdn.net/zouxy09/article/details/8775360)则是模拟人类的神经网络的方法来实现的。
这两种方法都是从生物学入手的方法,目前有比较广泛的前景。

















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









