







过拟合与欠拟合
过拟合:对已有数据拟合的非常好,但是对新数据拟合很差
欠拟合:对已有数据和新数据拟合都不好

1、创建0到1中20个随机点,带入y中的表达式
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
n_dots = 20
x = np.linspace(0, 1, n_dots) # [0, 1] 之间创建 20 个点
y = np.sqrt(x) + 0.2*np.random.rand(n_dots) - 0.1;
2、构建一个拟合函数
p = polyfit(x,y,n) 返回次数为 n 的多项式 p(x) 的系数,n为拟合效果最好的值
np.poly1d()返回多项式函数

等价代码:
plot(x, y, 'go--', linewidth=2, markersize=12) 等价与下面
plot(x, y, color='green', marker='o', linestyle='dashed',
linewidth=2, markersize=12)
线条颜色变换:
'ro' => color='red'
'-' => 实线
'r--' => red的虚线
拟合函数代码:
def plot_polynomial_fit(x, y, order):
p = np.poly1d(np.polyfit(x, y, order))
print(p) # 显示维度
# 画出拟合出来的多项式所表达的曲线以及原始的点
t = np.linspace(0, 1, 20)
plt.plot(x, y, 'ro', t, p(t), '-', t, np.sqrt(t), 'r--')
return p
3、调用函数画图:
enumerate:让index和order一一对应
subplot:分块建立画图区域
order:代表系数的最高次
titles:标题
plt.figure(figsize=(18, 4))
titles = ['Under Fitting', 'Fitting', 'Over Fitting']
models = [None, None, None]
# index=0,order=1;;index=1,order=3;;index=2,order=10
for index, order in enumerate([1, 3, 9]): # 一一对应
plt.subplot(1, 3, index + 1) # 分块建立坐标区
models[index] = plot_polynomial_fit(x, y, order) # order代表几位系数
plt.title(titles[index], fontsize=20)
4、最后图像为:

5、打印出模型的系数
for m in models:
print('model coeffs: {0}'.format(m.coeffs))

成本函数


模型准确性

对模型的准确性的判断:

一般使用交叉数据集,也就是将数据集分为6:2:2
理由:
如果是7:3或者8:2,一个数据用于训练,另一个数据开始的时候计算机“不认识”,但是如果开始训练集的不符合测试集的数据,导致过拟合,那我们必须修改函数,但是此时,训练集相当于被计算机“认识了”,而分成6:2:2的话,一个用于训练,一部分为交叉训练集,一个用于测试系数。
学习曲线
1、 多设置些点
n_dots = 200
X = np.linspace(0, 1, n_dots)
y = np.sqrt(X) + 0.2*np.random.rand(n_dots) - 0.1;
X = X.reshape(-1, 1)
y = y.reshape(-1, 1)
2、用pipeline构造多项式模型

from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
# 生成多项式模型
def polynomial_model(degree=1): # degree是阶乘的阶数
# PolynomialFeatures:生成一个新的特征矩阵
# 如果有a,b两个特征,那么它的2次多项式为(1,a,b,a^2,ab, b^2),这个多项式的形式是使用poly的效果。
# include_bias:默认为True。如果为True的话,那么就会有上面的 1那一项
polynomial_features = PolynomialFeatures(degree=degree,
include_bias=False)
# LinearRegression:普通最小二乘线性回归
# normalize=True是标准化
linear_regression = LinearRegression(normalize=True)
# 这个是一个流水线,先增加多项式的阶数,然后再用线性回归算法来拟合数据
pipeline = Pipeline([("polynomial_features", polynomial_features),
("linear_regression", linear_regression)])
return pipeline
from sklearn.model_selection import learning_curve
from sklearn.model_selection import ShuffleSplit
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.title(title)
# 会影响过拟合的那个数据
if ylim is not None:
plt.ylim(*ylim)
plt.xlabel("Training examples")
plt.ylabel("Score")
train_sizes, train_scores, test_scores = learning_curve(
estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.grid()
# 绘制区域图
# alpha透明度,区域就是[train_scores_mean - train_scores_std,train_scores_mean + train_scores_std]
plt.fill_between(train_sizes, train_scores_mean - train_scores_std,
train_scores_mean + train_scores_std, alpha=0.1,
color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std,
test_scores_mean + test_scores_std, alpha=0.1, color="g")
# 线条:
plt.plot(train_sizes, train_scores_mean, 'o--', color="r",
label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g",
label="Cross-validation score")
plt.legend(loc="best")
return plt
# 为了让学习曲线更平滑,交叉验证数据集的得分计算 10 次,每次都重新选中 20% 的数据计算一遍
cv = ShuffleSplit(n_splits=10, test_size=0.2, random_state=0)
titles = ['Learning Curves (Under Fitting)',
'Learning Curves',
'Learning Curves (Over Fitting)']
degrees = [1, 3, 10] # 阶乘
plt.figure(figsize=(18, 4)) # 图大小
for i in range(len(degrees)):
plt.subplot(1, 3, i + 1)
plot_learning_curve(polynomial_model(degrees[i]), titles[i], X, y, ylim=(0.75, 1.01), cv=cv)
plt.show()

当发生高分差的时候,加训练样本数不会对算法准确性有较大的改善
修改学习算法的时候,可以构建学习曲线来分析算法是否合适。
过拟合:
1、获取更多的训练数据
2、减少输入的特征数量:优化模型复杂度
欠拟合:
1、增加有价值的特征
2、增加多项式特征:原输入x1,x2,修改后输入x1,x1^2, x1^3,x2, x2^2, x1^3
查准率和召回率
有时候不太好评估一个算法的好坏,所以说引入了查准率和召回率
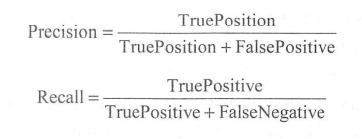
在sklearn中,评估模型性能的算法都在sklearn.metrics包中,其中计算查准率和召回率的API分别为sklearn.metrics.preeision_score()和sklearn.metrics.recall_score()
如果查准率为0.2,召回率为0.4
查准率为0.4,召回率为0.2,哪个算法更好呢??
F1 Score:
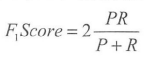
P是查准率,R为召回率
1、只要其中一个为0,就为0。
2、理想情况下P和R都是1,F1Score为1
3、在sklearn中计算函数为:sklearn.metrics.f1_score()
















 1338
1338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











