







CAM-RNN: Co-Attention Model Based RNN for Video Captioning
CAM-RNN:基于RNN的视频字幕共同注意力模型
1.创新点
1.提出了一个两层的视觉注意力模型,能够自动关注最相关的帧和每一帧中突出的区域。
2.提出了一个短语级别的文本注意力模型。
3.提出了平衡门,平衡视觉注意力和文本注意力之间的影响大小。
2.研究领域目前存在的问题以及已有的解决方法
视频字幕目前有的问题:1.尽管加入了视觉注意力机制,但是仍然有一些不相关的背景信息。
2.对于文本注意力机制,前面的工作大多是基于之前单个单词的注意力机制。
3.本文提出的解决此问题的方法
4.设计的网络结构以及原理
四个部分1.视觉注意力模型2.文本注意力模型3.平衡门4.基于LSTM网络的字幕产生器。

RNN:
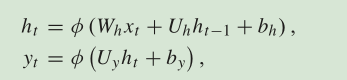
LSTM:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









