







 本文记录了一种通过Python爬取东方财富网上交所和深交所股票名称及交易信息的过程。首先分析需求,然后选择合适的股票数据源,通过浏览器开发者工具找到动态数据接口。接下来介绍如何构造请求参数,获取数据并进行处理,最终将数据保存到本地文件。代码实现虽有不足,但能完成基本功能,适合初学者参考。
本文记录了一种通过Python爬取东方财富网上交所和深交所股票名称及交易信息的过程。首先分析需求,然后选择合适的股票数据源,通过浏览器开发者工具找到动态数据接口。接下来介绍如何构造请求参数,获取数据并进行处理,最终将数据保存到本地文件。代码实现虽有不足,但能完成基本功能,适合初学者参考。
这几天把学习通的 python 爬虫相关课程给刷完了,想去动手也实践一下,重温一下很久之前学过的东西
然后发现实例2(爬淘宝那个)、实例3(爬股票那个),好像都有点问题。实例2是淘宝现在的反爬机制好像做的挺好,需要登录后才可以(当然也可能是我菜);实例3是百度的股票接口挂掉了。。

啊。。这。。
所以这篇文章以笔记的形式,记录一下另一种爬取股票数据的操作
需求分析
- 目标:获取上交所和深交所所有股票的名称和交易信息
- 输出:保存到文件中
- 技术路线:
requests & re & pandas & json
候选数据网站的选择
- 选取原则:股票信息静态存在于
HTML页面中,非js代码生成,没有 Robots 协议限制 - 获取股票列表:
- 东方财富网:http://79.push2.eastmoney.com/api/qt/clist/get(链接可能有所变化,不能直接打开,需要传递参数,请看下问分解)
基本思路
- 打开 东方财富网行情中心
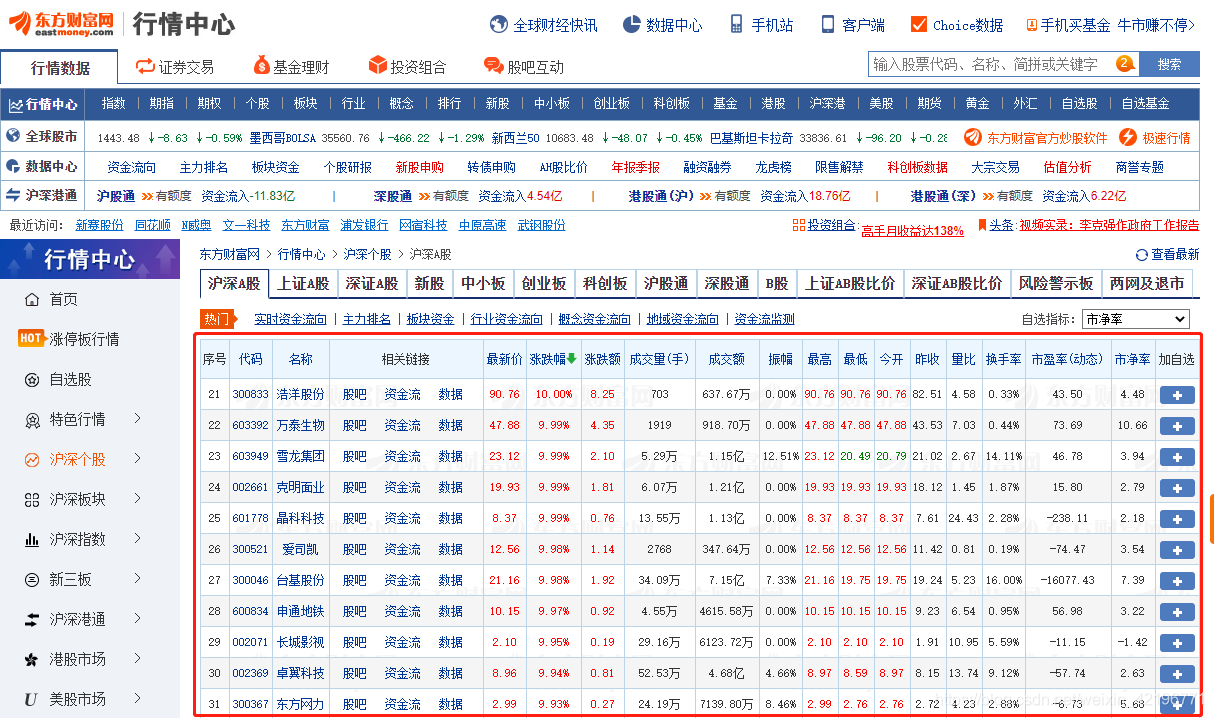
可以看到红色框框内有一堆股票数据,我们只需要找到这堆数据的返回接口即可(因为这个表格数据都是动态呈现的,如果使用beautifulsoup4直接做汤,表格内的数据都是-),所以我们得去找数据接口 - 按
F12打开浏览器开发工具,找到network或者网络
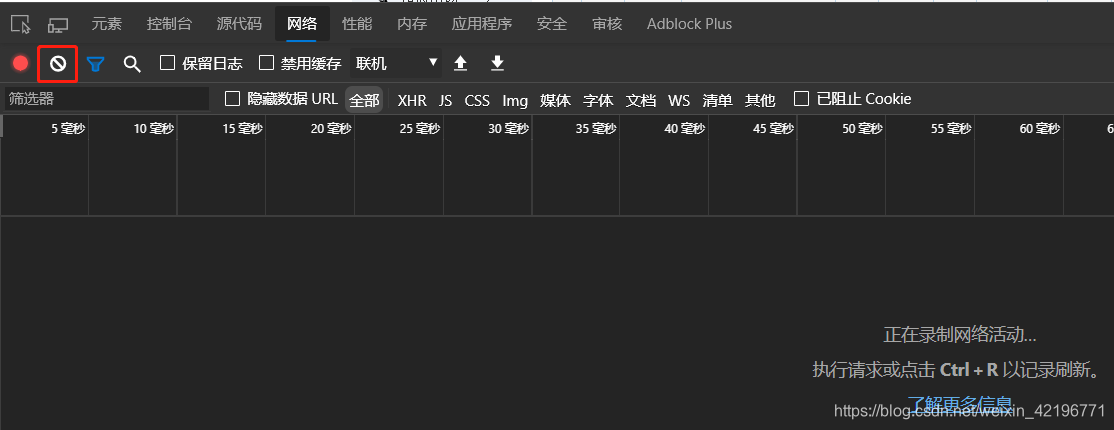
点击红色框框将当前网络请求记录清除,以便我们获取新的网络请求记录 - 点击网站表格下面的翻译,我们就会发现一条查询参数这么多的查询记录
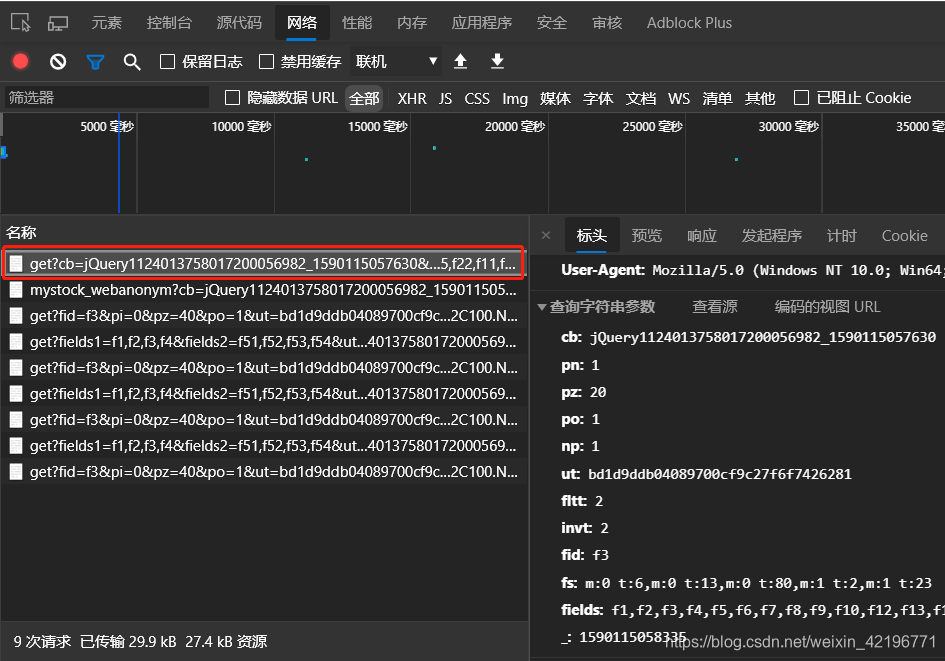
点击预览我们就能看到与展示股票信息表格的对应信息的数据

- 多翻几页表格,查看请求的参数变化,就能分析出请求参数有用的地方
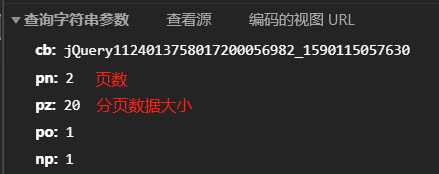
- 至此我们就可以根据标头查看我们所需的接口连接啦,每次打开这个连接可能前面的数字有所不同,但是都可有获取数据

- 将全部请求的参数以字典的形式保存,然后在
requests.get()的时候传递过去即可获得数据 - 使用
pandas可以很方便的以.csv的格式导出数据文件到本地
当然,你不想看上面的内容,或者觉得我说的不是很清楚,也可以直接看下面的实现代码
实现代码
首先引入相关的第三方库与定义全局变量
import requests
import re
import json
import pandas
STOCK_LIST_URL = 'http://79.push2.eastmoney.com/api/qt/clist/get'
HEADERS = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/81.0.4044.138 Safari/537.36 Edg/81.0.416.77',
'Cookie': '你自己的 Cookie 信息'
}
# 这个查询参数可以直接复制,
PARAMS = {
'cb': 'jQuery112406209406051182_1590109022697',
'pn': 1, # 页码
'pz': 200, # 每页的大小
'po': 1,
'np': 1,
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': 2,
'invt': 2,
'fid': 'f3',
'fs': 'm:0 t:6,m:0 t:13,m:0 t:80,m:1 t:2,m:1 t:23',
'fields': 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152',
'_': '1590109022826'
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 934
934

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









