







摘要
实例类型信息与执行推理和获得关于知识图谱(KGs)中的实体的进一步信息特别(particularly)相关。但是,在自动化或即付即用的KG构造过程中,某些实体中的实例类型可能不完整或缺失。以前的工作主要集中在基于KG中的语句将实体和关系表示为嵌入。虽然计算出的嵌入对语义描述进行了编码,并保留了实体之间的关系,但这些方法的重点往往不在于预测模式知识,而在于预测实例之间缺失的语句以完成KG。为了填补这一空白,我们提出了一种方法,首先学习一种适合预测实例类型断言的KG表示。然后,我们的解决方案实现了一个神经网络架构,根据所学到的表示预测实例类型。结果表明,与现有的方法相比,我们的实体表征在与KG中的类的关联方面更容易分离。由于这个原因,在大量的KG上预测实例类型的性能,特别是在具有大量类别的跨领域KG上,在F1-score方面明显优于以前的工作。
1 介绍
知识图谱(KG)使用模式断言或公理来建模概念和关系,这些概念和关系是描述KG中的实体及其连接的基础。这些模式断言通常定义类、关系和类成员关系之间的含义和关联。此外,推理器可以使用模式公理从KG中逻辑地推导出额外的事实,或者检测KG中编码的语句之间的不一致性。因此,在KG中拥有完整的模式断言是充分利用图中语义能力的关键,然而,由于多种原因,这些断言可能是不完整的。例如,以即付即用方式创建的KG可能会受到这种不完整性的影响,因为新的实例、类和属性有时会添加(added)到KG中,其中包含在插入(insertion)时可用的部分信息。当从非结构化或不完整的源构建KG时,可能发生类似的情况。此外,一些模式断言(schema assertions)需要专家提供的特定领域知识,但是对于具有大量类的知识团体来说,手工完成它们不是可行的解决方案。
尽管模式断言具有相关性,但最近提出的KG嵌入的进展是为完成实例级声明而定制的,即增强KG中实体或实例的描述。为了解决模式断言的不完整性,人们提出了其他的解决方案,这些解决方案主要是针对实例类型预测的问题。为此,有的人设计了特定的方法,有的人也应用了上述的一些解决方案。尽管如此,Jain等人最近的工作表明,最先进的方法对于预测实例类型并不有效,特别是在考虑类层次结构中的特殊类时。
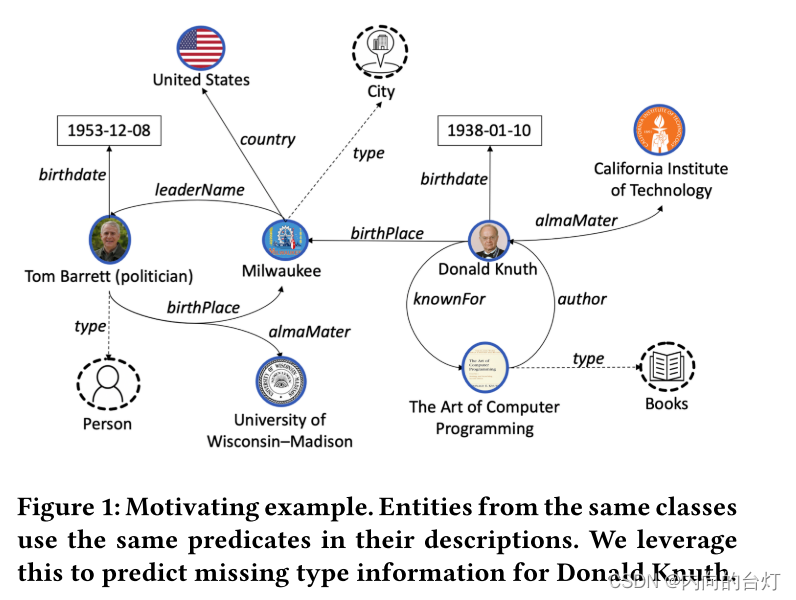
图1:激励性示例。来自相同类的实体在它们的描述中使用相同的断言。我们利用这个来预测Donald Knuth的缺失类型信息。
在本文中,我们介绍了一种称为Ridle的方法,该方法学习实体的表示,并被定制为预测实例类型断言。这项工作的假设是,来自同一类的实例在KG中用相同的断言描述,这反过来又允许预测相似实例的类型。为了说明这一点,考虑图1中的KG,其中实体Donald Knuth不与任何类关联。然而,Donald Knuth的描述与Person类型的实体Tom Barret有一些共同的关系,例如出生日期、出生地点和母校。相反,Donald Knuth与Country类型的实体Milwaukee没有共同的关系。基于此信息,Donald Knuth也可能属于类Person。请注意,Donald Knuth和Tom Barret的断言对象是不同的,不过,只要看看它们描述中使用的关系,我们就可以预测Donald Knuth的类附属关系(affiliation)。此示例显示实例和关系的出现次数可以是实例类型的有效预测器。Ridle的基本思想是利用这些特性并计算关系出现的目标分布以学习KG的压缩表示,其中该分布被潜在地编码。我们使用一个随机因子分解模型(stochastic factorization model),即限制玻尔兹曼机(RBM),学习这种目标分布。在下游阶段,我们使用这些表示与现有模式语句的信息相结合,使用监督式神经网络架构来预测缺失的实例类型断言。虽然大多数方法本质上是直推的(transductive),因此不能有效地泛化到看不见的实体,但我们的方法是归纳的(inductive),允许它为模式断言生成表示和预测,即使存在未知实体。
我们在20个KG上进行了广泛的评估,包括4个跨领域KG和16个特定类别KG,允许详细分析所提出的方法的特征。我们将Ridle与具有不同学习范式的最先进方法进行比较[5,23,24,28,32]。我们报告了F1-score,正如之前的类似研究所做的[24,28]。结果表明,与当前最先进的方法相比,Ridle在预测实例类型断言(尤其是跨域知识图)方面的平均性能更好,因此为预测模式断言(predicting schema assertions)提供了新的基线(baseline)。
2 相关工作
我们的工作集中在学习知识图谱中实体的表示以预测实例类型断言。SDType [24]是一种启发式的基于链接的类型推理机制,专注于实例类型预测。正如相关著作[13,26]所指出的,传统的推理方法往往与噪声数据、错误或不可预见的模式作斗争。启发式方法SDType在计算中使用一种实际使用方案的统计分布,从而使其更具健壮性。统计分布的这种稳健性特征也被用在本文中,以处理数据中的噪声。与SDType不同,我们使用随机分解模型来学习实体在使用实例关系上的表示。基于这些表示,我们学习了一个预测实例类型断言的模型。RDF2Vec [28]是语言模型Word2Vec [19,20]的改编,通过使用随机游走和Weisfeiler-Lehman Subtree RDF Graph Kernels(图内核)来创建节点序列,(什么样的节点序列呢:)传递给Word2Vec以学习实体和关系的低维数值表示的节点序列。尽管先前使用RDF2Vec [4,14,31]进行实例类型预测的研究取得了令人鼓舞的结果,但我们认为RDF2Vec特别适合于度量实体的语义相似度[6,28,29],以及知识图谱之间的实体对齐(alignment),这是由于使用了Word2Vec并因此能够准确地表示实体之间的关系。然而,使用随机游走方法,RDF2Vec的性能根据知识图的拓扑和随机游走策略而显著变化。相反,我们基于目标分布来学习特征,因此,它不受知识图谱的拓扑或所选择的随机游走策略的负面影响。我们更喜欢如RDF2Vec所学习的实体的低维表示,但是考虑到完整三元组与模式断言的预测无关,并且因此考虑到RDF2Vec对于该任务来说太复杂了。在实例类型预测的进一步相关工作中,实体仅根据所使用的关系进行分类[18]。对于实体关系的单独使用,结果是非常有希望的。然而,该方法忽略了语义关系,以及在图关系之间的相关性中表达的潜在特征。相反,我们希望通过在实体关系的使用上使用目标分布来提供实体的表示,从而基于实体的关系使用来识别潜在特征。
在这项工作中,我们使用受限玻尔兹曼机(RBM)来学习实体关系使用上的目标分布,从而允许使用隐藏层作为实体表示的潜在特征。RBM在过去已经被应用,特别是用于维度缩减[11]、学习和重构输入的稀疏表示[27]、协同过滤[2,30]和链接预测[16,33]。虽然最初尝试将RBM应用于特征学习[15,22],但它尚未应用于学习知识图谱中的特征。此外,我们想提到的是,在这种情况下,RBM共享与自动编码器类似的想法,但使用随机单位。与自动编码器重构精确的输入不同,我们尝试识别所用关系的分布以确定潜在特征,我们将使用这些潜在特征作为实体的表示。
3 Proposed Approach: RIDLE
对于预测实例类型断言的下游任务,我们需要实体的语义上有意义的表示。我们的假设是实例使用的关系与它们的分类最相关。例如,考虑图1中的知识图谱,我们注意到Donald Knuth具有birthplace和birthdate等关系。只知道这些关系,已经给出了一个提示,这个实例很可能是person类型的,因为这两个关系通常只被Person类的实体使用。完整描述,即:Donald Knuth确切出生在哪个地方或哪个日期,与预测实例类型不太相关。同样地,我们注意到在这个例子中,某些关系比其他关系更可能在某些类型的实例的上下文中共同出现,因此,所使用的关系的分布可以用于预测类成员资格。
我们设计了一种方法来利用知识图谱中实例和关系之间关联的上述两个特性。我们建议的方法,Ridle(关系实例分配学习),能够学习知识图谱的分布关系,接着(in turns),允许预测实例类型。图2描绘了Ridle的两个组件:(a)基于知识图谱中实例关系(instance-relation)出现次数的表示模型;(b)神经网络预测实例类型的基础上,学会了实体表示。下面,我们将描述这两个组件。
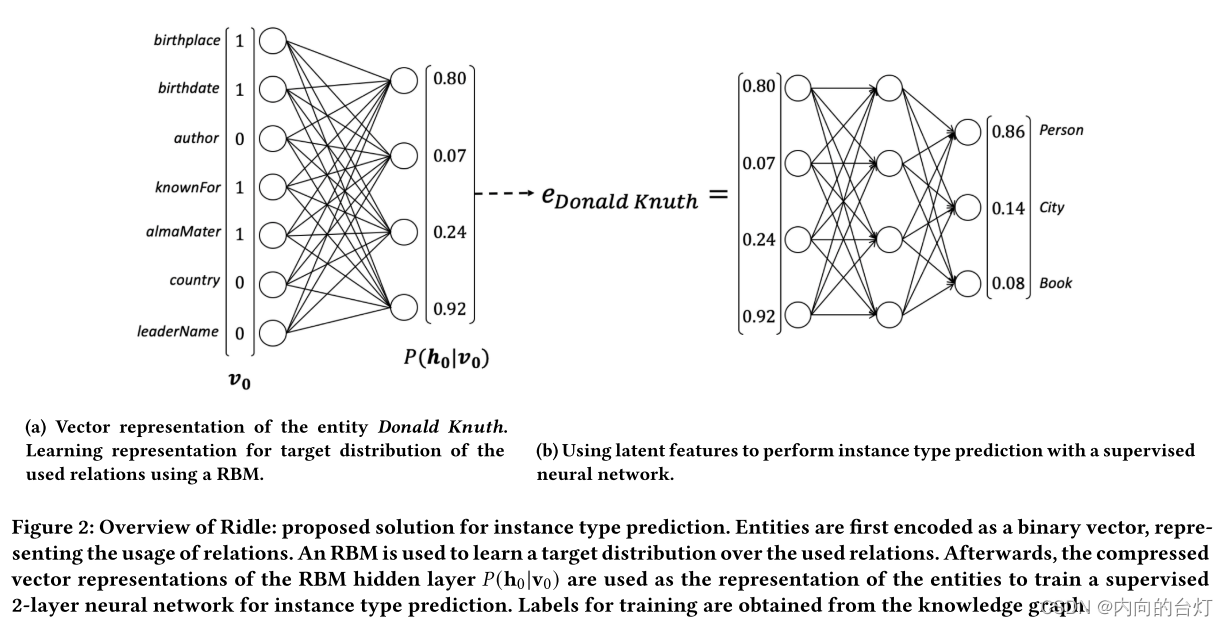
(a)实体Donald Knuth的向量表示。使用RBM学习表示所用关系的目标分布。
(b)使用潜在特征通过监督神经网络执行实例类型预测。
图2:Ridle概述:例如类型预测的建议解决方案。实体首先被编码为一个二进制向量,表示关系的用法。使用RBM来学习所使用的关系上的目标分布。然后,RBM隐藏层的压缩向量表示𝑃(h0|v0)被用作实体的表示以训练受监督的2层神经网络,例如类型预测。从知识图中获得用于训练的标签。
3.1 学习实例-关系表示(Learning Instance-Relation Representation)
Ridle的第一个组件的目标是学习给定知识图(KG)的表示。我们将KG定义为
G
=
(
E
,
R
,
L
,
T
)
G =(E,R,L,T)
G=(E,R,L,T),其中成对不相交集合
E
,
R
,
L
和
T
E,R,L和T
E,R,L和T分别对应于实体、关系、文字和类型或类的集合。G中的一个语句被建模为一个三元组
(
s
,
p
,
o
)
(s,p,o)
(s,p,o),其中
s
∈
E
∪
R
∪
T
,
p
∈
R
,
o
∈
E
∪
R
∪
L
∪
T
s∈ E ∪ R ∪ T,p∈ R,o∈ E ∪ R ∪ L ∪ T
s∈E∪R∪T,p∈R,o∈E∪R∪L∪T。我们将RDF [34]和RDFS [9]规范中定义的断言
r
d
f
:
t
y
p
e
rdf: type
rdf:type表示为关系
𝑡
𝑦
𝑝
𝑒
∈
R
𝑡𝑦𝑝𝑒∈ R
type∈R。此外,我们用R
−
⊂
R
^- ⊂ R
−⊂R表示特定领域关系的集合,其
𝑡
𝑦
𝑝
𝑒
𝑡𝑦𝑝𝑒
type从元模型或通用本体排除并进一步断言。
为了学习一个有效的实例关系表示,我们的方法根据知识图谱G的每个实体的属性对其进行编码。Ridle专注于特定领域的属性
R
−
R^−
R−,它允许发现具有相似语义描述的实体。通用谓词被从实体表示中排除,因为它们可能由于以下两个原因而阻碍学习过程:
(i)这些断言本身不提供允许将实体与不同类区分开的信息(注意三元组的对象在我们的表示中没有考虑。因此,例如断言type出现在实体中的编码对于预测实体所属的类是没有信息的。)
(ii)这些断言通常出现在大多数实体中。因此,Ridle将实体s∈ E建模为二元$|R^−|-vector v $,其中:|-vector v, where:
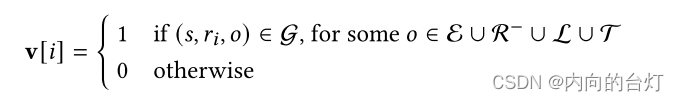
注意,我们选择二进制表示,因为使用关系的频率与实例类型的下游分类无关。图2a展示了编码为向量v的实例Donald Knuth的这种表示的示例。
然后,二进制向量v用作受限玻尔兹曼机(RBM)的输入,对于该受限玻尔兹曼机学习知识图谱G中的关系分布。RBM是模拟二进制数据的输入分布的生成模型,由一个可见层v和一个大小为的隐藏层h组成。在RBM中,没有明确的输出层,因为无监督模型尝试去近似输入数据的分布。该分布用于计算隐藏层中的潜在特征,其可以被看作输入数据的压缩表示。
在RBM中,层之间的权重或参数表示各个输入节点对隐藏层中的潜在特征的影响。在我们的方法中,参数的学习是通过Gibbs-sampling来完成的。因此,在以下符号中,索引(indexing)用于指示Gibbs-sampling过程的步骤。输入
v
0
v_0
v0乘以权重矩阵
W
W
W并加上偏置
a
a
a。类似于前馈神经网络,sigmoid激活函数𝜎用于计算隐藏值,表示为
𝑃
(
h
0
∣
v
0
)
𝑃(h_0|v_0)
P(h0∣v0)。
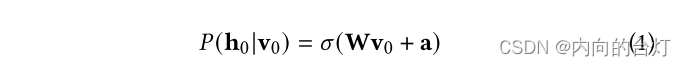
之后,基于样本的计算隐层
𝑃
(
h
0
∣
v
0
)
𝑃(h_0|v_0)
P(h0∣v0)是来自Bernoulli分布计算
h
0
h_0
h0隐藏状态。
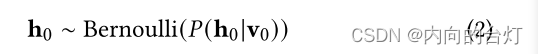
引入随机分布函数将神经元扩展为随机神经元。而高
𝑃
(
h
0
∣
v
0
)
𝑃(h_0|v_0)
P(h0∣v0)导致具有正隐藏状态
h
0
h_0
h0的高概率,低概率导致零输出。基于隐藏状态
h
0
h_0
h0,输入数据
v
0
v_0
v0将通过使用隐藏状态
h
0
h_0
h0作为输入并在神经网络中向后(backwarded)重构。由此,将隐藏状态
h
0
h_0
h0乘以与其被计算时相同但被转置的权重矩阵W,并加上偏置值b。然后,sigmoid激活函数被应用于该加权和。生成的向量表示为
𝑃
(
v
1
∣
h
0
)
𝑃(v_1|h_0)
P(v1∣h0)可以被看作是原始输入的近似。
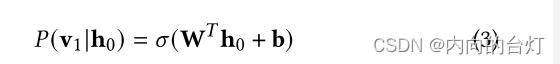
RBM是基于能量的概率模型,使用通过能量函数的概率分布来测量质量,类似于机器学习模型的cost函数。隐藏层用作潜在变量以增加模型的表达性,因此以下基于能量的概率函数(Gibbs分布)指定可以观察到某一状态v :
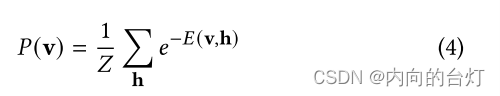
其中𝑍是所有可能状态的总和,称为归一化因子:

使用等式4,我们可以得出结论,低能量(low energy)
E
(
v
,
h
)
E(v, h)
E(v,h)导致高概率
p
(
v
)
p(v)
p(v),而高能量导致低概率
p
(
v
)
p(v)
p(v)。因此,为了增加概率
p
(
v
)
p(v)
p(v),我们必须使能量函数
E
(
v
,
h
)
E(v, h)
E(v,h)最小化。具有其输入v和隐藏状态h的RBM的能量函数(energy function)
E
(
v
,
h
)
E(v, h)
E(v,h)如下:
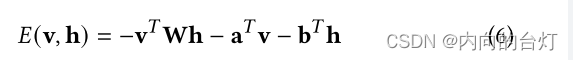
目的是近似分布,因此近似输入数据
v
0
v_0
v0和重构的输入数据
P
(
v
1
∣
h
0
)
P(v_1|h_0)
P(v1∣h0)的分布的差异应该最小化。因此,公式6中的两个分布中的能量函数要对齐。在以前的工作中已经表明,作为对数似然梯度(log-likelihood gradient)的近似,具有Gibbs-sampling的对比散度是学习RBM参数以计算目标分布的非常有效的方法。Gibbs链应用于单个样本的频率由参数k表示。在相关研究以及初步进行的实验中,已经表明𝑘= 1已经在目标分布的近似中获得了足够的结果。因此,与相关工作类似,我们使用k步对比散度来学习RBM的参数。一个样本
v
0
v_0
v0的对数似然梯度近似为以下公式:

使用更新规则,参数收敛,使得重建
v
1
v_1
v1的分布对应于输入
v
0
v_0
v0的分布。
3.2 Predicting Instance Types(预测实例类型)
我们将实例类型预测问题建模为多标签分类问题,因为实体可以属于G中的多个类。为了执行预测,Ridle利用了通过RBM学习到的实体的潜在特征,这些特征被馈送(fed into)到监督学习算法中。对于RBM中被建模为 v 0 v_0 v0的每个实体 s ∈ E s∈ E s∈E,Ridle获得学习表示 e 𝑠 = 𝑃 ( v 0 ∣ h 0 ) e_𝑠=𝑃(v_0|h_0) es=P(v0∣h0)(见图2b所示)。即:Ridle中的实例被表示为激活隐藏状态的学习概率。在Bernoulli采样之后获得的二进制向量 h 0 h_0 h0上选择该表示,作为 𝑃 ( v 0 ∣ h 0 ) ∈ [ 0 , 1 ] h 𝑃(v_0|h_0)∈ [0,1]^h P(v0∣h0)∈[0,1]h对应于编码KG中的类的潜在特征的成员关系的似然性,因此比二进制值携带更多的信息。然后,Ridle用实体s所属的类构造一个向量,即 t 𝑠 [ 𝑖 ] = 1 t_𝑠[𝑖] = 1 ts[i]=1 if ( 𝑠 , t y p e , 𝑡 𝑖 ) ∈ G (𝑠, type, 𝑡_𝑖) ∈ G (s,type,ti)∈G,for some 𝑡 𝑖 ∈ T 𝑡_𝑖∈ T ti∈T,否则 t 𝑠 [ 𝑖 ] = 0 t𝑠[𝑖] = 0 ts[i]=0。向量 t 𝑠 t_𝑠 ts被用作分类问题中的标签。
对于监督学习算法,Ridle实现了一个2层神经网络,输入图层大小
h
h
h和输出图层大小
∣
T
∣
|T|
∣T∣。在隐藏层中,Ridle使用GELU激活函数的近似值。我们选择GELU激活函数是因为它在相关机器学习任务中表现出色,如BERT中所展示的那样。对于网络中的输入𝑥,所使用的GELU函数近似值(如相应论文[10]中更详细描述)定义如下:
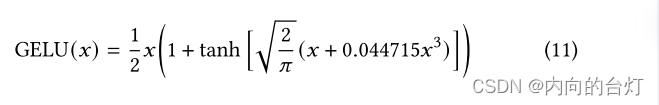
在输出层,Ridle应用了sigmoid函数,因此结果可以解释为实例属于某个类(class)或类型(type)的概率。
4 实验
4.1 实验设置
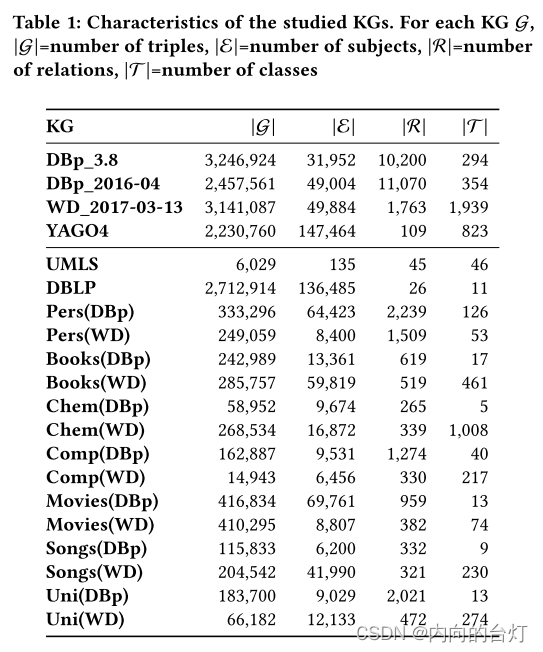
数据集。 根据相关工作[17,24],我们使用了知名的公共KG,如English DBpedia (3.8 and 2016-04) , Wikidata (WD_2017-03-13), YAGO4, UMLS and DBLP。在DBpedia图中,我们删除了常见关系,包括prov: wasDerivedFrom、dbo: wikiPageRevisionID和dbo: wikiPageID。所有这些关系都出现在大多数情况下,因此不提供类特定(class-specific)的信息。此外,我们还删除了模式断言(即rdf: type),以避免影响下游预测任务。除Wikidata外,所有KG都使用属性rdf: type来指定实例类型断言。Wikidata使用wd: P31作为类成员属性。考虑到KG的大小和有限的计算资源,我们对DBpedia、Wikidata和YAGO 4执行了数据预处理步骤,其中只考虑至少出现在10个三元组中且最多出现在1,000个三元组中的实体子集。此外,我们从DBp_2016-04(DBp)和WD_2017-03-13(WD)中提取了基于类别的子图,以研究仅限于特定主题的KG中方法的性能:persons (Pers), books (Books), chemical compounds (Chem), companies (Comp), movies (Mov), songs(Songs), and universities (Uni)。表1总结了数据集。
指标。 我们使用F1-score来度量实例类型预测的有效性,如在之前的相关工作[24,28]中所做的。为了更详细地显示预测误差的影响,我们针对多标签性能的聚合报告了F1-macro和F1-micro。我们通过使用10倍交叉验证进行每个实验,并报告平均F1评分。结果可以使用scikit-learn [25]中实现的k折交叉验证器(随机种子为42)重现。
基线。 我们将我们的方法Ridle与当前最先进的实例类型预测模型进行了比较。模型包括强基线(strong baselines),例如:RDF2Vec [28]。模型的选择基于其对RDF数据中实例类型预测的关注,例如SDType [24],优异的性能,例如,TransE [5]和RESCAL [23],以及链路预测的最新发展,例如InteractE [32]。使用最先进的方法来学习表1中描述的每个数据集的KG表示。然后,为了进行直接比较,将每个学习的表示馈送到3.2节中详细描述的相同神经网络架构。唯一的例外是SDType,因为它不学习KG表示,而是直接生成实例类型预测。
执行。 Ridle在Python3中实现。我们在每个知识图谱上使用相同的超参数设置,我们选择学习率𝛼 = 0.01,隐层大小为50,迭代100次来学习表示。
The experiments were performed on a server with Intel® Xeon® Gold 6142 CPU@2.60GHz, 32 physical cores and 188GB RAM.
对于基线,我们使用了作者推荐的标准超参数。
4.2 F1-Score性能
F1-macro和F1-micro方法的有效性如表2所示。总的来说,我们可以观察到,在所有研究的知识图中,没有一种方法完全优于其他方法。
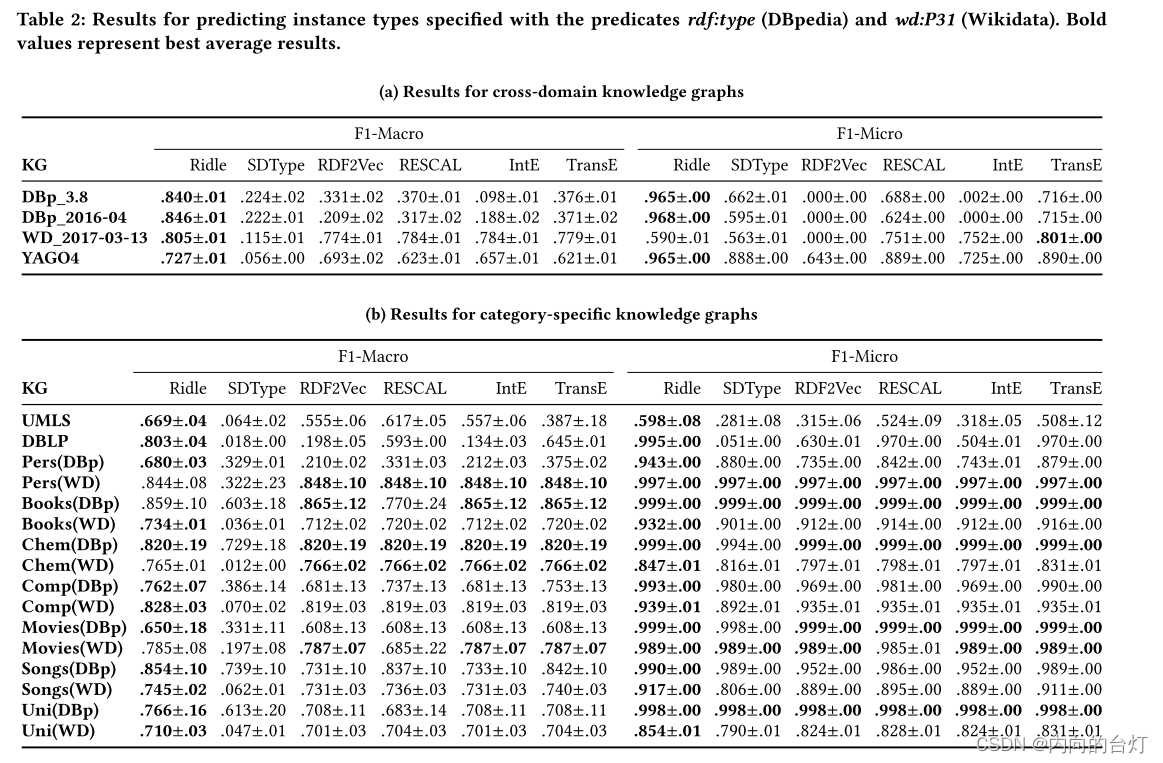
考虑跨域KG(参见表2a)中,Ridle在F1-macro指标方面显著优于最先进的方法。这表明,即使存在具有大量类和关系的大型KG,如DBpedia、Wikidata和YAGO的情况,我们提出的解决方案仍然能够产生准确的预测。其主要原因是KG表示是通过RBM模型学习的(参见第3.1节)能够捕获关系在KG中的实体上的分布。这又使得能够基于用于描述实体的关系来标识属于相同类的实体。相比之下,研究的基线大多是定制学习语句级表示,当考虑具有大量类和关系的大型知识库时,不能有效地编码关于实例类型的知识。关于度量F1-micro,我们可以观察到Ridle明显优于除Wikidata KG之外的其他方法。在这种情况下,Ridle不能正确地预测最流行类的实体,即具有大量实体的类,如human settlement(wd:Q486972)。此行为的原因是实体(e.g. wd:Q13071219)在最流行的Wikidata类中包含一些特定于类的关系,因此,影响Ridle的性能。相比之下,基线方法在学习KG表征时使用额外的对象信息,这允许区分来自不同类别的对象。这些结果证实了Ridle在KG中的实体用足够的类特定关系描述的场景中实现了高性能。在其余的KG中,Ridle可以正确地对大类和小类的实体进行分类,如两个度量所示。另一个重要的结果是RDF2Vec在DBpedia和Wikidata中实现了较低的F1-micro值。特别是,RDF2Vec总是将foaf:Agent预测为类,根据测试数据,这被认为是误报。
接下来,我们将考察这些方法在特定类别的KG中的性能(参见表2b)。我们可以观察到,在一些知识网格中,所有方法的性能都明显高于跨域知识网格。这表明在给定KG的某些类中实体的正确分类更容易。在平均F1-macro方面,Ridle在16个研究KG中的12个中优于最新技术水平。然而,在其他4个KG——Pers(WD)、Books(DBp)、Chem(WD)和Movies(WD)——我们可以得出结论,当考虑到平均F1-macro(数量级为 1 0 − 2 10^{-2} 10−2)和标准差(数量级为 1 0 − 1 10^{-1} 10−1)之间的差异时,与最好的方法相比,Ridle实现了具有竞争力的性能。在F1-micro方面,Ridle平均达到了非常高的性能。此外,其他方法也能获得较高的性能,如数据集Pers(WD), Books(DBp), Chem(DBp), Movies(DBp), Movies(WD), and Uni(DBp)。这些KG的主要特征是具有低到中等数量的类( ∣ T ∣ |T| ∣T∣处于5到53),以及数百个关系( ∣ R ∣ |R| ∣R∣处于265到959),除了Rers(WD)之外,因为它有 ∣ R ∣ = 1509 |R|= 1509 ∣R∣=1509。然而,即使在具有数百个类或很少关系的特定类别的KG中,我们的方法也优于现有技术。
4.3 Visualizing Entities from the Learned KG Representations.(从学习的KG中可视化实体)
为了深入了解我们的解决方案在实例类型预测中的有效性,我们计算了DBpedia、Wikidata和YAGO KG的学习实体表示到二维空间中的PCA投影。除了Ridle之外,我们还展示了RDF2Vec的结果,作为一个示例性方法,它在特定类别的KG中表现出良好的性能。在下文中,我们分析了图3所示KG中选定类别的结果。
对于DBpedia KG,我们关注前四个最流行的类。我们可以观察到,虽然Agent类在两种表示中都很宽泛,但Ridle允许更好地将Work和Place类与Agent区分开来。这种将向量与不同类分离的做法对于在预测实例类型的下游任务中实现高性能是必不可少的。相反,RDF2Vec的表示表明类Work和Place(在语义上)与Agent相关,这在DBpedia中不成立。此外,类Species在RDF2Vec中不可见,因为它被Agent表示所覆盖。
接下来,我们分析来自Pers(DBp)KG的前四个类别的学习表示。在这两种方法中,我们观察到类OfficeHolder和Politician的实例紧密地交织在一起,并且很难彼此区分。仔细查看OfficeHolder和Politician实例可以发现,这些实例经常使用相同的关系,并且这些类没有各种特定的关系。对于类别Athlete和Artist,与RDF2Vec相比,Ridle实现了计算向量的更大分离。其原因是RDF2Vec考虑三元组中的对象值,因此,在此表示下,类别Athlete和Politician被视为相似,因为它们的实例在某些情况下共享相同的对象。但是,这种行为会对RDF2Vec的实例类型预测功能产生负面影响。为了分析Wikidata和YAGO的结果,我们选择了一些相似和不相似的类来显示Ridle在不同场景中的行为。在维基数据中,Ridle清楚地区分了不同的类别——即蛋白质和河流——并且紧密地表示具有语义接近性的那些——即河流和湖泊,它们经常使用类似的关系,例如位于行政区域实体(P131)和支流(P974)【e.g. located in the administrative territorial entity (P131) and tributary (P974).】。类似于先前的结果,Ridle的YAGO实例表示允许区分不同的类,尽管使用类似关系的实体,例如Painting和Movie类的实体,由于频繁使用相同的关系而彼此更接近。相比之下,RDF2Vec无法有效区分这些数据集中的实体类型。
使用从PCA预测中获得的洞察力,我们可以进一步理解表2中给出的预测实例类型的结果。在DBp_2016-04、YAGO 4等跨域类组中,存在大量的类,类的实例大多由类特有的关系来描述。通过计算这些关系的使用上的目标分布,Ridle的表示可以比基线方法平均更准确地对实体进行分类。包括语句的对象信息,如基线方法所做的那样,导致实例更接近,导致更难以将实例分类到它们的正确类中。例如,在DBp_201604中具有Agent和Place类的RDF2Vec中观察到了这一点。通过使用非常少的类特定关系来描述实例,Ridle不再能够区分类,导致关于F1-score的性能损失。总的来说,我们可以得出结论,当实体用类特定的关系描述时,Ridle能够获得一个有效地编码语义相似和不相似类的表示。
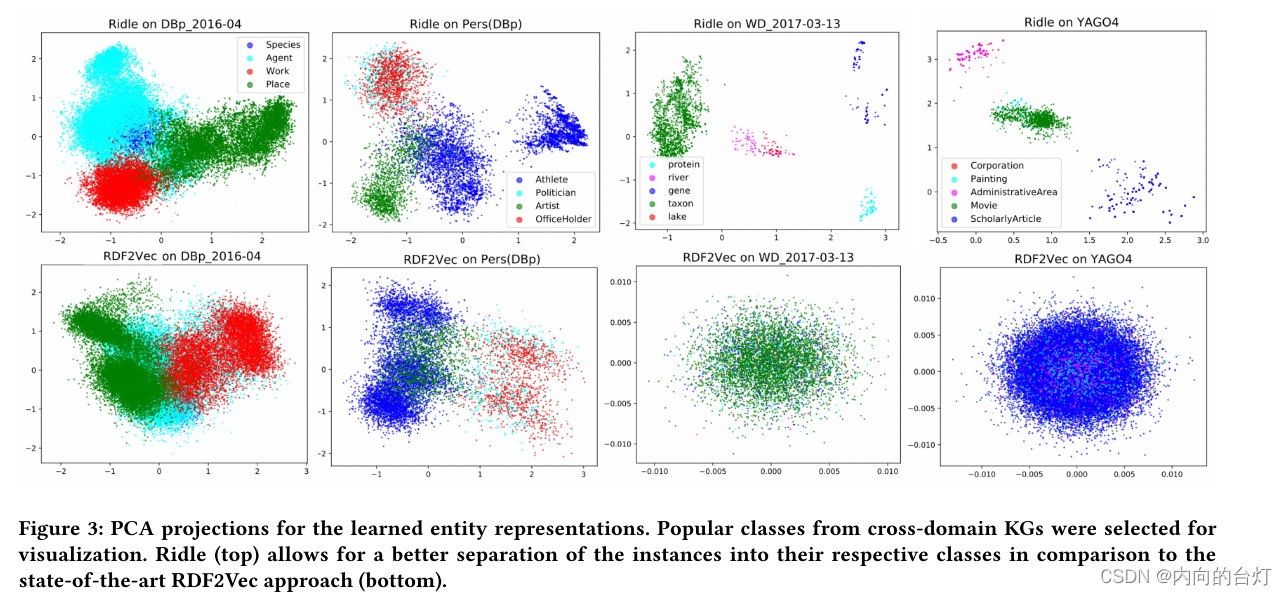
图3:学习实体表示的PCA投影。从跨领域KG中选择受欢迎的类进行可视化。与最先进的RDF2Vec方法(底部)相比,Ridle(顶部)允许更好地将实例分离到它们各自的类中。
5 结论和未来工作
在本文中,我们提出了一个归纳随机分解模型来表示实体的知识图谱(KGs)表示,适用于预测实例类型的断言。我们的方法,Ridle,首先实现了一个基于受限玻尔兹曼机(RBM)的无监督学习模型,以利用KG实例中关系使用的分布。然后,我们根据RBM学习到的潜在特征设计实体表示。Ridle使用学习到的表示实现了一个预测实例类型断言的神经网络结构。
实验结果表明,平均而言,Ridle在多个KG中的性能优于当前最先进的模型,这为预测实例类型断言的任务设置了一个新的基线。学习的KG表示的可视化表明Ridle能够正确地将具有相似关系分布的实体分组,而不相似的实体被表示得很远。Ridle的这一特性是实现实体预测高性能的关键。同样,即使在训练过程中无法获得本体信息,Ridle也能够从实例-关系(instance-relation)分布中重构关系之间的语义关联。Ridle实例表示中学习到的语义关联是实例类型预测任务下游性能的决定性因素。
未来的工作可能会集中在研究学习的实例表示对构造类分类法的有效性。如本文所示,使用相似目标分布的实例在维度空间中是封闭的,这可以被挖掘以预测类之间的包含关系。未来的工作还可能研究其他类型图式知识的完成,例如,属性的域和范围。















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









