







摘要
特征提取是缓解高维数据中维数问题的一种有效方法。对比学习作为一种流行的自监督学习方法,近年来引起了广泛的关注。在本研究中,我们提出了一个基于对比学习的自适应正负样本(CL-FEFA)的统一特征提取框架,该框架适用于无监督、有监督和半监督的特征提取。CL-FEFA从特征提取的结果中构建了自适应的正样本和负样本,使其更加合适和准确。同时,基于自适应正负样本提取鉴别特征,使类内嵌入样本更加紧凑,类间嵌入样本更加分散。在此过程中,利用子空间样本的潜在结构信息动态构建正负样本,使我们的框架对噪声数据具有更强的鲁棒性。此外,还证明了CL-FEFA实际上最大化了正样本的互信息,从而捕获了非线性统计数据。
1. 介绍
目前,高维数据被广泛应用于模式识别和数据挖掘中,这导致了高存储开销、繁重的计算和过度的时间消耗,此外还导致了被称为“curse of dimensionality”(维数灾难)的问题。解决这些问题的一个重要方法是特征提取,它通过投影矩阵将原始的高维空间数据转换为低维子空间。尽管特征提取的效果通常比深度学习的效果差一点,但由于其强大的可解释性,特别是在任何类型的硬件(CPU、GPU、DSP)上,它一直是研究热点。因此,在传统的特征提取中,迫切需要更好地提取下游任务的区分特征。
在深度学习领域,对比学习作为自监督学习的主要方法,受到了广泛的学术关注。通过构建正样本和负样本,对比学习利用数据的信息来监督自己,从而获得更多的辨别特征。在对比预测编码(CPC)中提出了基于对比学习的InfoNCE损失。因此,大量基于对比学习的研究被提出。Tian等人提出了对比多视图编码(CMC)来处理多视图数据。首先,CMC将同一样本的两个视图数据视为正样本,将不同样本的两视图数据视作为负样本,然后通过最小化InfoNCE损失来优化神经网络,以最大化投影的正样本的相似性。随后,Chen等人提出了一个简单的对比学习框架(SimCLR)来处理单视图数据。首先,进行数据增强,获得不同的样本表示,然后将相同样本的表示视为正样本,将不同样本的表示视为负样本。最后,SimCLR通过最小化InfoNCE损失来优化网络,类似于CMC。许多方法通过定义不同的正样本和负样本来提高性能,如动量对比(MoCo)、不变性传播(InvP)和混合对比硬负性(MoCHi)。具体地说,MoCo增加了InfoNCE损失中的负样本数量,而InvP和MoCHi采用了不同的硬采样策略。此外,监督对比学习(SupCon)已经证明了对比学习在监督学习中也有很大的优势。经过数据增强后,SupCon将同一类别的样本定义为正样本,将不同类别的样本定义为负样本,然后将InfoNCE损失最小化。
虽然这些基于对比学习的方法在无监督学习和有监督学习中都有良好的表现,但它们也有一些缺点。首先,现有的基于对比学习的算法是在深度学习领域产生的,并不适用于传统的单视图特征提取问题。其次,即使我们根据现有的定义正负样本的方法构建InfoNCE损失,并使用其进行特征提取,仍然存在一些问题,如数据增强会增加算法的运行时间;此外,正负样本的定义忽略了无监督和监督学习中数据的潜在结构信息,导致同类嵌入样本的分散和不同类的嵌入样本的聚集;此外,正负样本的定义和特征提取的过程是相互独立的,这可能使预先确定的正负样本不适合特征提取的任务,从而阻碍了特征提取。
受我们之前研究的启发,我们提出了一个基于自适应对比学习的正负样本(CL-FEFA)的统一特征提取框架,该框架适用于无监督、有监督和半监督的单视图特征提取。并与以往基于对比学习的模型进行了比较,所提出的框架CL-FEFA不需要数据增强,它是基于特征提取的结果,从潜在的结构信息中自适应地构建正负样本,同时根据正负样本的InfoNCE损失提取鉴别特征。实际上,CL-FEFA没有采用预先确定的正负样本方案,而是将潜在结构的探索纳入特征提取过程中,选择最优的正负样本,同时得到最优的投影矩阵。通过利用这两个基本任务之间的交互作用,CL-FEFA能够构建更合适的正样本和负样本,并提取更多可判别的特征。同时,潜在的结构信息使我们的框架对有噪声的数据更具鲁棒性。此外,引入indicating matrix(指示矩阵)来统一无监督、监督和半监督特征提取。
本研究的主要贡献如下:
- 从一个新的角度提出了一种基于自适应正负样本(CL-FEFA)的统一特征提取框架,适用于无监督、监督和半监督的情况。
- CL-FEFA将对潜在结构的探索融入到特征提取的过程中,在对比学习中自适应地构建更合适的正、负样本。此外,这也使该框架更加健壮。
- 证明了CL-FEFA实际上最大限度地提高了正样本的互信息,从而捕获了潜在结构空间中相似样本之间的非线性统计依赖性,从而可以作为真实依赖性的度量。
- 在四个真实数据集上的实验表明了所提框架的优势。
本文的其余部分组织如下。在第2节中简要介绍了传统的特征提取方法。随后,在第3节中讨论了特征提取框架(CL-FEFA)的开发。此外,在第4节中还介绍了在多个真实世界的数据集上进行的广泛实验。最后,本研究的结论详细介绍在了第5节中。
2. 相关工作
近年来,在无监督、有监督和半监督的特征提取过程中,应该保留了几个重要的结构。具体而言,基于各种图分别设计了无监督学习、局部保留投影(LPP)、(NPE)邻域保留嵌入、稀疏保留投影(SPP)、基于协作表示的投影(CRP)和低秩保留嵌入(LRPE)。此外,监督特征提取方法除了保留manifold structure(流形结构)外,还利用样本标签获得了更多的判别信息。例如,局部Fisher判别分析(LFDA)结合线性判别分析(LDA)和LPP局部构造类内scatter(散射)和类间scatter(散射),以实现最大限度地同时保护类内和类之间的局部结构。Marginal(边际) Fisher分析(MFA)考虑了类内的局部结构,并通过考虑不同类边缘的样本来构建类之间的局部结构关系。作为改进,多重边际Fisher分析(MMFA)选择所有异质边上的最近邻样本来构建类之间的局部关系。提出了基于SPP的稀疏保持判别投影(SPDP)来保持子空间中类内样本的稀疏重构系数。此外,对于半监督特征提取,Zhang等人提出了半监督LPP(SLPP),它同时保留了已标记数据和未标记数据的流形结构。Huang等人提出了一种半监督边际费雪分析(SSMFA),该方法也保留了标记和未标记数据的流形结构,并对不同样本对的边缘分配判别权值。Liao等人提出了一种称为半监督局部判别分析(SELD)的非参数框架。SELD旨在利用未标记数据的本地邻居信息,同时保留标记数据的鉴别信息。
然而,当不去除冗余和噪声特征时,上述方法设计的固有结构是不可靠和不准确的。为了解决这一问题,提出了一些自适应的结构保持方法,即在特征提取后学习结构信息。具体地说,在无监督、监督和半监督的情况下,分别使用具有聚类结构的学习图(LGCS)、局部自适应判别分析(LADA)和半监督自适应局部嵌入学习(SALE)进行无监督特征提取。此外,这一想法已应用于许多其他领域的模式识别,如最优图嵌入半监督特征选择用于视频语义识别,多特征融合方法用于行人再识别,半监督循环卷积注意模型使用人类活动识别,边缘结构化表示学习和自适应图扩散鉴别回归用于基于线性回归的多类分类。
受传统方法的启发,我们提出了一个基于自适应正负样本对比学习的特征提取框架(CL-FEFA)。具体地说,与以往基于对比学习的模型相比,CL-FEFA不需要数据增强,它根据特征提取的结果构建自适应的正负样本,使其更加合适和准确。同时,根据基于自适应正、负样本的InfoNCE损失来提取鉴别特征,使类内嵌入样本更加紧凑,类间嵌入样本更加分散。在此过程中,利用子空间样本的潜在结构信息动态构建自适应的正负样本,使我们的框架对噪声数据具有更强的鲁棒性。与传统模型相比,CL-FEFA适用于无监督、有监督和半监督的特征提取。此外,它还考虑了正样本之间的互信息,它捕获了潜在结构中相似样本之间的non-linear statistical dependencies(非线性统计相关性),从而可以作为真实相关性的度量。这也为其在特征提取方面的优势提供了理论支持。
3. 方法
在本节中,提出了一种基于自适应正负样本对比学习的统一特征提取框架(CL-UFEF),用于无监督、有监督和半监督的特征提取。
让我们用数学方法表示无监督、有监督和半监督的特征提取问题如下。
特征提取问题:给定一个训练样本集X = [
x
1
{x}_{1}
x1,
x
2
{x}_{2}
x2,…,
x
n
{x}_{n}
xn]∈
R
D
×
n
{R}^{D×n}
RD×n,其中n和D分别是样本和特征的数量。在有监督的情况下,提供了所有样本的标签,
x
i
{x}_{i}
xi的标签被定义为
c
i
{c}_{i}
ci,i = 1,2,…,n。在半监督的情况下,提供了少量样本的标签,并将标记的样本
x
i
{x}_{i}
xi的标签也定义为
c
i
{c}_{i}
ci。特征提取的目的是找到一个投影矩阵P∈
R
D
×
d
{R}^{D×d}
RD×d推导出低维嵌入Y = [
y
1
{y}_{1}
y1,
y
2
{y}_{2}
y2,…,
y
n
{y}_{n}
yn]∈
R
D
×
d
{R}^{D×d}
RD×d,利用公式Y =
P
T
{P}^{T}
PTX,其中d≪D。
为方便起见,本研究中使用的符号汇总见表1。

| 符号 | 定义 |
|---|---|
| X | 训练样本集 |
| Y | 在低维空间中的训练样本集 |
| n | 训练样本数量 |
| D | 原始空间中样本的维数 |
| d | 嵌入空间中样本的维数 |
| H | 指示矩阵 |
| S | 相似矩阵 |
| ci | 样本Xi标签 |
| P | 投影矩阵 |
| σ | 正参数 |
| λ | 正参数 |
| c | 正整形参数 |
| k | 邻居数量 |
| NK(xj) | xj的k个最近邻居 |
| ∇L(P) | L (P)相对于P的梯度 |
| T | 迭代次数 |
3.1. 基于自适应正负样本对比学习的特征提取框架(CL-UFEF)
正样本和负样本的定义
为了统一无监督、有监督和半监督特征提取的情况,我们首先定义了一个指示矩阵
[
H
i
,
j
]
n
×
n
[{H_{i,j}]}_{n×n}
[Hi,j]n×n,其元素为:

然后,
S
i
,
j
S_{i,j}
Si,j表示基于特征提取结果的样本
x
i
x_i
xi和
x
j
x_j
xj在潜在结构空间中的相似性关系。我们通过连接指示矩阵
[
H
i
,
j
]
n
×
n
[{H_{i,j}]}_{n×n}
[Hi,j]n×n和相似矩阵
[
S
i
,
j
]
n
×
n
[{S_{i,j}]}_{n×n}
[Si,j]n×n来构造相应的正负样本。具体地说:
① 如果
H
i
,
j
H_{i,j}
Hi,j
S
i
,
j
S_{i,j}
Si,j≠0,
x
i
x_i
xi和
x
j
x_j
xj定义为一对正样本,
② 如果
H
i
,
j
H_{i,j}
Hi,j
S
i
,
j
S_{i,j}
Si,j=0,
x
i
x_i
xi和
x
j
x_j
xj定义为一对负样本。
CL-FEFA模型
CL-FEFA没有预先确定正负样本,而是将潜在结构的探索纳入特征提取过程中,选择最优的正负样本,同时得到最优的投影矩阵。在CL-FEFA中,基于自适应正负样本的InfoNCE损失提取出更多有判别力的特征,
S
i
,
j
S_{i,j}
Si,j越大的正样本
x
i
x_i
xi和
x
j
x_j
xj的投影应该具有更大的相似性。具体来说,CL-FEFA的优化问题定义如下:
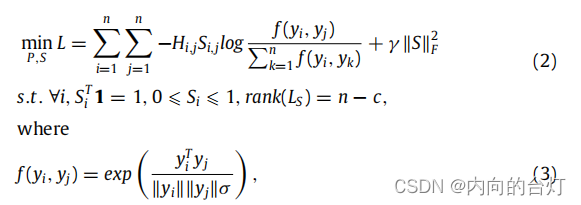
γ
γ
γ和
σ
σ
σ是两个正参数,
S
i
S_i
Si表示
S
S
S的第i个列向量,粗体的1是所有1构成的n维列向量。
L
S
L_S
LS=
D
S
D_S
DS−(
S
S
S+
S
T
S^T
ST)
/
2
/2
/2在图论中称为拉普拉斯矩阵,度矩阵
D
S
D_S
DS∈
R
n
×
n
R^{n×n}
Rn×n定义为一个对角矩阵,其中第i个对角元素为(
S
i
,
j
S_{i,j}
Si,j+
S
j
,
i
S_{j,i}
Sj,i)
/
2
/2
/2。
r
a
n
k
rank
rank(
L
S
L_S
LS)=
n
−
c
n−c
n−c,约束条件是
S
S
S的连通分量数正好为
c
c
c。特别地,在无监督和半监督的情况下,
c
c
c是一个正整数参数,而在有监督的情况下,
c
c
c是类的数量。
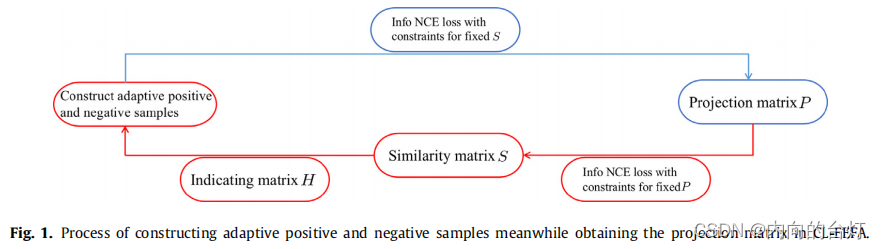
图1 构造自适应正负样本同时得到CL-FEFA中投影矩阵的过程。
构造自适应正负样本同时得到投影矩阵的过程如图1所示。红线表示构造自适应正、负样本的过程,蓝线表示学习投影矩阵的过程。通过利用红线和蓝线这两个基本任务之间的相互作用,CL-FEFA能够构造最优的正负样本,得到最优的投影矩阵P。
3.2. CL-FEFA与互信息的关系
为了方便起见,我们制作了
W
i
,
j
W_{i,j}
Wi,j =
H
i
,
j
H_{i,j}
Hi,j
S
i
,
j
S_{i,j}
Si,j,其中i, j = 1, 2, …, n。因此,如果
W
i
,
j
W_{i,j}
Wi,j ≠ 0,则
x
j
x_j
xj是
x
i
x_i
xi的正样本,否则
x
j
x_j
xj是
x
i
x_i
xi的负样本。自然地,
X
X
X中的样本
x
j
x_j
xj是
x
i
x_i
xi的正样本的概率等于
p
p
p(
W
i
,
j
W_{i,j}
Wi,j =
0
0
0
∣
|
∣
x
j
x_j
xj,
x
i
x_i
xi),并且优化问题(2)等价于:
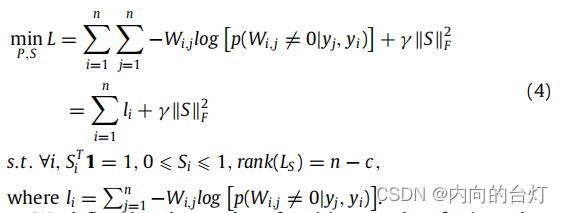
我们定义
x
i
x_i
xi的正样本数为
n
i
n_i
ni,那么
x
i
x_i
xi的负样本数为
n
n
n−
n
i
n_i
ni。因此,当i被固定时,有两个先验分布
p
p
p(
W
i
,
j
W_{i,j}
Wi,j ≠
0
0
0)
=
=
=
n
i
n_i
ni /
n
n
n和
p
p
p(
W
i
,
j
W_{i,j}
Wi,j ≠
0
0
0)
=
=
= (
n
n
n -
n
i
n_i
ni) /
n
n
n。根据贝叶斯公式,推导结果如下:

进一步推导,公式如下:
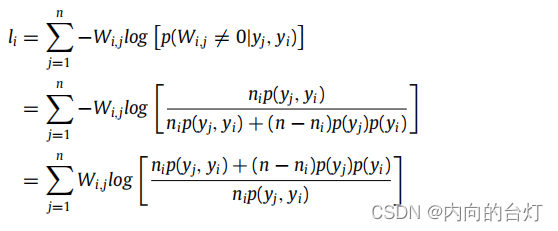
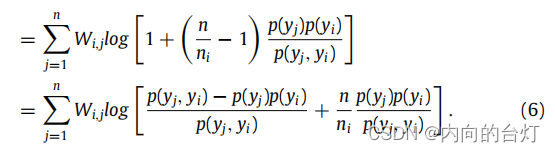
由于
x
i
x_i
xi和
x
j
x_j
xj是正样本,
y
i
y_i
yi和
y
j
y_j
yj不是独立的,那么
p
p
p(
y
j
y_j
yj,
y
i
y_i
yi) −
p
p
p(
y
j
y_j
yj)
p
p
p(
y
i
y_i
yi) > 0。通过优化问题(4)可以看出,在这两个潜在的任务中,
W
i
,
j
W_{i,j}
Wi,j越大,将导致
p
p
p(
y
j
y_j
yj,
y
i
y_i
yi)就越大,反之亦然。此外,在最优情况下,
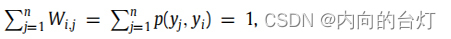
所以
W
i
,
j
W_{i,j}
Wi,j =
p
p
p(
y
j
y_j
yj,
y
i
y_i
yi)。因此,我们可以得到以下推导:
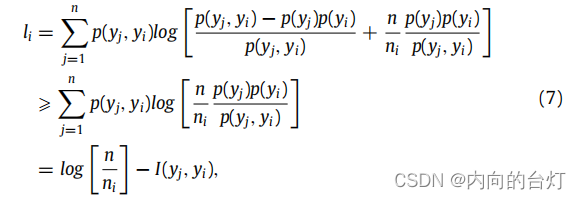
其中,
I
I
I(
y
j
y_j
yj,
y
i
y_i
yi)表示
y
j
y_j
yj和
y
i
y_i
yi之间的互信息。因此,我们可以得到
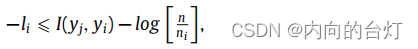
并且最小化等式(2)中的
L
L
L就相当于最大化所有正样本的互信息。因此,CL-FEFA实际上最大化了正样本的互信息,它捕获了潜在结构空间中相似样本之间的非线性统计相关性,从而可以作为真实相关性(dependence)的度量。
对应单词 non-linear statistical dependencies
3.3. 优化策略
此外,该优化问题(2)可以转换为:
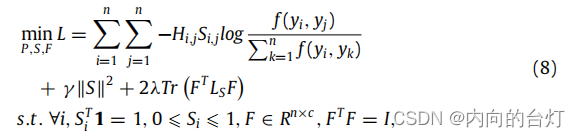
其中,
λ
λ
λ是一个正参数。
-
(1) 当 P P P和 S S S固定时,优化问题(8)变为:

问题(9)的最优解 F F F由 c c c个最小特征值对应的 L S L_S LS的 c c c个特征向量组成。
(特征值:eigenvalue; 特征向量:eigenvector) -
(2) 当 P P P和 F F F固定时,优化问题(8)变为:
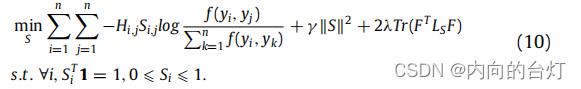
问题(10)可以被写成:
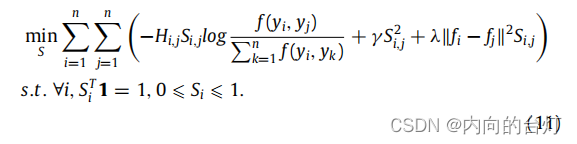
注意,问题(11)对于不同的 i i i是独立的,所以我们可以为每个 i i i单独解决以下问题:
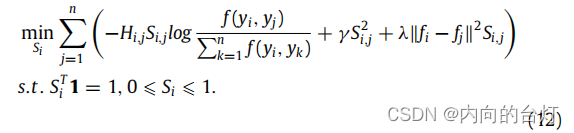
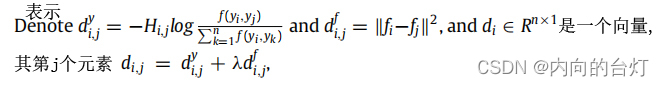
那么问题(12)可以用向量形式写成:

这个问题(13)可以通过参考文献Nie, Wang, and Huang (2014) 来解决。特别地,参数 γ γ γ被邻居的数量 k k k所取代。 -
(3) 当 S S S和 F F F固定时,优化问题(8)变成:
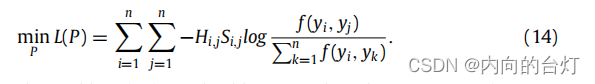
这个问题(14)是通过使用Adam优化器来解决的。Adam是随机梯度下降方法的一个进步,可以快速得到准确的结果。该方法根据梯度的第一和第二矩(the first and second moments of the gradient)的预算计算各种参数的自适应学习率。参数 α α α、 β 1 β_1 β1、 β 2 β_2 β2、 ϵ ϵ ϵ分别表示学习率、一阶和二阶矩估计(moment estimation)的指数衰减率(exponential decay rate),以及在实现过程中防止除以零的参数。此外,损失函数相对于投影矩阵 P P P的梯度由(15)得到。
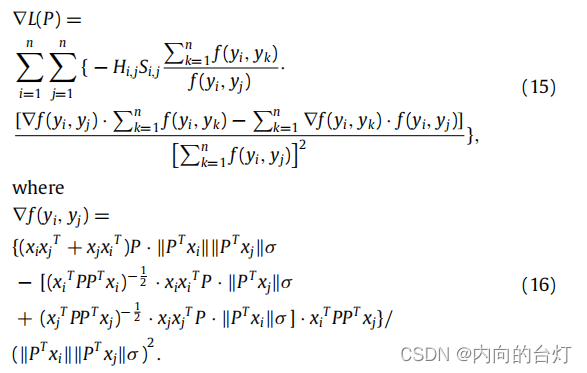
到目前为止,本文已经描述了三个变量的优化步骤。我们在以下算法中总结了我们的优化算法1。我们将实验中使用的收敛条件设为
∣ L |L ∣L( P t P_t Pt) − - − L L L( P t + 1 P_{t+1} Pt+1) ∣ | ∣ < = <= <= 1 0 − 3 10^{-3} 10−3 and ∣ L |L ∣L( P T P_T PT) − - − L L L( P T + 1 P_{T+1} PT+1) ∣ | ∣ < = <= <= 1 0 − 3 10^{-3} 10−3。

3.4. 成分分析
算法1中每个循环的主要计算复杂度是Adam优化器第一步中的损失函数的推导,其复杂度是O( n 2 n^2 n2( D 2 D^2 D2d+Dd+ D 2 D^2 D2))。假设算法1在每次迭代的Adam优化器中总共执行M次迭代和m个循环,则主要计算复杂度为O(Mm n 2 n^2 n2( D 2 D^2 D2d+Dd+ D 2 D^2 D2))。
4. 实验结果
为了验证CL-FEFA算法的有效性,我们使用了四个数据集进行实验。在无监督、有监督和半监督情况下的比较方法如下。
在无监督的情况下,将我们的无监督CL-FEFA(u-CL)与LPP、FLPP、LAPP和SimCLR进行比较,其中:LPP是一种典型的无监督方法,其目标是保持样本的局部邻域信息;FLPP是一种新的无监督方法,其目标是保持样本的局部邻域信息;LAPP是一种新的无监督方法,旨在保持局部邻域信息并且对样本噪声不敏感;SimCLR是一种基于对比学习的新型无监督深度学习方法,它将同一样本的表示定义为正样本,将不同样本的表示定义为负样本。注意,为了使用SimCLR进行特征提取,通过将数据中的每个画面逆时针旋转90度来执行数据增强,然后使用其损失函数来获得投影矩阵P。
在有监督的情况下,将我们的监督CL-FEFA(s-CL)与LDA、FDLPP、LADA和SupCon进行比较,其中:LDA是一种典型的有监督方法,其目标是在无局部保存(without local preservation)的情况下最小化类内离散度和最大化类间离散度;FDLPP是一种新的有监督的方法,其目标是在有局部保存(with local preservation)的情况下最小化类内离散度和最大化类间离散度;LADA是一种新的有监督的方法,其目标是在具有自适应的局部保存的情况下,最小化类内离散度和最大化类间离散度;SupCon是一种基于对比学习的新型有监督深度学习方法,它将同类样本的表示定义为正样本,将不同类样本的表示定义为负样本。此外,数据增强就像SimCLR一样执行。
在半监督的情况下,将我们的半监督CL-FEFA(semi-CL)与SLPP、SELD、SSMFA和SALWE进行比较,其中:SLPP是一种典型的半监督方法,其目标是preserving(保存、保留)标记样本和未标记样本的流形结构;SELD是一种典型的半监督方法,其目标是利用未标记样本的局部邻域信息,同时preserving已标记样本的判别(discriminant)信息;SSMFA是一种典型的半监督方法,其目标是preserving标记样本和未标记样本的流形结构,并对不同样本对的边assigning(赋予、指定)discriminative(区别性、有判别力的)权重;SALWE是一种新的半监督方法,其目标是自适应地保持标记样本和未标记样本的流形结构。
4.1. 数据集描述
- Yale数据集:该数据集由耶鲁大学计算机视觉与控制中心创建,包含15个个体的数据,其中每个人有11张在各种光照条件下拍摄的正面图像(尺寸为64 × 64像素)。图像编辑为50 × 40像素,灰度级为256;图2(a)中给出了实例。
- ORL数据集:ORL数据集包含40个不同人的400张图像。同一个人的每个图像是在不同的时间、光线、面部表情(睁开眼睛/闭上眼睛、微笑/不微笑)和面部细节(戴眼镜/不戴眼镜)下捕获的。所有图像尺寸为50 × 40像素,灰度级为256。示例见图2(b)。
- MNIST数据集:该数据集包含70000个0 - 9数字图像样本,大小为28 × 28。我们随机选取2000幅图像作为实验数据,将所有图像均匀地缩放到16 × 16的大小,并使用256级灰度像素值的特征向量来表示每幅图像。图2©给出了示例。
- CIFAR-10数据集:该数据集包含10个类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车)的32 × 32彩色图像的60000个样本。每个图像由3072维特征向量表示,其中前1024个特征表示红色通道值,接下来的1024个特征表示绿色通道值,并且最后的1024个特征表示蓝色通道值。示例如图2(d)所示。

图2. 实验中使用的图像样本:(a)耶鲁数据集,(b)ORL数据集,(c)MNIST数据集,(d)CIFRA-10数据集。
4.2. 实验设置
为了充分评估我们提出的CL-FEFA的有效性,下面我们将展示我们的方法在分类任务上表现良好。实验中使用k-nearest邻居分类器(k = 1)。此外,从Yale和ORL数据集的每个类中随机选取4个样本,从MNIST和CIFAR-10数据集的每个类中随机选取6个样本进行训练,剩余数据用于测试。在半监督的情况下,对于四个数据集,每个类的两个训练样本被标记。详情见表2。所有过程重复5次,最终的评价标准构成5次重复实验的平均Classification Accuracy(分类准确率)和平均Recall Rate(召回率)。分类准确率和召回率的计算方法如(17)和(18)所示。所有实验均在2.90 GHz的英特尔酷睿i5-9400 CPU, 16 GB RAM and Matlab R2018a (64 bit)的Windows 10台式计算机上实施。
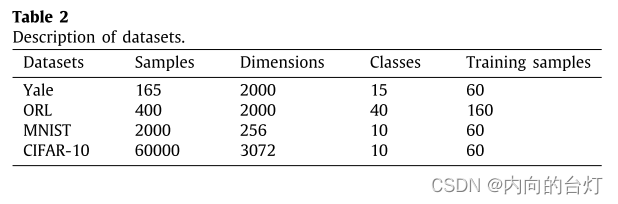
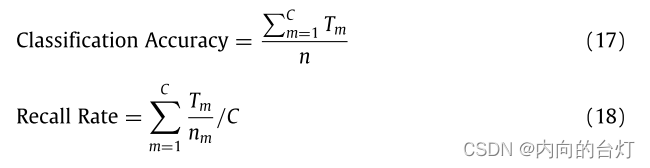
其中
T
m
T_m
Tm是第m类中的真实样本数,
n
m
n_m
nm是第m类预测样本数,C为总类数。
4.3. 参数设置
通过预先设置一定的参数来评价各种特征提取方法的性能。首先,在Adam优化器中测试机器学习问题更合适的默认参数包括 α = 0.001 , β 1 = 0.9 , β 2 = 0.999 , ϵ = 10 − 8 α = 0.001,β_1 = 0.9,β_2 = 0.999,ϵ= 10−8 α=0.001,β1=0.9,β2=0.999,ϵ=10−8。此后,对于所有比较算法,k的搜索范围被设置为{2,6,10},而对于u-CL、s-CL、semi-CL、SimCLR和SupCon, σ σ σ的范围被设置为{−2,−1,0,1,2,3} × 1e。此外,对于u-CL和semi-CL,参数 λ λ λ被设置为{−4,−2,0,2,4} × 1e。在s-CL中,对于所有的heterogeneous(非均匀)样本 x i x_i xi和 x j x_j xj,都存在 H i , j S i , j = 0 H_{i,j}S_{i,j} = 0 Hi,jSi,j=0,这使得连通分量恰好为C,因此我们取 λ = 0 λ = 0 λ=0。同时,为了缩短算法的运行时间,对于u-CL和semi-CL,让参数 c c c为每个数据集的类数。
4.4. 结果分析
通过比较上述方法的实验结果,证明了CL-FEFA的较好的性能。主要比较项目和motivations(动机)总结见表3。

在真实数据集上
首先,我们在表4、表5和表6中报告了在Yale、ORL、MNIST和CIFRA-10数据集上针对无监督、有监督和半监督情况的最佳特征提取下的最大分类准确度(包含标准)和最大召回率(包含标准)偏差,其中"Mean"表示一种方法在四个数据集上的最大分类准确度或最大召回率的平均值。每个数据集最合适的结果以粗体标记。此外,在每个数据集上不同降维条件下所有方法的分类准确率如图3、图4和图5所示。基于这些实验结果,进行了以下的观察。
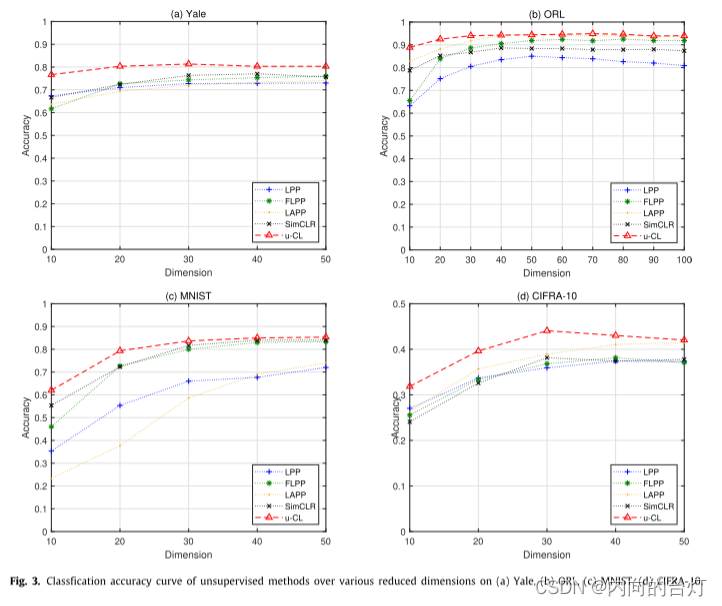
图3. 在四种数据集上各种降维的无监督方法的分类精度曲线。
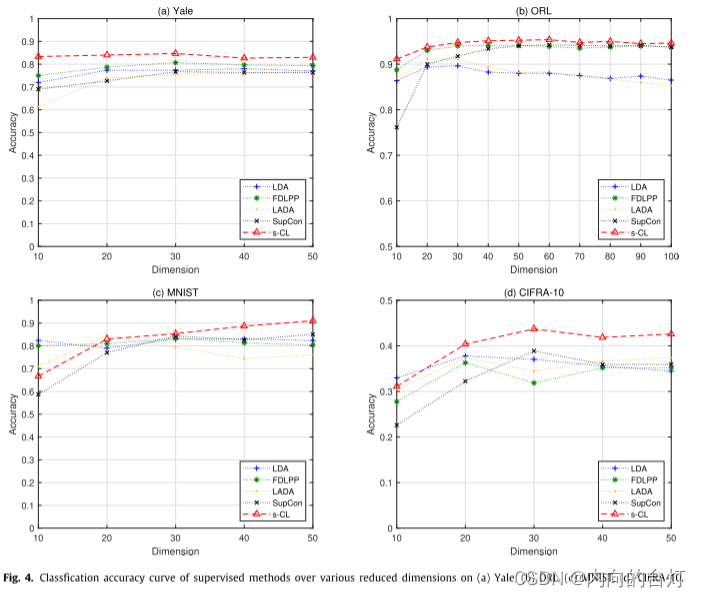
图4. 在四种数据集上不同降维下有监督方法的分类精度曲线。
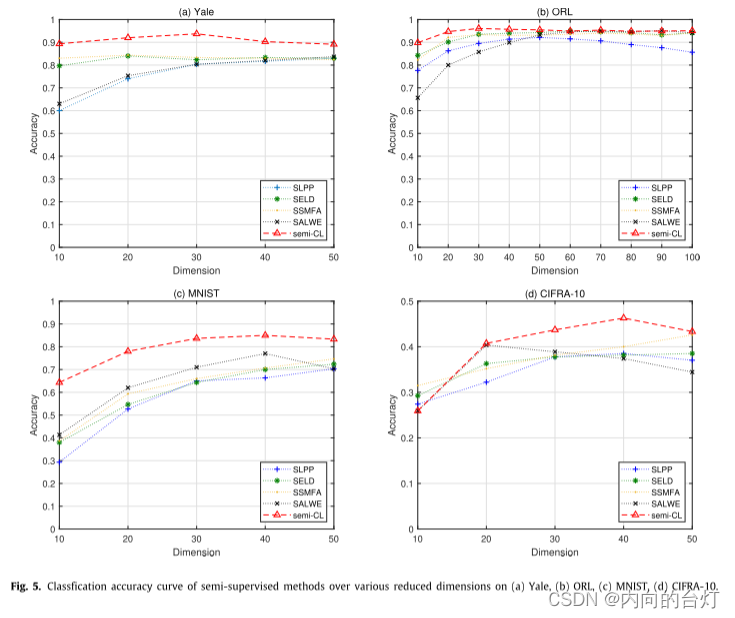
图5. 在四种数据集上不同降维下半监督方法的分类精度曲线。
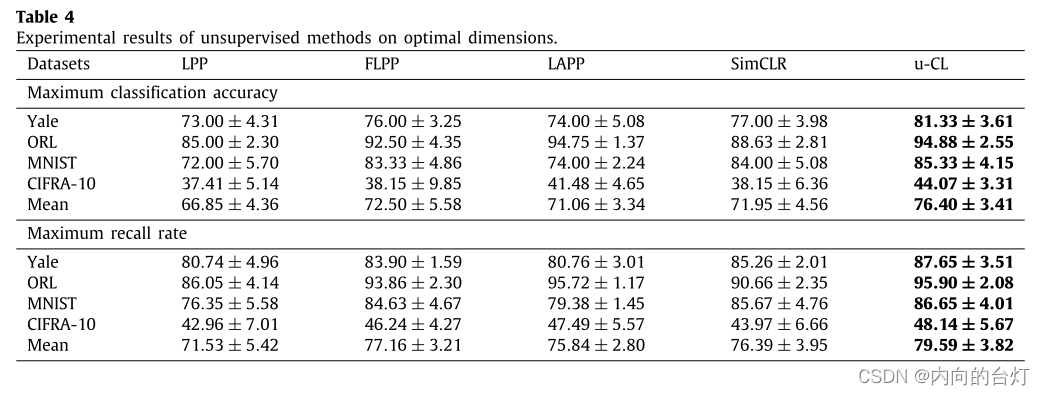
Item 1. u-CL vs. traditional unsupervised methods
从表4可以看出,u-CL在所有数据集上的最大分类准确率均高于所有比较方法,平均比LPP、FLPP、LAPP和SimCLR分别高9.55%、3.90%、5.34%和4.45%。此外,u-CL的最大召回率高于所有数据集的所有比较,平均分别比LPP、FLPP、LAPP和SimCLR高8.06%、2.43%、3.75%和3.20%。如图3所示,u-CL曲线位于所有数据集上所有不同维度下的所有比较方法的上方。
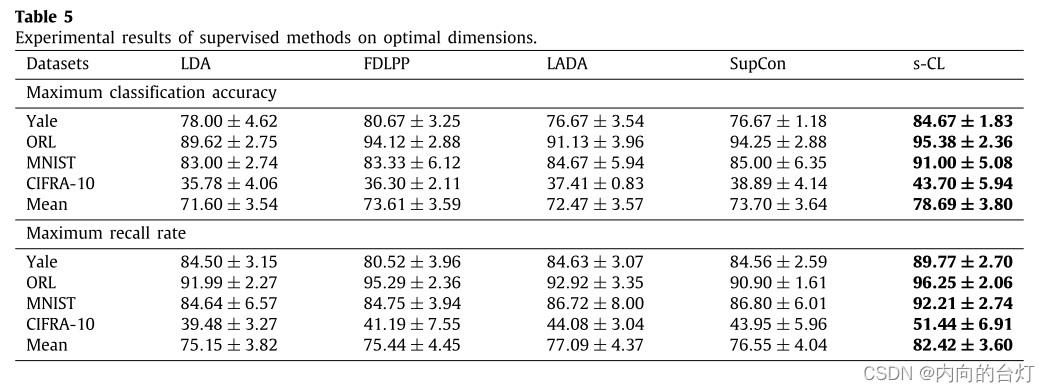
Item 2. s-CL vs. traditional supervised methods
从表5中可以看出,s-CL在所有数据集上的最大分类准确率均高于所有比较方法,平均分别比LDA、FDLPP、LADA和SupCon高7.09%、5.08%、6.22%和4.99%。此外,s-CL的最大召回率高于所有数据集的所有比较,平均分别比LDA、FDLPP、LADA和SupCon高7.27%、6.98%、5.33%和5.87%。如图4所示,s-CL曲线位于所有数据集上所有不同维度下的所有比较方法之上。
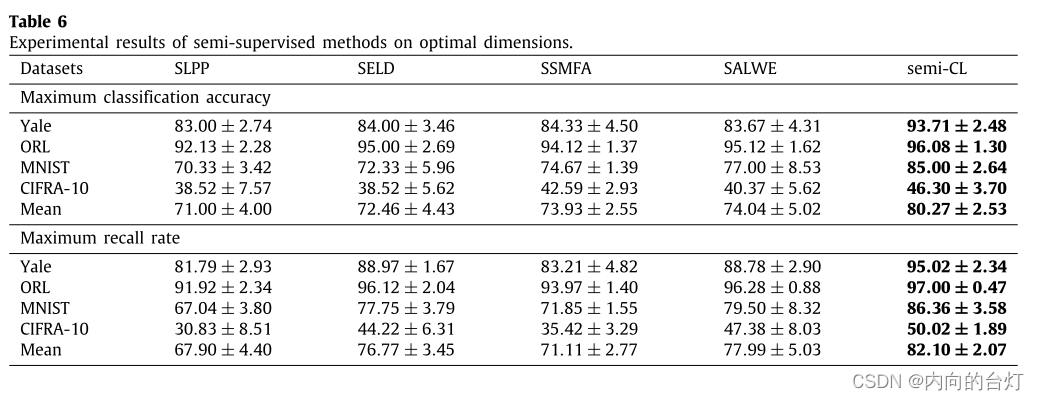
Item 3. semi-CL vs. traditional semi-supervised methods
从表6可以看出,semi-CL在所有数据集上的最大分类准确率均高于所有比较方法,平均比SLPP、SELD、SSMFA和SALWE分别高9.27%、7.81%、6.34%和6.23%。此外,semi-CL的最大召回率高于所有数据集的所有比较,平均分别比SLPP、SELD、SSMFA和SALWE高14.41%、5.33%、10.99%和4.11%。如图5所示,在所有数据集的所有不同维度下,semi-CL曲线位于所有比较方法之上。
在真实数据集上添加噪声
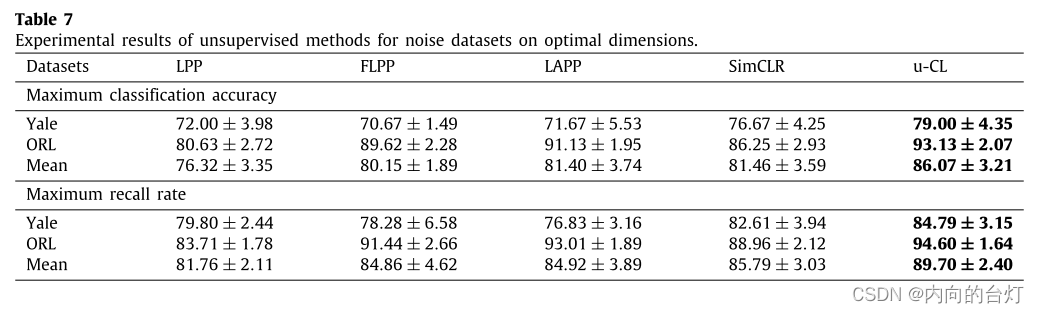
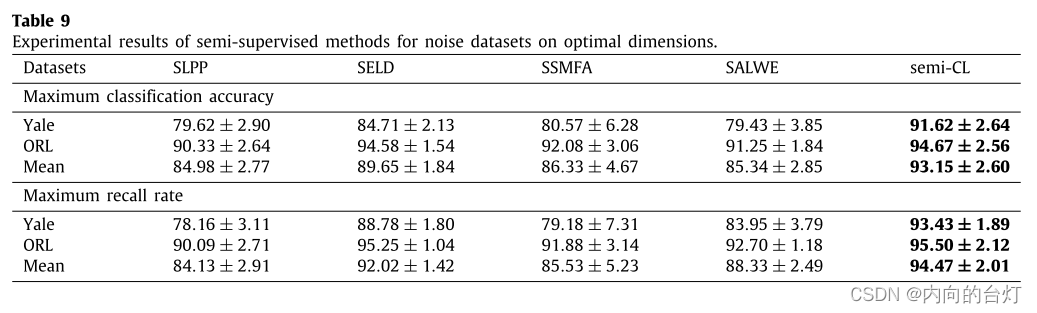
然后,为了验证所提方法的鲁棒性,在Yale和ORL数据集上,随机选取部分图像加入密度为10%的salt and pepper(椒盐)噪声。最大分类准确率(含标准)和最大召回率(含标准)如表7、表8和表9所示,其中"Mean"表示两个数据集上方法的最大分类准确率或最大召回率的平均值。每个数据集最合适的结果以粗体标记。此外,图6、图7和图8给出了各种降维方法的分类精度。基于实验结果记录以下观察结果。
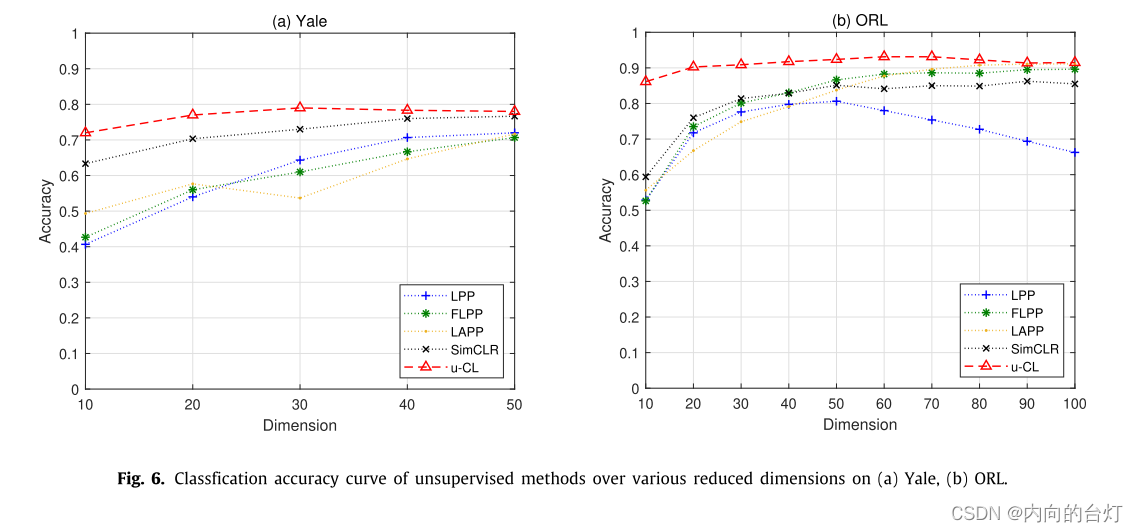
图6. 在Yale和ORL数据集上,不同降维下,无监督方法的分类精度曲线。
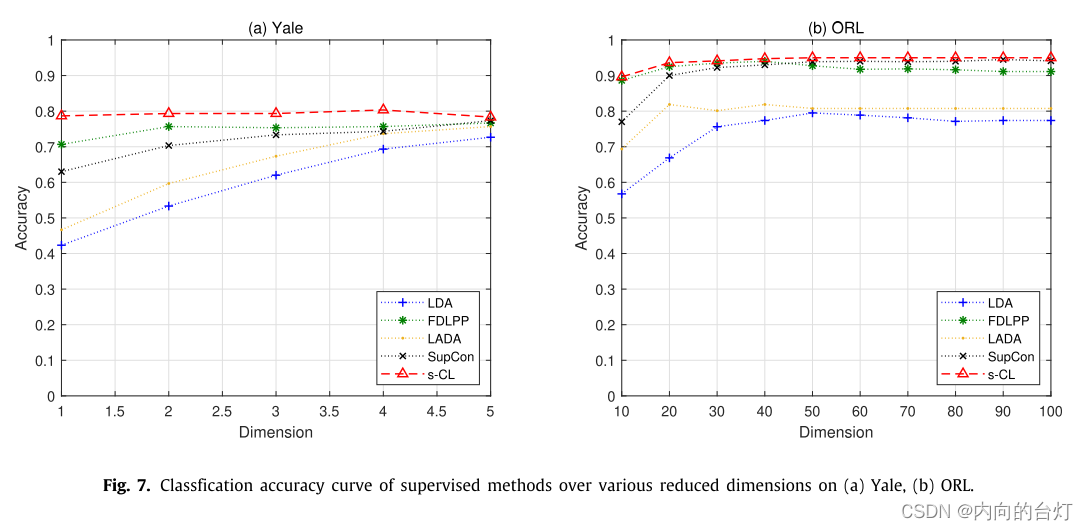
图7. 在Yale和ORL数据集上,不同降维下,有监督方法的分类精度曲线。
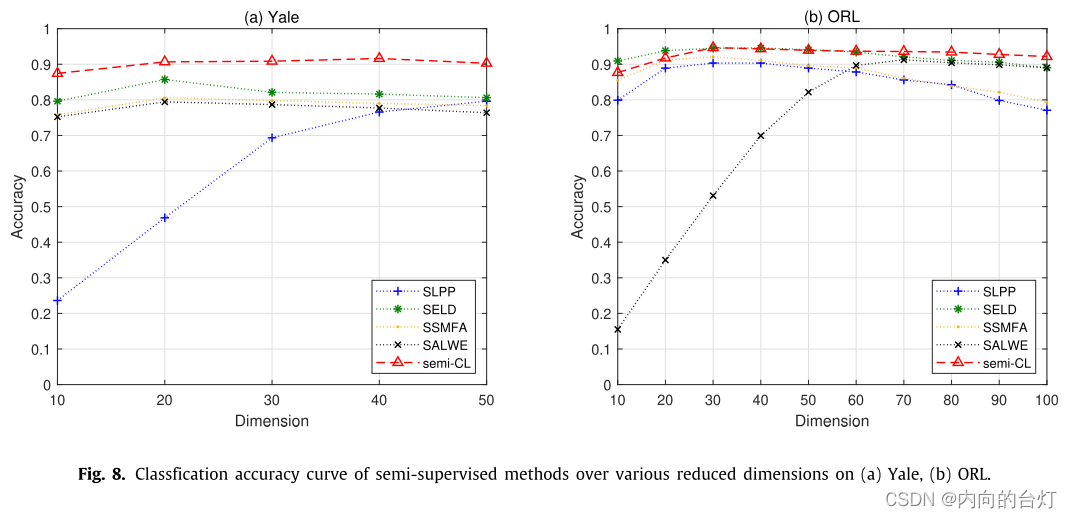
图8. 在Yale和ORL数据集上,不同降维下,半监督方法的分类精度曲线。
Item 4. u-CL vs. traditional unsupervised methods for noisy data
从表7可以看出,u-CL在所有数据集上的最大分类准确率均高于所有比较方法,平均比LPP、FLPP、LAPP和SimCLR分别高9.75%、5.92%、4.67%和4.61%。此外,u-CL的最大召回率高于所有数据集的所有比较,平均分别比LPP、FLPP、LAPP和SimCLR高7.94%、4.84%、4.78%和3.91%。如图6所示,u-CL曲线位于所有数据集上所有不同维度下所有比较方法的上方。
Item 5. s-CL vs. traditional supervised methods for noisy data
从表8中可以看出,s-CL在所有数据集上的最大分类准确率均高于所有比较方法,平均分别比LDA、FDLPP、LADA和SupCon高13.62%、4.33%、10.89%和3.75%。此外,对于所有数据集,s-CL的最大召回率均高于所有比较方法,平均分别比LDA、FDLPP、LADA和SupCon高10.38%、2.87%、10.18%和3.19%。如图7所示,u-CL曲线位于所有数据集上所有不同维度下所有比较方法的上方。

Item 6. semi-CL vs. traditional semi-supervised methods for noisy data
从表9可以看出,semi-CL在所有数据集上的最大分类准确率均高于所有比较方法,平均比SLPP、SELD、SSMFA和SALWE分别高8.17%、3.50%、6.82%和7.81%。此外,semi-CL的最大召回率高于所有数据集的所有比较方法,平均分别比SLPP、SELD、SSMFA和SALWE高10.34%、2.45%、8.94%和6.14%。如图8所示,semi-CL曲线位于所有数据集上几乎所有不同维度下的所有比较方法之上。
从以上实验结果可以看出,无论数据集是否加入噪声,CL-FEFA框架在无监督、监督和半监督特征提取方面都表现出明显的优势。特别地,与SimCLR和SupCon相比,我们框架的优势证明了对比学习中自适应构造正负样本的方法更有利于解决传统的特征提取问题。
4.5. Parameter sensitivity analysis(参数敏感性分析)
在本节中,在Yale数据集上测试了拟定u-CL、s-CL和semi-CL的参数敏感性。u-CL和semi-CL包含三个参数
k
k
k、
σ
σ
σ和
λ
λ
λ,而s-CL只有两个参数
k
k
k和
σ
σ
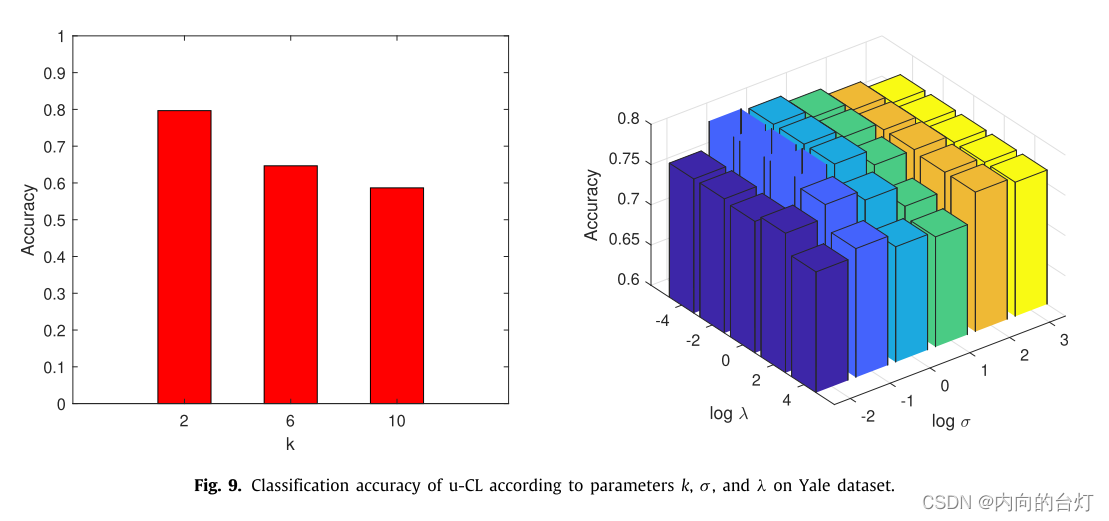
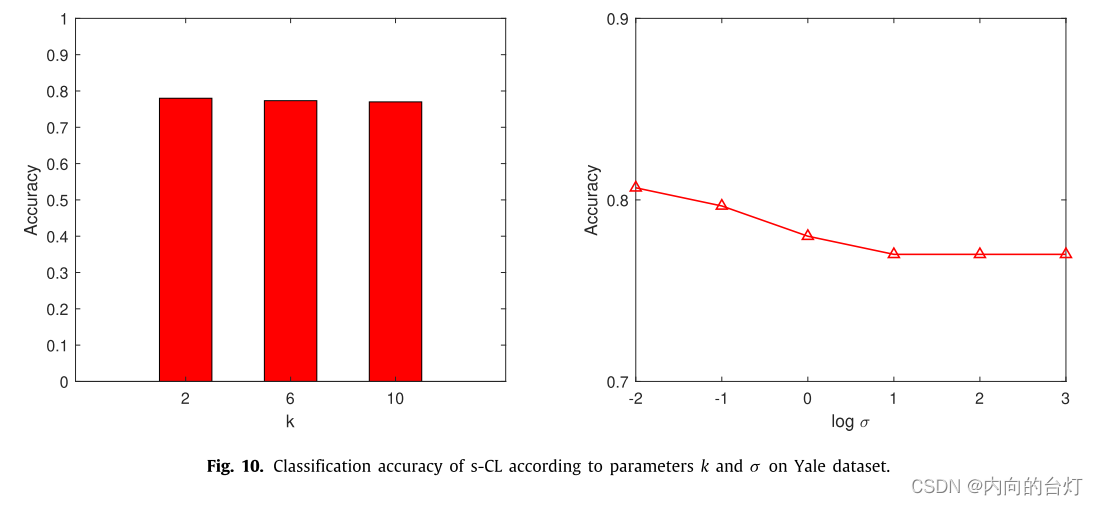
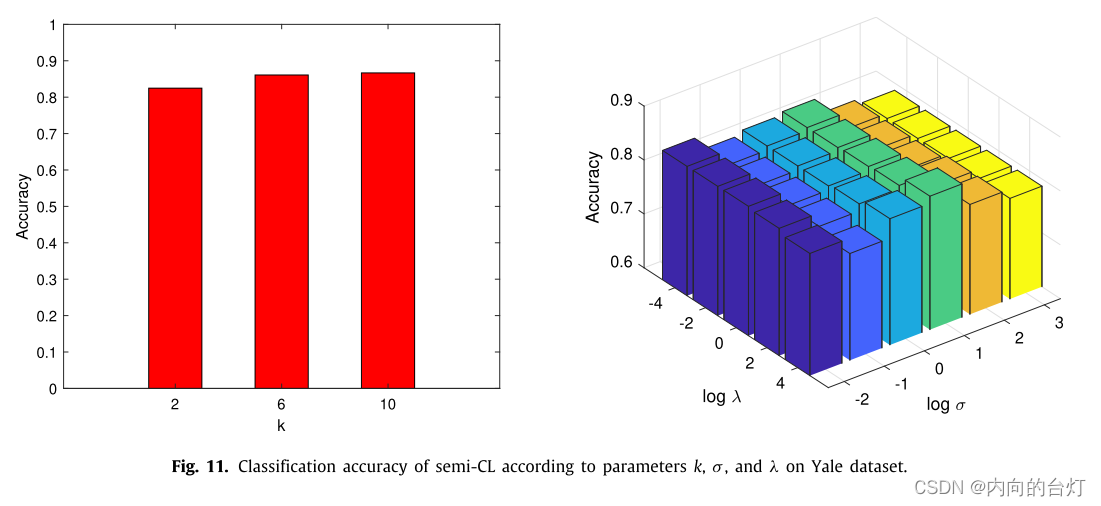
σ。基于分类准确率随图9、10和11中参数值变化的情况,分析了所提方法的灵敏度。总体而言,在Yale数据集上,u-CL和semi-CL对参数
k
k
k的变化较为敏感,而s-CL对参数
k
k
k的变化相对不敏感。在Yale数据集上,u-CL和semi-CL对参数
σ
σ
σ和
λ
λ
λ的变化比较敏感,s-CL对参数
σ
σ
σ的变化比较敏感。因此,参数的选择对于所提出的CL-FEFA是重要的。
4.6. Convergence analysis(收敛性分析)
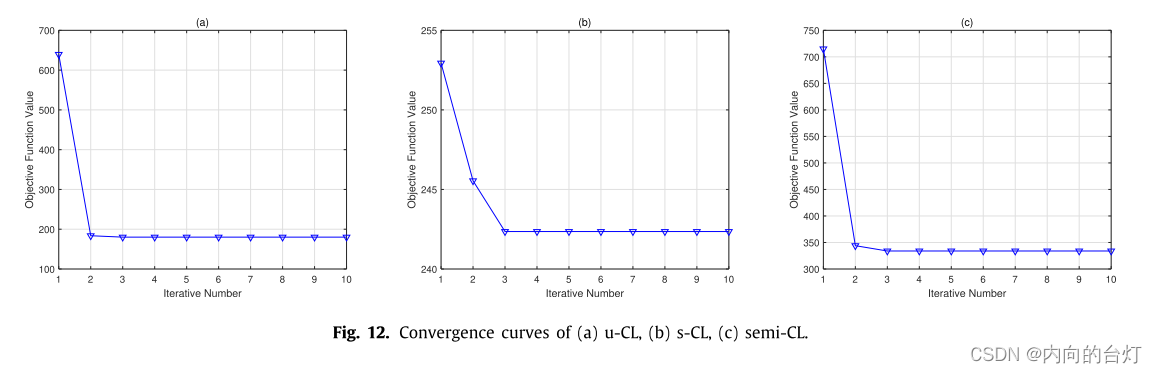
在Yale数据集上,通过多次迭代evaluated(计算、评估)了u-CL,s-CL和semi-CL的收敛性。此外,在每次迭代中获得损失函数值,并且在所提出的框架中(s-CL中λ = 0),当k = 2、σ = 0.01和λ = 0.0001时,损失函数值随迭代次数的变化如图12所示。很明显,所提出的算法可以在3到10次迭代内收敛。
5. 结论
在本研究中,我们提出了一个基于自适应正负样本对比学习的统一特征提取框架(CL-FEFA),该框架适用于无监督、有监督和半监督的single-view(单视图)特征提取。CL-FEFA自适应地从特征提取的结果中构造正负样本,使正负样本更加恰当和准确。同时,在自适应正负样本的基础上,根据InfoNCE损失提取判别特征,使类内样本更加紧凑,类间样本更加分散。在此过程中,利用子空间样本的潜在结构信息动态构造正负样本,使框架对噪声数据具有更强的鲁棒性。此外,证明了CL-FEFA实际上最大化了正样本的互信息,捕捉了潜在结构空间中相似样本之间的non-linear statistical dependencies(非线性统计依赖性),因此可以作为真实依赖性的度量。这也为它在特征提取方面的优势提供了理论支持。最后的数值实验表明,与传统的特征提取方法和对比学习方法相比,该框架具有很强的优越性。
但是,我们的框架包含许多参数,因此在大数据背景下调整所有参数以获得最优投影是困难和昂贵的。同时,现实世界中multi-view data(多视图数据)容易获取,而我们的框架只适用于single-view(单视图)情况,因此根据多视图数据的特点设计一套基于对比学习的多视图特征提取算法是非常有意义的。最后,我们将在未来继续研究基于对比学习的特征提取算法。

















 2323
2323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









