







简介:本Python3脚本旨在提高开发效率,自动化处理在Linux内核或uboot项目中查找头文件依赖的过程。该脚本对于理解和管理嵌入式系统开发中的头文件依赖关系至关重要,因为它直接影响编译和链接过程。使用Python3编写的脚本,使开发者可以避免手动搜索的繁琐和错误,使得整个开发流程标准化。开源特性鼓励社区协作和技术进步。 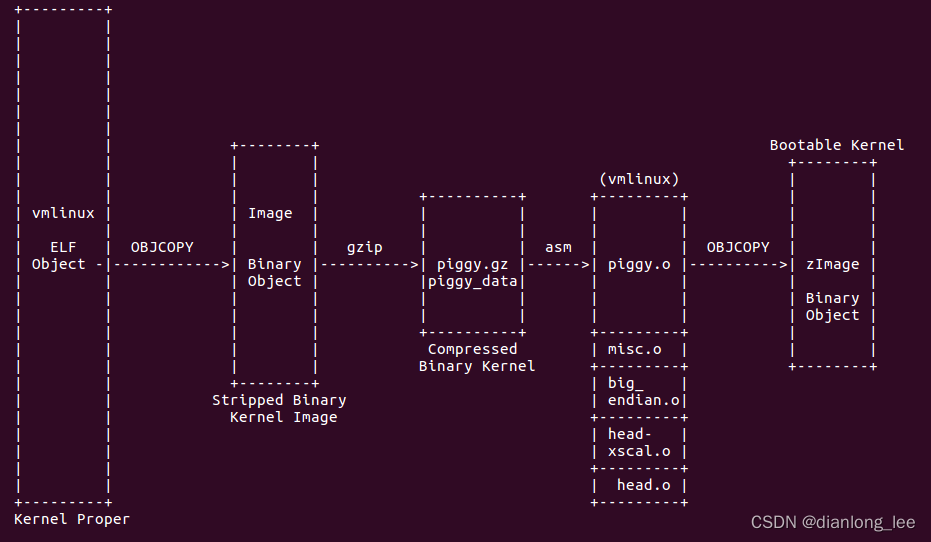
1. 自动化头文件搜索的重要性与实现
1.1 自动化头文件搜索的必要性
在现代软件开发中,头文件的管理和引用是保证程序能够正确编译的基础。随着项目的规模增大,手动管理头文件不仅效率低下,而且容易出错。自动化头文件搜索工具的出现,极大地提升了开发人员的工作效率,减少了因头文件路径错误导致的编译失败。自动化工具能够快速定位和管理头文件路径,保持头文件的更新同步,确保开发流程的顺畅。
1.2 实现自动化头文件搜索的思路
要实现自动化头文件搜索,需要遵循以下步骤:
- 分析代码结构 :扫描项目中的源文件和头文件,建立它们之间的依赖关系。
- 头文件索引 :创建索引机制,使得搜索工具可以快速检索头文件位置。
- 路径解析 :实现一个算法来解析和优化头文件的查找路径。
- 跨平台兼容性 :确保搜索工具能够适应不同操作系统的文件系统差异。
接下来的章节会深入探讨如何构建一个高效的自动化头文件搜索工具,并优化其性能以适应各种复杂的开发环境。
2. 嵌入式系统开发中的Python应用
随着技术的发展,嵌入式系统开发不再局限于传统的C/C++语言。Python作为一种高级编程语言,因其简洁的语法和强大的库支持,在嵌入式系统开发领域扮演着越来越重要的角色。在本章节中,我们将深入探讨Python在嵌入式开发中的应用,包括与C/C++的结合方式、环境搭建,以及Python脚本在uboot和Linux内核中的作用。
2.1 Python在嵌入式开发中的角色
Python的语言特性,如动态类型、自动内存管理和丰富的标准库,使其成为开发效率极高的语言。在嵌入式系统中,它可用于快速原型设计、测试、以及作为系统管理工具等。
2.1.1 Python与C/C++的结合方式
在嵌入式系统中,Python经常与C/C++结合起来使用,发挥各自的长处。Python可以用来编写应用层的代码和快速开发工具,而C/C++则处理性能敏感的底层任务。
- Cython和CFFI :这些工具允许Python与C代码进行交互,Cython将Python代码编译成C代码,从而提供性能上的优势,而CFFI(C Foreign Function Interface)提供了一种调用C库的机制。
- 嵌入式Python :Python解释器可以被编译进嵌入式设备固件中,作为应用程序的一部分运行。这种方式需要在设备上配置Python运行环境,确保解释器和相关的库文件被正确集成。
2.1.2 嵌入式Python环境搭建
嵌入式Python环境的搭建通常涉及以下步骤:
- 选择合适的Python解释器版本 :根据嵌入式设备的处理器架构和内存限制选择一个轻量级的Python解释器,如MicroPython或CircuitPython。
- 交叉编译解释器 :使用交叉编译工具链针对目标嵌入式平台编译Python解释器。
- 准备Python模块 :根据项目需求选择和准备需要的Python标准库和第三方库,并确保它们与嵌入式平台兼容。
- 集成到固件 :将编译好的解释器、模块和应用程序代码集成到嵌入式设备的固件中。
# 示例:使用arm交叉编译器编译Python解释器
$ export CROSS_COMPILE=arm-none-eabi-
$ ./configure --host=arm-none-eabi
$ make
$ make install
2.2 Python脚本在uboot和Linux内核中的作用
嵌入式设备的启动加载程序(如uboot)和操作系统内核(如Linux内核)是嵌入式系统的核心组件。Python脚本在这些组件中可以实现自动化处理和与硬件设备的交互。
2.2.1 脚本自动化处理流程
Python脚本可以在嵌入式系统开发的多个阶段提供自动化支持:
- 构建自动化 :通过编写脚本,自动化配置和编译uboot和Linux内核。
- 测试自动化 :在硬件上运行测试脚本,验证系统功能和性能。
- 部署自动化 :将固件和应用程序部署到设备上的过程自动化。
# 示例:自动化构建uboot的Python脚本片段
import os
def build_uboot(board):
os.chdir(f'./uboot-{board}')
os.system('make clean')
os.system(f'make {board}_defconfig')
os.system('make')
build_uboot('raspberrypi')
2.2.2 脚本与嵌入式设备的交互方式
Python脚本可以通过多种方式与嵌入式设备进行交互:
- 串口通信 :使用Python的
serial库与设备进行串口通信。 - 网络通信 :通过网络接口发送和接收数据。
- 设备文件操作 :直接操作设备文件进行硬件控制。
# 示例:使用Python串口库发送数据到嵌入式设备
import serial
# 创建串口连接
ser = serial.Serial('/dev/ttyUSB0', 9600)
ser.write(b'Hello, Embedded World!\n')
ser.close()
通过结合Python的高级特性与嵌入式系统的实际需求,可以大大提升开发效率和系统维护的便捷性。下一章节,我们将深入了解Linux内核和uboot项目的构成与工作原理,探讨如何更有效地在这些系统中利用Python进行开发。
3. Linux内核和uboot项目的深入了解
3.1 Linux内核的基本构成和工作原理
3.1.1 内核模块与驱动程序
Linux内核是操作系统的核心,负责管理硬件资源以及提供系统服务。内核的一个主要功能是模块化,允许动态地加载和卸载内核模块。这些模块通常是驱动程序,用来支持硬件设备,或者提供系统服务,如文件系统。
模块化驱动程序的优势在于:
- 可扩展性 :用户可以根据需求动态加载或卸载驱动程序。
- 维护性 :更新驱动程序不需要重启系统。
- 系统稳定性 :单个模块的问题通常不会影响整个系统。
Linux内核驱动程序的编写遵循一定的结构,其中包含诸如初始化函数、清理函数以及与硬件通信的函数等关键部分。驱动程序通常需要处理中断、内存管理以及与特定硬件相关的一些操作。
编写Linux驱动程序的一个简单例子:
#include <linux/module.h> // 必须包含的头文件,用于所有模块
#include <linux/kernel.h> // 包含KERN_INFO等内核日志级别的定义
#include <linux/init.h> // 包含module_init和module_exit宏
static int __init driver_init(void) {
printk(KERN_INFO "Loading myDriver module...\n");
// 驱动程序初始化代码
return 0; // 如果成功加载则返回0
}
static void __exit driver_cleanup(void) {
printk(KERN_INFO "Cleaning up myDriver module...\n");
// 驱动程序清理代码
}
module_init(driver_init); // 指定加载模块时调用的函数
module_exit(driver_cleanup); // 指定卸载模块时调用的函数
该代码段是一个非常基础的Linux内核模块模板,其中包含了初始化函数 driver_init 和清理函数 driver_cleanup 。 module_init 和 module_exit 宏用于声明模块加载和卸载时需要调用的函数。
3.1.2 内核版本演进与特性分析
Linux内核自诞生以来经历了多个版本的演进,每一个版本的发布都带来了一系列新特性和改进。随着新硬件的不断出现和旧硬件的逐渐淘汰,内核也在持续地适应这些变化,以支持新的技术和标准。
Linux内核版本通常遵循主次版本号的命名规则,例如 5.11 ,其中 5 是主版本号, 11 是次版本号。次要版本号的奇数表示正在开发中的版本,偶数表示稳定版本。
内核版本的特性分析通常包括以下几个方面:
- 架构支持 :新版本的内核支持更多的处理器架构。
- 驱动更新 :提供了更多新硬件的驱动程序。
- 性能改进 :优化了现有系统的性能,例如文件系统操作和进程调度。
- 安全强化 :增强了系统的安全性,如支持新的安全特性。
- 支持新的协议 :例如IPv6、新的文件系统等。
查看特定内核版本的变更日志是了解特性演进的一个很好的方式。例如,通过访问内核官方网站或查看源代码提交日志,开发者可以跟踪各个版本之间的变化。
3.2 uboot的作用与实现机制
3.2.1 uboot的引导过程解析
uboot是一个流行的开源引导加载程序,它在嵌入式系统启动过程中扮演着至关重要的角色。其主要作用是在系统加电后初始化硬件设备,并加载操作系统的内核到RAM中去运行。
uboot的引导过程大致可以分为以下几个阶段:
- 硬件初始化 :uboot首先会初始化CPU、内存以及必要的外设。
- 环境变量设置 :uboot会加载环境变量,这些变量定义了启动过程的许多参数,如内核映像的位置和内存大小等。
- 加载内核 :uboot从存储介质(如NAND、NOR闪存、SD卡等)读取操作系统内核映像,并将其加载到RAM中。
- 启动内核 :完成加载后,uboot将执行跳转指令,将控制权传递给内核,内核开始初始化并启动系统。
uboot通过一系列命令行交互,支持配置和修改这些参数,提供了极大的灵活性和控制能力。
3.2.2 uboot与Linux内核的交互
uboot与Linux内核之间的交互主要涉及到硬件配置、内存管理以及启动参数的传递。这种交互可以通过uboot的环境变量以及设备树(Device Tree)来实现。
在uboot中,环境变量可以存储大量的启动参数,这些参数会传递给Linux内核。比如内核启动参数(Kernel Command Line Arguments)就是通过这种方式设置的,它们可以影响内核的行为,例如指定根文件系统的类型、启动特定的驱动程序等。
设备树是一种数据结构,用于描述硬件设备信息。uboot可以解析设备树来了解系统中有哪些硬件设备,以及它们的配置。然后uboot将这些信息传递给Linux内核,内核利用这些信息来正确初始化和使用硬件设备。
例如,在uboot命令行中,开发者可以使用 printenv 命令查看当前的环境变量,使用 setenv 命令修改环境变量,使用 fdt 命令来操作设备树信息。
uboot> printenv bootargs
bootargs=root=/dev/nfs rw nfsroot=192.168.1.1:/nfsroot ip=192.168.1.101
uboot> setenv bootargs root=/dev/nfs rw nfsroot=192.168.1.1:/nfsroot ip=192.168.1.101
uboot> printenv bootargs
bootargs=root=/dev/nfs rw nfsroot=192.168.1.1:/nfsroot ip=192.168.1.101
uboot> fdt addr ${fdt_addr}
uboot> fdt print /chosen
以上代码展示了在uboot命令行中如何查看、设置环境变量,以及如何查看和操作设备树。这些操作对于理解uboot如何准备并启动Linux内核至关重要。
在下一部分,我们将深入探讨Linux内核的模块化和驱动程序的实现细节,以及uboot引导过程的更多技术细节。
4. Python编程基础与脚本编写技巧
在今天的IT行业中,Python已成为一种多用途、强大且广泛使用的编程语言。它拥有一个庞大而活跃的社区,提供了丰富的库和框架来支持各种项目,从小型脚本到大型应用程序。在第四章中,我们将深入探讨Python编程的基础知识和脚本编写技巧,为读者提供必要的知识基础,以便在嵌入式系统开发和其他领域中有效地利用Python。
4.1 Python编程基础要求
4.1.1 Python语法要点回顾
Python的设计哲学强调代码的可读性和简洁的语法(尤其是使用空格缩进来定义代码块,而非使用大括号或关键字)。基础语法是Python编程的基石,以下是几个关键点:
- 变量和数据类型 :Python是一种动态类型语言,变量在使用之前无需声明类型。基本数据类型包括整型、浮点型、字符串、列表、元组、字典等。
# 示例代码:基本数据类型的操作
a = 10 # 整型
b = 10.5 # 浮点型
c = "Hello, World!" # 字符串
d = [1, 2, 3] # 列表
e = (1, 2, 3) # 元组
f = {"key": "value"} # 字典
- 控制结构 :条件语句(if-elif-else)和循环语句(for, while)是实现程序逻辑控制的基本工具。
# 示例代码:条件语句和循环语句的使用
if a > b:
print("a is greater than b")
elif a == b:
print("a is equal to b")
else:
print("a is less than b")
for i in range(5): # 等同于C/C++中的for (int i = 0; i < 5; i++)
print(i)
i = 0
while i < 5:
print(i)
i += 1
- 函数定义 :函数是组织好的、可重复使用的代码块,用于执行特定任务。
# 示例代码:函数定义
def greet(name):
return "Hello, " + name + "!"
print(greet("Alice"))
4.1.2 面向对象编程基础
面向对象编程(OOP)是Python的核心之一。OOP涉及到类(class)和对象(object)的概念,它通过封装、继承和多态来实现代码的复用和模块化。
# 示例代码:面向对象编程
class Person:
def __init__(self, name):
self.name = name
def greet(self):
return "Hello, my name is " + self.name
# 创建一个Person类的实例
person = Person("Bob")
print(person.greet()) # 输出: Hello, my name is Bob
4.2 Python脚本高级功能实现
4.2.1 文件与目录操作
Python提供了一套内置的库来处理文件和目录,使文件的读写、目录的创建和遍历等操作变得简单高效。
import os
# 示例代码:文件写入和读取
with open("example.txt", "w") as file:
file.write("Hello, Python!")
with open("example.txt", "r") as file:
content = file.read()
print(content) # 输出: Hello, Python!
# 示例代码:目录的创建和遍历
os.makedirs("new_directory", exist_ok=True)
for root, dirs, files in os.walk("."):
print(f"Directory: {root}")
for file in files:
print(f"\tFile: {file}")
4.2.2 正则表达式在文本处理中的应用
正则表达式是一种用于匹配字符串中字符组合的模式。在Python中,可以使用 re 模块来实现正则表达式的功能,这在进行文本搜索、替换和验证等操作时非常有用。
import re
# 示例代码:使用正则表达式查找匹配模式
pattern = r"(\d{3})-(\d{3})-(\d{4})"
text = "Cell: 123-456-7890"
match = re.search(pattern, text)
if match:
print(match.groups()) # 输出: ('123', '456', '7890')
通过本章内容的介绍,我们已经对Python编程的基础知识有了全面的认识,并掌握了一些脚本编写中的高级技巧。这些知识点不仅对于理解后续章节中介绍的自动化工具和项目开发至关重要,也能够帮助读者在日常工作中提升编程效率和代码质量。在下一章节,我们将探索如何将Python进一步应用于Linux内核和uboot项目中,实现更深层次的自动化操作和源码管理功能。
5. Python脚本在源码管理中的应用
在现代软件开发过程中,源码管理是不可或缺的一环。Python脚本以其简洁高效的特点,在源码管理方面提供了强大的支持,尤其是对于大型项目来说,能够极大地提升开发效率和管理便捷性。本章将深入探讨如何利用Python脚本来实现源文件的解析、头文件路径搜索和源码依赖关系分析,从而更好地管理源码资源。
5.1 源文件解析功能的实现
5.1.1 源文件结构分析
源文件结构分析是了解项目代码组成和布局的首要步骤。Python通过内置的文件操作功能,可以轻松读取文件内容,并根据内容来解析文件结构。Python的 os 和 os.path 模块能够帮助我们获取文件系统信息,而正则表达式则在解析代码结构时起到了重要作用。
代码块示例如下:
import os
import re
def analyze_source_file(file_path):
file_structure = {}
with open(file_path, 'r') as file:
content = file.readlines()
for line in content:
if re.match(r'^\s*#\s*include\s+<', line):
include_statement = re.match(r'#include\s+<(.+?)>', line)
if include_statement:
file_structure.setdefault('includes', []).append(include_statement.group(1))
elif re.match(r'^\s*#\s*define\s+', line):
define_statement = re.match(r'#define\s+(\w+)', line)
if define_statement:
file_structure.setdefault('defines', []).append(define_statement.group(1))
# 其他需要解析的结构...
return file_structure
file_path = 'example.c'
structure = analyze_source_file(file_path)
print(structure)
逻辑分析:这个示例代码块读取了一个C语言源文件,并解析了包含的头文件和宏定义。代码中使用了 re 模块来匹配正则表达式,从而提取文件中的特定结构。分析结果会以字典形式存储,便于后续使用。
参数说明: file_path 参数指定了要分析的文件路径。 analyze_source_file 函数逐行读取源文件,使用正则表达式匹配头文件包含和宏定义语句。
5.1.2 源文件头信息提取技巧
头文件通常包含了重要的声明信息,例如宏定义、类型定义和函数声明等。Python的正则表达式模块 re 可以用来识别和提取这些信息。
import re
def extract_header_info(file_path):
header_info = {}
with open(file_path, 'r') as file:
content = file.read()
macros = re.findall(r'#define\s+(\w+)\s+(.+)', content)
types = re.findall(r'typedef\s+(.+?)\s+(\w+);', content)
functions = re.findall(r'(\w+)\s+(\w+)\(([^)]*)\)', content)
header_info['macros'] = macros
header_info['types'] = types
header_info['functions'] = functions
return header_info
file_path = 'example.h'
header_info = extract_header_info(file_path)
print(header_info)
逻辑分析:这段代码读取了一个头文件,并提取了其中的宏定义、类型定义和函数声明。正则表达式用于匹配这些结构,并将结果存储在字典中。
参数说明: file_path 参数指定了要提取信息的头文件路径。通过正则表达式识别不同的代码结构,并以列表的形式存入字典。
5.2 头文件路径搜索功能的构建
5.2.1 路径搜索算法与优化
在大型项目中,源文件通常依赖于多个头文件。正确地搜索头文件路径是构建搜索功能的关键。使用深度优先搜索(DFS)或广度优先搜索(BFS)算法来遍历文件系统是常见的解决方案。优化算法可以通过缓存已搜索路径的方式来加快查找速度。
import os
import re
from collections import deque
def search_header_path(header_name, include_dirs):
for include_dir in include_dirs:
file_path = os.path.join(include_dir, header_name)
if os.path.exists(file_path):
return file_path
return None
def dfs_search_header(header_name, include_dirs, visited_dirs):
stack = deque([header_name])
visited_dirs.add(header_name)
while stack:
current_header = stack.pop()
result = search_header_path(current_header, include_dirs)
if result:
return result
# 递归搜索可能存在的包含路径...
return None
include_dirs = ['/usr/include', '/usr/local/include']
header_name = 'example.h'
found_path = dfs_search_header(header_name, include_dirs, set())
print(found_path)
逻辑分析:这段代码实现了一个基于DFS的头文件搜索算法,搜索过程中会检查每个可能的路径是否存在头文件。 search_header_path 函数用于检查单个路径。 dfs_search_header 函数使用了 deque 数据结构来进行深度优先搜索。
参数说明: include_dirs 参数是一个包含了所有可能包含头文件的目录的列表。 header_name 是要搜索的头文件名称。 visited_dirs 用于记录已经访问过的路径,防止重复搜索。
5.2.2 跨平台兼容性处理
头文件搜索功能在不同的操作系统上可能会面临不同的挑战,比如文件路径格式的差异。为了增强代码的跨平台兼容性,应当使用Python的 os 模块来处理路径分隔符和路径格式问题。
import os
def normalize_path(path):
return os.path.normpath(path)
def build_cross_platform_header_search(include_dirs):
normalized_dirs = [normalize_path(dir) for dir in include_dirs]
return normalized_dirs
include_dirs = ['/usr/include', 'C:\\Program Files\\include']
normalized_dirs = build_cross_platform_header_search(include_dirs)
print(normalized_dirs)
逻辑分析: normalize_path 函数使用 os.path.normpath 方法来标准化路径。这是因为在不同的操作系统中,路径格式可能会有所不同。例如,在Unix/Linux系统中使用正斜杠(/),而在Windows系统中使用反斜杠(\)。通过这种方式,可以确保代码在不同平台上都能正确运行。
参数说明: include_dirs 是一个包含多个头文件搜索目录的列表。通过标准化这些路径,我们可以确保脚本在任何操作系统中都能够正确解析路径。
5.3 源码依赖关系分析
5.3.1 依赖关系提取与可视化
一个源码项目往往由多个文件组成,这些文件之间可能存在复杂的依赖关系。Python可以用来提取这些依赖关系,并将其可视化,以便于项目管理和维护。
import ast
def extract_dependencies(file_path):
with open(file_path, 'r') as file:
source_code = file.read()
tree = ast.parse(source_code)
dependencies = [n.id for n in ast.walk(tree) if isinstance(n, ast.Name) and n.id != 'print']
return dependencies
file_path = 'example.c'
dependencies = extract_dependencies(file_path)
print(dependencies)
逻辑分析:这段代码使用Python的抽象语法树(AST)模块来分析源码中的依赖关系。AST能够解析源代码结构,从而提取出代码中使用的变量、函数名、宏定义等。
参数说明: file_path 参数指定要分析的源文件。 ast.parse 函数用于解析源代码并构建AST。最后,遍历AST树以提取依赖关系。
5.3.2 代码模块化对维护的影响
模块化的代码可以让维护变得更加容易。模块化有助于代码重用,减少了重复代码的编写,提高了开发效率。Python的模块化概念较为简单易懂,通过import语句可以很便捷地引入其他模块。因此,通过Python脚本提取模块间的依赖关系,可以直观地展示项目的模块化程度。
import networkx as nx
def visualize_dependencies(dependencies):
G = nx.DiGraph()
for dep in dependencies:
G.add_node(dep)
# 假设源码中有函数调用依赖关系,以A->B表示A依赖B
if dep in dependency_map and dependency_map[dep]:
for target in dependency_map[dep]:
G.add_edge(dep, target)
# 使用NetworkX生成并保存依赖关系图
pos = nx.spring_layout(G)
nx.draw(G, pos, with_labels=True)
plt.savefig('dependencies.png')
dependency_map = {'example.c': ['header.h', 'functions.h']}
visualize_dependencies(dependency_map.keys())
逻辑分析:此代码块利用了 networkx 库来创建一个有向图,并根据提取的依赖关系生成图形化展示。这个依赖图可以清晰地展示模块间的依赖关系,帮助开发者理解项目的整体结构。
参数说明: dependency_map 是一个字典,记录了文件及其依赖的其他文件。 visualize_dependencies 函数接收依赖关系作为输入,构建一个有向图,并通过 networkx 库来绘制和保存这个依赖关系图。
以上章节通过不同的子章节内容深度介绍了如何利用Python脚本在源码管理中实现源文件解析、头文件路径搜索功能和源码依赖关系分析。通过实例化的代码块及详细的逻辑分析,我们展示了Python在自动化源码管理任务中的强大功能与灵活性。
6. 项目成果展示与开源特性分析
6.1 报告输出功能的介绍
在软件开发过程中,项目成果的展示是不可或缺的一环。它不仅可以用来记录项目的进展,还能作为团队间沟通的重要依据。报告输出功能的设计便是为了满足这种需求,将开发过程中的各种数据以一种易于理解的格式呈现给用户。
6.1.1 报告格式设计
报告的格式应该清晰、直观,便于阅读者快速把握信息的核心。一般而言,报告包括以下几部分:
- 封面 :包含项目名称、报告标题、时间戳等基本信息。
- 目录 :列出报告的主要章节和页码,方便查找。
- 摘要 :对报告内容的简短概览。
- 正文 :详细介绍项目的关键信息,如性能数据、代码质量评估、发现的问题及解决方案等。
- 附录 :提供支持正文的相关资料,如原始数据、日志文件等。
在设计报告格式时,可以利用模板引擎如Jinja2或者LaTeX来实现动态内容的填充,这样可以确保报告的格式一致性,同时支持根据不同数据动态生成内容。
6.1.2 报告内容自动化生成技术
自动化生成报告的关键在于数据的收集和处理。这可以通过编写脚本与使用数据分析工具来实现。例如:
- 数据收集 :编写脚本从版本控制系统中提取提交日志、从测试框架中获取测试结果等。
- 数据分析 :使用Python等语言中的pandas库来处理和分析数据。
- 报告生成 :根据分析结果,利用模板引擎填充到报告模板中。
下面是一个简单的Python脚本示例,展示了如何使用pandas分析数据并生成报告的摘要部分:
import pandas as pd
# 假设从源码管理系统中导出的数据
data = {
'Commit ID': ['c1', 'c2', 'c3'],
'Date': ['2023-01-01', '2023-01-02', '2023-01-03'],
'Changes': [10, 3, 7]
}
df = pd.DataFrame(data)
# 简单的数据分析
total_changes = df['Changes'].sum()
# 报告摘要的生成
summary = f"""
项目的总提交次数为:{len(df)}
总改动行数为:{total_changes}
print(summary)
通过这种方式,项目管理者可以定期生成项目的状态报告,为决策提供数据支持。
6.2 项目开源特性及社区贡献
开源项目的一大特色就是其社区驱动的特性。在开源项目中,社区成员可以是贡献者、用户、测试者、反馈者或文档撰写者等角色。他们在项目的成长过程中扮演着至关重要的角色。
6.2.1 开源项目的管理与协同
开源项目的管理通常涉及以下几个方面:
- 版本控制 :使用Git等版本控制系统管理代码变更。
- 问题跟踪 :通过GitHub Issues、GitLab Issues等工具跟踪问题和功能请求。
- 文档编写 :项目文档通常托管在Read the Docs等平台,确保用户能够方便地获取使用指导。
- 代码审查 :利用Pull Requests等形式,对贡献的代码进行审查,保证代码质量。
在项目管理过程中,使用自动化工具和持续集成(CI)可以帮助团队更高效地工作。例如,GitHub Actions可以自动运行测试和部署流程,提高开发效率。
6.2.2 社区反馈与功能迭代
社区反馈是驱动项目发展的关键因素之一。有效的社区反馈机制可以帮助项目团队收集用户的需求和建议,推动项目的不断进步。功能迭代的流程通常遵循以下步骤:
- 收集反馈 :通过邮件列表、论坛、社交媒体等方式收集用户反馈。
- 优先级排序 :根据反馈的价值和难度评估,确定功能开发的优先顺序。
- 开发与测试 :根据规划进行开发,并确保通过充分的测试。
- 发布与通知 :将新功能集成到项目中,并通知社区成员更新和使用。
这一过程是迭代的,随着新版本的不断发布,项目功能会逐步完善,用户体验也会不断提升。
通过上述开源特性的分析和社区贡献的实践,我们可以看到开源项目的生命力在于社区的参与度,以及项目团队与社区成员之间的互动和协同工作。只有这样才能确保项目的健康发展,并在激烈的市场竞争中保持领先地位。
简介:本Python3脚本旨在提高开发效率,自动化处理在Linux内核或uboot项目中查找头文件依赖的过程。该脚本对于理解和管理嵌入式系统开发中的头文件依赖关系至关重要,因为它直接影响编译和链接过程。使用Python3编写的脚本,使开发者可以避免手动搜索的繁琐和错误,使得整个开发流程标准化。开源特性鼓励社区协作和技术进步。

















 2033
2033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









