







摘要
多视图聚类是将图划分为多个视图,这些视图往往提供更全面但复杂的信息,近年来得到了很多关注。虽然人们已经对多视图聚类做了一些研究,并取得了不错的效果,但大多数研究都采用浅层模型来处理多视图中的复杂关系,这严重束缚了多视图信息的建模能力。本文首次尝试将深度学习技术应用于属性多视图聚类(attributed multi-view graph clustering),提出了一种新的任务导向One2Multi图自动编码器聚类框架。One2Multi图自动编码器能够通过使用一个有信息的图视图和内容数据来重构多个图视图来学习节点嵌入。因此,可以很好地捕获多个图的共享特征表示。此外,提出了一种自训练的聚类目标,为了迭代改进聚类结果。通过将自训练和自动编码器的重构集成到一个统一的框架中,我们的模型可以联合优化适合于图聚类的聚类标签的分配和嵌入。在真实的属性多视图数据集上进行了实验,验证了模型的有效性。
介绍
图聚类是图分析[17]中的一个基本任务,其目的是将一个图划分为若干个紧密连接的不相交的社区或群。图聚类技术在实践中得到了广泛的应用,如群体分割[5]、通信网络结构分析[23]、社交网络中的社区发现[21]等。大多数现有的图聚类方法只关注于处理一个图[12,20]。然而,真实的世界的图形数据要复杂得多。也就是说,人们通常需要使用多视图图而不是单视图图来更好地表示真实的图数据[16],其中每个图视图表示节点之间的一种类型的关系。以学术网络为例,一个图形视图可以表示合著者关系,而另一个视图可以表示共同会议关系。此外,作者还可以与代表性关键词相关联作为其属性。这种复杂图通常被称为属性多视图(multi-view graph),它以一种互补和全面的方式对交互系统进行建模,并具有更精确的图聚类的巨大潜力。
关于属性多视图聚类,已有的研究工作可以分为两类。一种类型的工作在于基于图分析的方法,其目的是最大化不同视图之间的相互一致性,以便将图划分为组。另一个工作流主要采用图嵌入技术从多视图数据中学习节点的紧凑表示,随后使用传统的聚类方法,例如k-means。这些方法在许多应用中取得了良好的效果。然而,之前讨论的这类方法都被认为是浅层模型,其揭示复杂图数据中的深层关系的能力有限。此外,上述方法很少关注节点属性信息。
最近,图神经网络(GNN)在一些图分析任务上表现出了强大的性能,例如节点分类和聚类。然而,大多数GNN是针对单视图开发的。此外,也有一些工作将GNN扩展到多视图环境,而它们是在半监督场景下设计的,用于分类任务。尽管GNN在图分析中取得了巨大的成功,但到目前为止,人们对GNN在无监督的属性多视图聚类任务中的研究仍然很少。
将GNN应用于属性多视图聚类并不是一个简单的任务,它将面临两个挑战。
- 如何在无监督环境下有效地融合多视图信息?显然,只有一个视图信息不足以实现精确的图聚类,因为多视图提供了丰富的边信息。一种直接的融合方法是开发一个multi2multi模型。即,开发了多个编码器和解码器,并且每个编码器和解码器用于一个视图。然而,由于引入了包含在不同视图中的噪声,这种直接的方法不是有效的。更重要的是,multi2multi模型仅单独提取每个视图的表示,而共享表示对于我们的任务可能更重要。
- 如何使GNN学习到的嵌入更适合聚类任务?节点嵌入和聚类通常是两个独立的任务。节点嵌入的目的是重构原始图,因此学习的节点嵌入不一定适合节点聚类。因此,我们需要以统一的方式优化节点嵌入和聚类。
观察真实的多视图数据可以发现,尽管多视图信息从不同的角度反映了节点之间的关系,但它们应该具有一些共同的节点特征。此外,在许多场景下,通常存在一个信息量最大的视图来控制聚类的性能,这也在文献[3,13,22]中得到了证实。例如,在学术网络中,合著者关系视图和联合会议关系视图都反映了作者的研究兴趣,而联合会议视图由于揭示了共同的研究兴趣,因此信息量更大,从而产生了比其他视图更好的聚类性能[3]。
针对这一问题,本文提出了一种新的One2Multi图自动编码器框架,用于属性多视图聚类。该模型的基本思想是从信息量最大的视图和内容数据中提取共享表示,然后利用共享表示重构所有视图。基于这种思想,我们设计了一种新型的One2Multi图自编码器,它由一个编码器和多个解码器组成。具体地说,它利用多视图结构和节点内容来学习节点表示,通过一个多层图卷积网络(GCN)编码器从信息量最大的视图学习节点表示,以及多个图解码器重构所有视图。此外,设计了一个自训练的聚类目标,使当前聚类分布逼近更适合聚类任务的目标分布。该模型通过对重构损失和聚类损失进行联合优化,可以同时优化节点嵌入和聚类,并在统一的框架下相互改进。
我们的主要贡献可归纳如下:
- 据我们所知,这是第一次将图深度学习技术应用于属性多视图聚类任务,具有很大的应用潜力。
- 我们提出了一种新的One2Multi自动编码框架用于属性多视图聚类。One2Multi图自动编码器提供了一个有效的深度框架来集成多视图图形结构和内容信息。同时,该框架对多视图嵌入学习和图聚类进行了联合优化,并相互促进。
- 在真实世界属性多视图上的实验表明,该算法优于现有的图聚类算法。
2 问题定义
在本节中,我们将介绍一些将在本文中使用的符号和定义。
定义1:属性多视图(Attributed Multi-view Graph)。
属性多视图表示为
G
=
{
V
,
E
1
,
.
.
.
,
E
M
,
X
}
G=\{V, E_1, ..., E_M, X\}
G={V,E1,...,EM,X},其中
V
=
{
v
i
}
i
=
1
n
V=\{v_i\}_{i=1}^{n}
V={vi}i=1n有图中一系列节点组成,
e
i
,
j
(
m
)
∈
E
m
e_{i, j}^{(m)}∈E_m
ei,j(m)∈Em表示第m个图视图中节点i和节点j之间的连接。图G的拓扑结构可以用多个邻接矩阵
{
A
(
m
)
}
m
=
1
M
\{A^{(m)}\}_{m=1}^{M}
{A(m)}m=1M表示,其中如果
e
i
,
j
(
m
)
∈
E
m
e_{i, j}^{(m)}∈E_m
ei,j(m)∈Em,
A
i
,
j
(
m
)
=
1
A_{i, j}^{(m)}=1
Ai,j(m)=1;否则
A
i
,
j
(
m
)
=
0
A_{i, j}^{(m)}=0
Ai,j(m)=0。
x
i
∈
X
x_i∈X
xi∈X表示每个节点
v
i
v_i
vi关联的属性值。
定义2:属性多视图聚类(Attributed Multi-view Graph Clustering)。
属性多视图聚类的目的是将属性多视图中的节点划分为预定义的K个不相交的簇{C1,C2,···,CK},使得同一簇内的节点一般为:(1)在多视图结构上彼此接近,而在其它方面彼此远离;以及(2)在节点属性方面彼此接近。
3 提出的模型
在本节中,我们提出了用于多视图图聚类的One2Multi graph Autoencoder模型(O2MAC)。
3.1 Overview
O2MAC模型的基本思想是开发一个One2Multi图自编码器,从属性多视图图中学习节点表示,然后通过自训练的聚类目标改进节点表示以完成聚类任务。
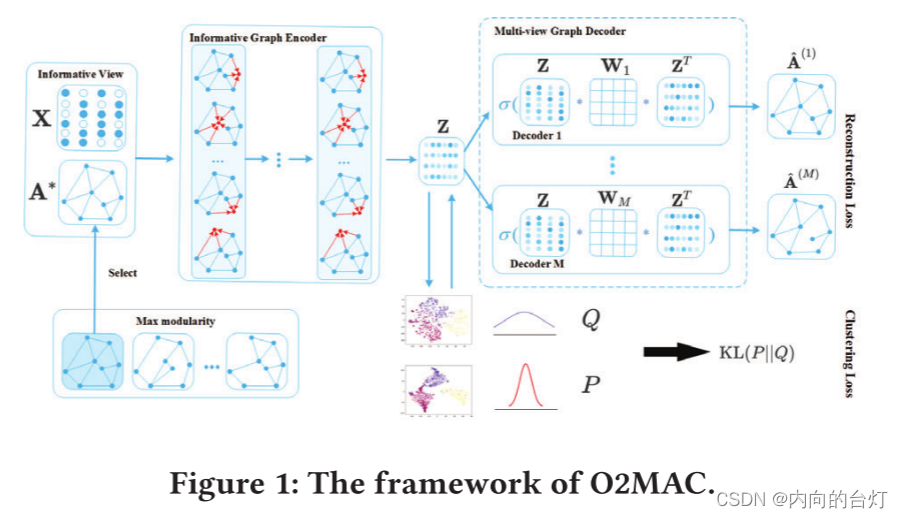
图1显示了O2MAC的总体框架。我们的模型主要由两部分组成:One2Multi图自动编码器和自训练图聚类。One2Multi图自编码器由一个有信息的图编码器和多视图解码器组成。利用启发式度量模块(heuristic metric modularity),我们选择信息量最大的视图作为图编码器的输入,图编码器将图的结构和节点内容编码成节点表示。然后设计一个多视图解码器对表示进行解码,以重构所有视图。由于One2Multi图编码器设计精巧,不仅学习了共享表示,而且吸收了不同视图的结构特点。此外,我们使用软标签(由学习嵌入本身生成),以监督学习的编码器参数和聚类中心。在统一的框架下对多视图的嵌入和聚类进行优化,从而得到一个有信息的编码器,使表示更适合聚类任务。
3.2 One2Multi Graph Convolutional Autoencoder
为了在一个统一的框架下表示多视图结构
A
(
1
)
,
.
.
.
,
A
(
M
)
A^{(1)}, ..., A^{(M)}
A(1),...,A(M)和节点内容
X
X
X,我们提出了一种新的One2Multi graph Autoencoder(O2MA)结构。在该结构中,所有视图共享一个图卷积编码器,从一个有信息的图视图和内容数据中提取共享表示,并设计一个多视图解码器(multi-decoder),从共享表示中重构多视图数据。整合多视图信息的最直接策略是建立一个multi2multi模型,该模型中使用多个编码器(multiple encoders)学习多个视图(multiple views)的混合表示,然后使用混合表示重构多视图(multi-view graphs)。然而,这种multi2multi模型有几个缺点。
(1)每个视图表示都是单独学习的,不能很好地提取共享表示。
(2)多视图信息引入了大量噪声,不利于共享表示学习。
(3)从所有视图中学习也很耗时。
信息图卷积编码器。(Informative graph convolutional encoder.) 由于不同的图视图从不同的方面表示同一组节点之间的关系,并且内容信息被所有图视图共享,因此视图之间存在共享信息。此外,在许多场景中,通常存在一个信息量最大的视图来控制聚类性能。因此,可以从信息量最大的图视图和内容数据中提取信息视图与其他视图之间的共享信息,然后利用这些共享信息重构所有图视图。
假设,以信息量最大的图视图
A
∗
∈
{
A
(
1
)
,
.
.
.
,
A
(
M
)
}
A^*∈\{A^{(1)}, ..., A^{(M)}\}
A∗∈{A(1),...,A(M)}和节点内容信息X为输入,重构所有图视图。请注意,在许多应用中,我们可以使用先验知识来选择信息图表视图。在这里,不失一般性,我们提供了一个启发式的度量,模块化(modularity)[11],以选择信息量最大的视图。具体地说,首先将每个单视图图的邻接矩阵和内容信息分别输入到GCN层学习节点嵌入,然后对学习到的嵌入进行k-means运算得到其聚类指标。基于聚类指标和邻接矩阵,计算每个图视图的模块化得分,并选择得分最高的图视图作为信息量最大的视图。使用模块化的原因是它提供了一个客观的度量来评估聚类结构。为了在一个统一的框架中使用图结构
A
∗
A^*
A∗和节点属性
X
X
X,我们将GCN层用作图编码器。GCN将卷积运算扩展到谱域(spectral domain)中的图形数据,并通过谱卷积(spectral convolution)函数
f
(
Z
(
l
)
,
A
∗
∣
W
(
l
)
)
f(Z^{(l)}, A^*|W^{(l)})
f(Z(l),A∗∣W(l))学习逐层变换:

多视图图解码器。(Multi-view graph decoder.) 为了监督编码器提取所有视图共享的表示,提出了一种多视图图解码器,用于从表示
Z
Z
Z中重构多视图图数据
A
^
(
1
)
,
.
.
.
,
A
^
(
M
)
\widehat{A}^{(1)}, ..., \widehat{A}^{(M)}
A
(1),...,A
(M)。
如图1的多视图图解码器部分所示,我们的解码器由M个视图专用(view-specific)解码器
{
p
(
A
^
(
m
)
∣
Z
,
W
m
)
}
m
=
1
M
\{p(\widehat{A}^{(m)}|Z, W_m)\}_{m=1}^M
{p(A
(m)∣Z,Wm)}m=1M组成,预测视图m中两个节点之间是否存在链接,其中
W
m
∈
R
D
×
D
W_m ∈ R^{D×D}
Wm∈RD×D是视图m的视图专用(view-specific)权重。
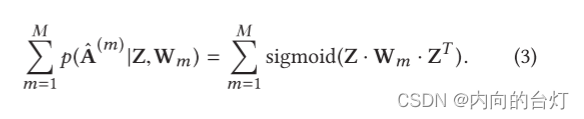
重建损失(生成损失)。(Reconstruction loss.) 对于多视图图自动编码器,我们通过以下方式最小化每个图视图数据的重建误差的总和:
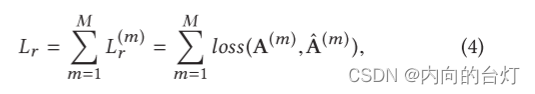
其中
L
r
(
m
)
L_r^{(m)}
Lr(m)是视图m的重建损失,
L
r
L_r
Lr是所有视图的重建损失。由于解码器的多视点结构,在反向传播过程中,多个解码器的梯度将通过信息图编码器传播。因此,当向前传播被处理时,图编码器将提取所有视图的共享表示。
这个模型也可以看作是多任务学习[2]。多视图图解码器为信息图编码器提取共享表示提供多任务监督信号,使共享表示更加全面和通用。
3.3 子训练聚类(Self-training Clustering)
上述One2Multi图卷积自编码器可以将属性化多视图图编码为一个紧凑的表示。然而,嵌入空间中的节点邻近性是为了保持原始多视图数据的局部结构,这可能不能保证适合于聚类。对于群集来说,一个好的数据分布是同一个群集内的节点密集地聚集在一起,并且不同群集之间的边界是明显的。因此,有必要引入其他目标来指导嵌入学习过程。受DEC [26]的启发,我们采用自训练聚类目标,利用“高度可信”节点作为软标签来监督图聚类过程。
除了优化重建损失之外,我们将隐藏嵌入输入到自训练聚类目标中,该自训练聚类目标最小化以下目标:
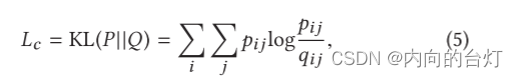
其中KL(·|·)是两个分布之间的Kullback-Leibler散度,Q是软标签的分布,
q
i
j
q_{ij}
qij通过学生的t-分布(t-distribution)[10]来测量,以指示节点i的嵌入
z
i
z_i
zi和聚类中心
μ
j
μ_j
μj之间的相似性:
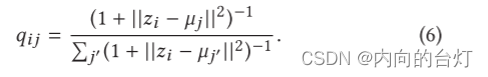
它可以看作是每个节点的软聚类分配分布。等式5中的
p
i
j
p_{ij}
pij是目标分布,定义如下:
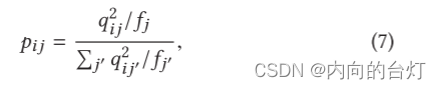
其中
是软簇频率,用于归一化每个质心的损失贡献,以防止大簇扭曲隐藏的特征空间。(is the soft cluster frequencies to normalize the loss contribution of each centroid to prevent large clusters from distorting the hidden feature space.)正如我们所看到的,目标分布P将Q提升到二次幂以获得更密集的分布。通过最小化Q和P之间的KL散度,可以使Q的分布更加密集。实际上,在4.4小节中,我们观察到“highly confident”节点在KL散度最小化开始时对梯度的贡献更大。“highly confident”节点指示节点具有属于某个群集的高概率,该群集由等式6计算。这种现象可以被解释为半监督训练,这已经在GCN [6]中被非常有效地证明。
总体目标函数。(Overall objective function.) 我们联合优化One2Multi图自动编码器嵌入和聚类学习,并且总目标函数被定义为:

其中
γ
>
0
γ>0
γ>0是控制嵌入空间扭曲程度的系数,我们让所有实验的
γ
=
0.1
γ = 0.1
γ=0.1。
3.4 优化(Optimization)
我们首先在没有自训练聚类部分的情况下预训练One2Multi图自动编码器,以获得训练良好的嵌入 Z Z Z,如3.2小节所述。然后执行自训练聚类目标以改进这种嵌入。为了初始化聚类中心,我们对嵌入节点 Z Z Z执行标准k-means聚类,以获得k个初始质心 { μ j } j = 1 k \{μ _j\}^k_{j = 1} {μj}j=1k。具体而言,有三种参数需要更新:One2Multi图编码器的权值 W ( l ) W^{(l)} W(l)和 W 1 , ⋅ ⋅ ⋅ . W M W_1, ···. W_M W1,⋅⋅⋅.WM,聚类中心 μ μ μ和目标分布 P P P。
更新O2MAC的权重和聚类中心。(Update O2MAC’s weights and cluster centers.) 固定目标分布
P
P
P并给定
N
N
N个样本,
L
c
L_c
Lc相对于聚类中心
μ
j
μ_j
μj的梯度可以计算为:
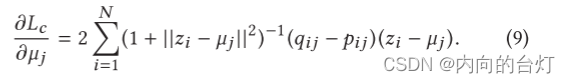
然后给定学习率
λ
λ
λ,
μ
j
μ_j
μj更新为

通过下式来更新第m主题视图特定解码器的权重
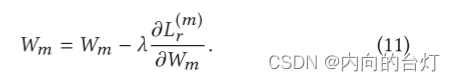
如我们所见,
W
m
W_m
Wm的更新仅与视图
m
m
m重建损失有关,因此,视图特定解码器的权重可以捕获视图特定局部结构信息。
然后,图编码器的权重更新为
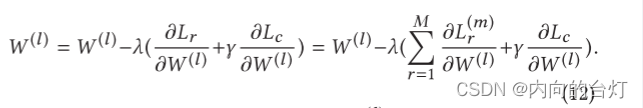
可以观察到
W
(
l
)
W^{(l)}
W(l)的更新与所有视图的重建损失有关,使得编码器的权重可以提取所有视图共享的表示。
更新目标分布。(Update target distribution.) 用作"groundtruth"软标签的目标分布P还取决于预测软标签。因此,为了避免自训练过程中的不稳定性,应当每T次迭代使用所有嵌入节点来更新P。我们根据等式6和等式7更新P。当更新目标分布时,分配给
v
i
v_i
vi的标签通过下式获得

其中
q
i
j
q_{ij}
qij通过公式6计算。如果目标分布的两个连续更新之间的标签分配变化(以百分比表示)小于阈值
δ
δ
δ,则停止训练过程。最后一次优化后的
Q
Q
Q值可以得到聚类结果。
4 实验(EXPERIMENTS)
4.1 数据集
- ACM:这是ACM数据集的论文网络(paper network)。我们利用共论文(两篇论文由同一作者撰写)关系和共主题(两篇论文包含相同主题)关系来构造一个两视图。论文特征是由关键词表示的词袋的元素。我们使用论文的研究领域作为真实数据。
- DBLP:这是来自DBLP数据集的作者网络。确定了三种观点,包括共同作者(两名作者共同撰写论文)、共同会议(两名作者在同一会议上发表论文)和共同术语(两名作者以相同术语发表论文)。作者特征是关键词所代表的词袋的元素。为了评估该方法,我们使用作者的研究领域作为地面事实(ground truth)。
- IMDB:这是来自IMDB数据集的电影网络。我们利用共同演员(电影由同一演员扮演)关系和共同导演(电影由同一导演导演执导)关系来构造一个两视图。电影特征对应于由情节表示的词袋的元素。为了评估该方法,我们使用电影的类型作为地面事实。
数据集的详细描述见表1。

4.2 Baselines
- LINE [19]:它是一种经典的单视图图嵌入方法。对于单视图方法,我们分别在每个图视图上执行这些方法,并报告最佳结果。
- GAE [7]:它是一种单视图图自动编码方法。
- X-avg:为了利用网络的多个视图,我们使用X方法学习每个视图上的节点表示,然后平均所有学习的表示。
- MNE [27]:一种可扩展的多视点网络嵌入模型。对于所有的多视图图嵌入/聚类方法,我们使用多视图图邻接矩阵作为输入。
- PMNE [8]:我们将我们的方法与PMNE提出的所有三种多视角网络嵌入模型进行了比较,PMNE(n)、PMNE(r)和PMNE(c)。
- RMSC [25]:一种基于低秩稀疏分解的鲁棒多视角谱聚类方法。
- PwMC and SwMC [14]:PwMC是一种参数加权多视图图聚类方法,SwMC是一种自加权多视图图聚类方法。
- O2MA:O2MAC的一种变体,其目标函数中不包含聚类损失。
- O2MAC:我们提出的属性多视图图聚类方法。
参数设置和指标。(Parameter settings and Metrics.) 对于DBLP和IMDB数据集,我们对所有自动编码器相关模型(GAE、O2MAC、O2MA)进行了1000次迭代训练,并使用Adam算法对其进行了优化。由于ACM是一个较小的数据集,我们迭代250次进行训练。自动编码器相关型号的学习率λ设置为0.001。所有嵌入方法的维数均为32。对于GAE,它具有与我们的编码器相同的结构。对于O2MAC,收敛阈值设置为δ = 0.1%,更新间隔T = 20。对于其余基线,我们保留相应论文中描述的设置。由于所有的聚类算法都依赖于初始化,我们使用随机初始化重复所有方法10次,并报告平均性能。此外,我们还采用了四个指标来验证聚类结果:accuracy(Acc), F-score (F1), NMI and ARI [25]。

4.3 图聚类性能(Graph Clustering Performance)
三个数据集的结果见表2。可以看出,O2MAC和O2MA的结果在几乎所有四个指标上都显著优于其他基线,表明了我们提出的模型的有效性。然后,通过比较O2MA和GAE(GAE-avg)的结果,我们得出结论:我们提出的One2Multi图自编码器是一种更有效的融合多视图信息的图神经网络。此外,与O2MA相比,O2MAC在ACM和DBLP数据集上取得了更好的聚类结果,这表明自训练聚类目标在经过有效的预训练后,聚类性能可以进一步提高。同时,我们也注意到O2MA在IMDB数据集上的表现优于O2MAC。原因是在IMDB上很难获得“highly confident”的节点。在这种情况下,这些“highly confident”节点可能会将低置信度节点限制在错误的聚类中。为了避免这种情况,我们可以在这些数据集上设置 γ = 0 γ = 0 γ=0,即:仅使用O2MA版本。
关于基线,我们有以下意见。
首先,嵌入方法明显优于其他方法,因此图嵌入是一种很有前途的解决图聚类问题的方法。
第二,深度学习方法(即,GAE)实现了优于其他基准的竞争结果。但是,它只能利用单视图和内容信息。一个设计良好的集成了多个图视图的深度神经网络可能会取得令人满意的结果。
第三,简单的多视图图平均操作X-avg没有改善结果,甚至降低了性能。因为X-avg是两步融合方法,并且该混合操作可能引入噪声。因此,设计一个端到端的融合模型是聚类任务的必要条件。
4.4 模型分析(Model Analysis)
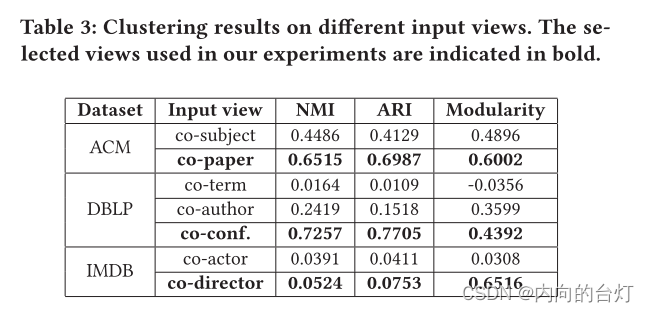
在本小节中,我们将分析模型的各种属性。我们首先验证使用模块化[11]来选择信息视图的必要性。我们使用每个图视图作为O2MA的输入,并在三个数据集上重建所有图视图,并在表3中报告其在图聚类任务上的结果。可以观察到,如果我们将具有更高模块值的图视图馈送到编码器中,我们的模型将获得更好的结果。验证了模块化是选择信息视图的可行方案。
在我们的模型中,我们融合了多个图视图来提高聚类的性能。为了进一步研究多视图对聚类任务中学习嵌入的影响,我们通过在DBLP数据集中逐个添加图视图来仔细检查O2MA的性能。这三种观点是联合会议、联合术语和联合论文,它们按顺序添加到模型中。图2(a)是O2MA的四个指标性能,带有附加视图。四个指标的结果表明,随着视图的逐个添加,模型的性能稳定提高。因此,O2MA提供了一个灵活的框架来利用更多的图视图。
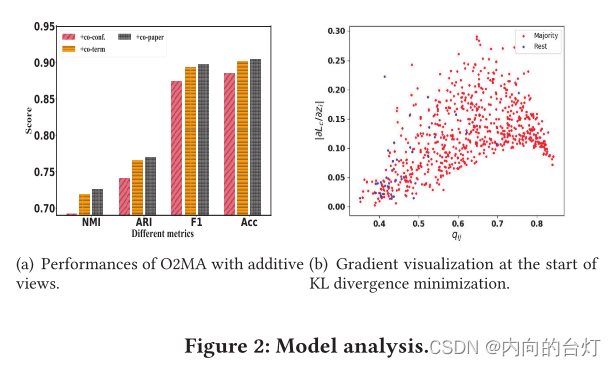
自训练聚类损失的潜在假设是初始分类器的高置信度预测大多是正确的,并且它们将对梯度贡献更大。为了验证我们任务中的这一假设,我们绘制了
L
c
L_c
Lc相对于每个嵌入点的梯度大小,

,而不是其软分配
q
i
j
q_{ij}
qij,分配给随机选择的ACM簇j(图2(b) )。我们观察到,更靠近簇中心的节点(large
q
i
j
q_{ij}
qij)对梯度贡献更大(具有更高的值),并且梯度将通过GCN编码器传播,这使得邻域节点具有相似的嵌入。我们还将节点的大部分类标为红色,其余类标为蓝色。可以看到,高置信度(highly confident)区域中的大多数节点是红色的,并且蓝点大多在低置信度区域中。因此,高置信度的“right”节点将指导训练过程,这反过来又有助于改善低置信度的节点。
5 结论
本文研究了属性多视图图聚类问题,目的是利用图的多视图和属性信息,将图划分为若干个互不重叠的簇。为了解决这一问题,提出了一种新的One2Multi图聚类自动编码方法O2MAC。O2MAC利用单视图图卷积编码器和多视图图结构解码器将属性化的多视图图编码到低维空间。此外,引入自训练聚类损失来监督具有高置信度节点的编码器,使特征空间更适合聚类。通过与现有算法的对比实验,验证了该方法的有效性。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









