 CrossDistil:跨任务知识蒸馏提升推荐系统性能
CrossDistil:跨任务知识蒸馏提升推荐系统性能





 本文提出CrossDistil框架,通过多任务学习中的任务增强和知识蒸馏,解决任务冲突,提取细粒度排序知识。通过引入增强排序任务和校准知识蒸馏过程,以及纠错机制,CrossDistil在推荐系统的多任务环境中实现了性能提升,适用于处理如点击、购买等不同类型的用户反馈预测任务。
本文提出CrossDistil框架,通过多任务学习中的任务增强和知识蒸馏,解决任务冲突,提取细粒度排序知识。通过引入增强排序任务和校准知识蒸馏过程,以及纠错机制,CrossDistil在推荐系统的多任务环境中实现了性能提升,适用于处理如点击、购买等不同类型的用户反馈预测任务。

摘要
多任务学习(Multi-task learning,MTL)在推荐系统中得到了广泛的应用,其中预测用户对项目的各种类型的反馈(如点击、购买)被视为单独的任务,并使用统一的模型进行联合训练。我们主要的观察是每个任务的预测结果可能包含关于用户对项目的fine-grained(细粒度)偏好的task-specific knowledge(任务特定知识)。虽然这种知识可以转移到其他任务中,但在当前的MTL范式下,它被忽视了。相反,本文提出了一个跨任务知识提取框架,试图利用一个任务的预测结果作为指导信号来训练另一个任务。然而,由于任务冲突、大小不一致和同步优化的要求等挑战,以适当的方式集成MTL和KD并非易事。作为对策,我们1)引入具有quadruplet loss functions(四元组损失函数)的辅助任务,以捕获跨任务的细粒度排序信息并避免任务冲突;2)设计calibrated distillation approach(校准蒸馏法),以对齐和提取辅助任务中的知识;3)提出一种新的纠错机制,以支持和促进教师和学生模型的同步训练。在真实数据集上进行了综合实验,验证了该框架的有效性。
介绍
在线推荐系统通常涉及预测各种类型的用户反馈,比如点击和购买。多任务学习(MTL)(Caruana 1997)在这种背景下作为一种强大的工具出现,用于探索任务之间的联系,以改进用户兴趣建模(Ma et al. 2018b; Lu, Dong, and Smyth 2018; Wang et al. 2018)。
常见的MTL模型由低级共享网络和若干个高级个体网络组成,如图1(a)所示,希望共享网络通过共享或强制不同任务参数的相似性来传递“如何对输入特征进行编码”的知识(Ruder 2017)。大多数以前的研究(Ma等人,2018 a;Tang等人,2020 a;Ma et al. 2019)致力于设计具有分支和门控等ad-hoc参数共享机制的不同共享网络架构。在这些模型中,每个任务是在自己的真实二进制标签(1或0)的监督下训练的,试图把positive物品排在negative物品之上。然而,使用二进制标签作为训练信号,这个任务可能无法准确地捕获用户对于带有相同标签的物品的偏好,尽管学习关于这些物品的关系的辅助知识可能有益于总体排序性能。
为了解决这一局限性,我们观察到其他任务的预测可能包含关于如何对相同标签的物品进行排序的有用信息。例如,给定预测“购买”和“喜欢”的两个任务,和标记为“购买:0,喜欢:1”和“购买:0,喜欢:0”的两个物品,“购买”任务或许不能准确地区分它们的相对排名,因为它们的标签都是0。相反,另一个任务“喜欢”将以较大概率(例如0.7)将前一项识别为positive,以较小概率(例如0.1)将后一项识别为positive。基于用户更有可能购买她喜欢的物品的这个事实,我们可以以某种方式利用来自其他任务的这些预测作为传递排名知识的手段。
知识蒸馏(KD) (欣顿、Vinyals和Dean,2015)是一种师生学习框架,学生通过教师的预测进行训练。正如先前研究中的理论分析所揭示的那样(Tang等人,2020 b;Phuong and Lampert 2019),教师的预测,也被称为soft labels(软标签),通常被视为比二进制hard labels(硬标签)信息更多的训练信号,因为它们可以反映“样本是否是真positive(negative)”。从backward gradient(反向梯度)的角度来看,KD可以根据软标签的值自适应地重新缩放学生模型的training dynamics(训练力度)。特别地,在上面的例子中,我们可以将预测0.7和0.1合并到任务“购买”的训练信号中。因此,对于例子中的标记为“购买:0 & 喜欢:0”的样本的梯度将更大,表明它是更有把握的negative样本。通过这个过程,“购买”任务有望对相同标签的物品给予准确的排名。基于上述研究结果,我们利用KD在MTL模型的优化层面上设计了一个新的知识转移范式。由于三个关键和根本性的挑战,它并非微不足道:
- 如何解决蒸馏(提取)过程中的任务冲突问题? 并非所有来自其他任务的知识都是有用的(Yu et al. 2020)。特别地,在在线推荐中,目标任务可能认为用户更喜物品A,因为她购买了物品A而不是物品B,而另一个任务可能相反地认为她更喜欢物品B,因为她将物品B放入收藏夹中而不是物品A。这种冲突的排序知识对于目标任务可能是有害的,并且根据经验可能导致显著的性能下降。
- 如何调整不同任务的预测幅度? 与教师和学生模型具有相同预测目标的普通KD不同,不同的任务可能具有不同大小的positive比率。直接使用另一个任务的预测作为训练信号而不进行对齐可能会误导目标任务产生有偏倚的预测(Zhou et al. 2021)。
- 当教师与学生同步优化,如何加强训练? 普通KD采用异步训练,教师模型已经事先被训练好了。然而,MTL本质上需要同步训练,其中每个任务都是从零开始联合学习的。这表明教师可能训练不足,提供不准确甚至错误的训练信号,导致缓慢收敛和局部最优(Wen、Lai和Qian 2019;Xu等人,2020年)。
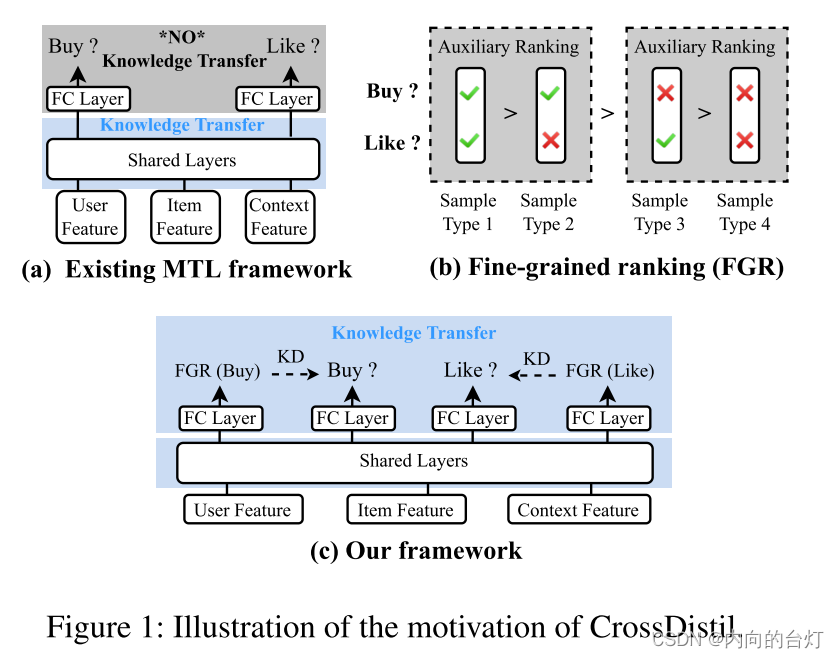
在本文中,我们提出一个新的框架命名为Cross-Task知识蒸馏(CrossDistil)。不同于之前MTL模型,之前的MTL模型是通过共享底层的表征实现知识转移,CrossDistil是在顶层促进知识转移的排名,如图1所示©。解决上述挑战:首先,我们引入增强任务去学习四种样品的订单的排序知识,如图1所示(b)。新任务是基于一个四重损失函数训练的,可以通过只保留有用知识和丢弃有害知识,进而从根本上避免冲突。其次,我们考虑了一个校准过程,它被无缝地整合到KD程序中,以调整不同任务的预测,这是伴随着一个双层的训练算法分别优化参数预测和校正。第三,采用新颖的纠错机制对教师和学生进行端到端的训练,以加快模型训练速度和进一步提高知识质量。我们在大规模公共数据集和从我们的平台收集的真实世界生产数据集上进行了全面的实验。结果表明,CrossDistil达到了最先进的性能。消融研究还彻底剖析了其模块的有效性。
准备工作和相关工程(Preliminaries and Related Works)
Knowledge Distillation(知识蒸馏) (欣顿、Vinyals和Dean,2015)是一个师生学习框架,其中通过模仿教师模型的输出来训练学生模型。对于二元分类,蒸馏损失函数表示为
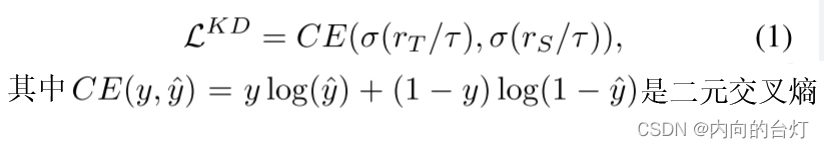
rT和rS表示教师和学生模型的对数,τττ是温度超参数。最新进展(Tang等人,2020 b;Yuan et al. 2020)表明,KD执行特定实例标签平滑正则化,该正则化在对数空间中重新缩放backward gradient(反向梯度),因此可以向学生模型暗示地面真实的置信度,这解释了KD在传统模型压缩之外的更广泛应用中的功效(Kim et al. 2021;Yuan等人,2020年)。
推荐系统中现有的工作出于其原始目的而采用KD,即:将知识从繁琐的教师模型提取到针对相同任务的轻量级学生模型中(Tang和Wang,2018年;Xu等人,2020年;Zhu等人,2020年)。与他们或其他领域的KD工作不同,本文利用KD在不同的任务之间转移知识,由于前面提到的三个主要挑战,这是不平凡的。
多任务学习 (Zhang and Yang 2021)是一种机器学习框架,它通过共享底层网络学习任务不变表示,并通过任务特定网络生成对每个单独任务的预测。它已经收到越来越多的兴趣推荐系统(马等2018b;卢、董和史密斯2018;Wang等人,2018年;Pan et al. 2019)通过预测不同类型的用户反馈来建模用户兴趣。一系列的工作通过设计不同的共享网络架构来寻求改进,例如在任务特定参数上添加约束(Duong et al. 2015;Misra等人,2016年;Yang和Hospedales,2016年)以及分离共享参数和任务特定参数(Ma等人,2018a;Tang等人,2020a;Ma等人,2019年)。与他们不同的是,我们借助KD在特定任务网络(task-specific networks)上跨任务转换排序知识。值得注意的是,我们的模型是一个通用框架,可以作为现成MTL模型的扩展。
Proposed Model(提出的模型)
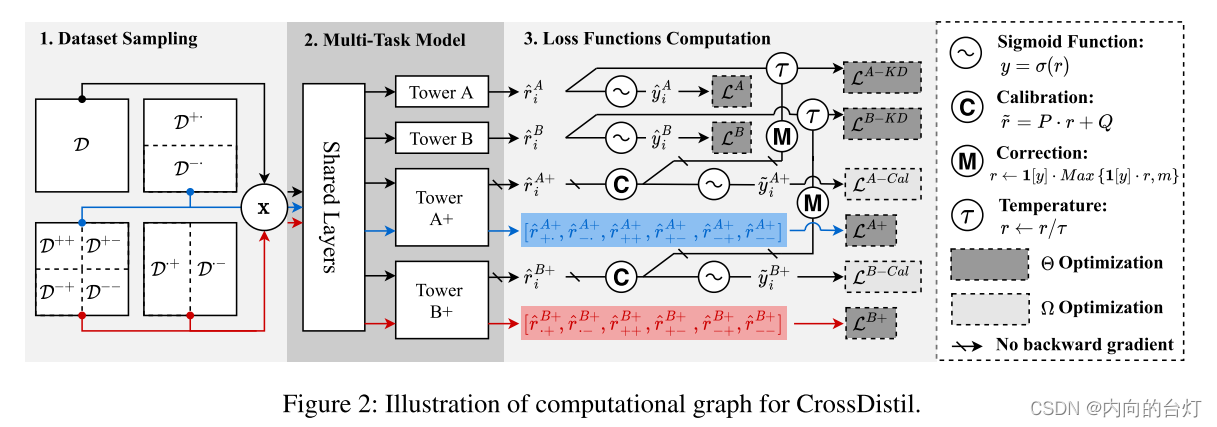
图2:CrossDistil的计算图图示。
Task Augmentation for Ranking(排序任务增强)
本文主要研究多任务学习预测不同的用户反馈(如点击、喜欢、购买、浏览),并考虑两个任务,记为任务A和任务B,以简化说明。如图2的左图所示,我们首先根据任务标签的组合将训练样本集分成多个子集:
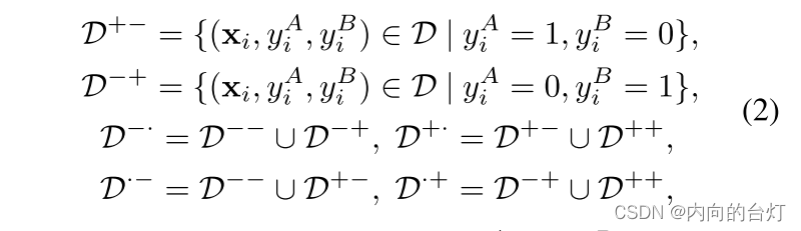
其中xxx是输入特征向量,yAy^AyA和yBy^ByB分别表示任务A和任务B的硬标签。目标是将正样本排在负样本之前,这可以表示为二分次序,任务A的x+⋅x_{+·}x+⋅ ≻ x−⋅x_{−·}x−⋅和任务B的x⋅+x_{·+}x⋅+ ≻ x⋅−x_{·−}x⋅−,其中x+⋅∈D+⋅x_{+·}∈ D^{+·}x+⋅∈D+⋅,依此类推。注意,这些二分顺序在不同任务之间可能是矛盾的,x+−x_{+-}x+− ≻ x−+x_{−+}x−+表示任务A,x+−x_{+-}x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 904
904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









