







这周主要是看了几篇情感对话相关的论文
首先会介绍三个数据集,然后还有涉及到共情、情感支持等方面的一些论文~
ATOMIC if-then推理的机器常识图集
- 包含877K个知识的文本描述,主要关注由if-then组成的推理知识。提出了九种if-then关系,以区分 原因/影响, 主体/主题,自愿/非自愿事件,行为/精神状态
- 之前的大部分AI都是针对特定任务进行训练的,所以模型能够有效地发现特定任务的相关性,但是缺乏简单和可解释的常识性推理
- 分类方法具体介绍(前三种是一种分类方式,合起来共9中if-then关系):
- If-Event-Then-Mental-State:三种与某个事件的心理前后条件有关的关系。某件事的意图、事件主体可能的情绪上的反应、事件客体(其他人)可能的情绪上的反应
- If-Event-Then-Event:五种涉及构成特定事件可能的前/后条件的事件。在某件事之前\之后可能发生的事件,以及一些隐含的自愿\非自愿的可能的下一个事件
- If-Event-Then-Persona:一个关系,描述某个事件的主题是如何被描述或者感知的,例如某人报警=》这个人可能被认为是“合法的”或者“负责任的”
- An Alternative Hierarchy(另一种层次结构):原因、影响、状态等,还有主题和主体
- 数据:
- 24K个常见事件短语(故事、书籍等),事件的定义为‘带有动词谓词及其参数的动词短语’,如早上喝酒,可以不带主语的!带主语的事件用personX,personY等来代替某个人,这就涉及到消歧的问题(personX、Y、Z之间的歧义),三个人工来保证这个问题
- 框架:自由注释(不规定特定的结构)要求工作人员自行编写关于特定事件的问题的答案,比如某个事件之前/之后会发生什么
- 24K个事件=》300K个节点(平均2.7个单token),stative事件一般都是1个token,别的基本都是平均3.3个token或者4.6个token
- 模型(目的是对于unseen的事件,能否完成推理=》条件序列生成问题)
C3KG 中文常识对话知识图谱
- 包含中文社会常识知识和对话流信息
- ATOMIC有缺点:1)ATOMIC对同一个事件可能有多个影响因素,不好判断当前unseen的事件背后的原因。2)ATOMIC里的知识元组是孤立的,所以机器人很难通过推理应该使用知识的哪一个尾部去产生一个一致的反应=》C3KG定义了四个新的对话流关系:事件流、概念流、情感原因流、情感意图流
C3KG是基于小米自己的多轮对话语料库CConv和ATOMIC-zh得到的
-
CConv由62名训练有素的工人众包产生,共15个主题,200个场景,32K个多轮双方对话,650K轮次。3名助手标注了细粒度情感标签,以及说话者的情绪类型、原因和反应意图。情感有五分类(快乐、愤怒、伤心、惊喜、其他),意图有六分类(询问、建议、描述、意见、安慰、其他)
-
ATOMIC以三元组的形式组织常识知识,<head, relation, tail>,其中头部经常用于描述一个日常事实。ATOMIC有两个独特的特性:
- ATOMIC收集了人对某件事实的反应,这与人的心理状态有关,有助于理解内心的情绪
- ATOMIC用到了推理关系,并且天然支持if-then的推理,这是产生连贯翻译的关键
以ATOMIC为基础,把它翻译成了中文(用定期更换和联合翻译),翻译完之后的语料库叫ATOMIC-zh
=》抽取多轮对话数据集里的事件,去和ATOMIC-zh的头实体匹配。
-
事件抽取:开发了一个基于依赖性解析的事件检测管道提取每个话语中的显著事件
- 预处理:用标点符号分割每句话,……, 基于动词驱动从句和形容词驱动从句从两种模式提取事件提及
- 动词驱动:动词连接到根节点,例如从“我和上司已经在催促提供物资的商家了”=》“催促提供物资的商家”,过滤了主语、状语和模态词(“了”)
- 形容词驱动:保留关键形容词,过滤掉其他词驱动的事件提及。例如从“但学习节奏也太快了吧”=》“学习节奏快”,过滤了初始的连词、状语和模态词
- 递归应用:可能抽取到的事件提及依旧包含很多个事件。因此设定了阈值用于确定是否需要进行二次分解
-
事件匹配链接
- 用Sentence-BERT得到两个句子的表示然后计算相似度
-
边的结构:提出了三种边反应不同类型的对话流
-
头-头边结构
- 事件流:如果在对话中同时检测到两个事件提及,可以看作对话流示例。连接话语内和话语间的提及,获得了next-sub-utterance(同一轮对话)和next-utterance(不同轮对话)
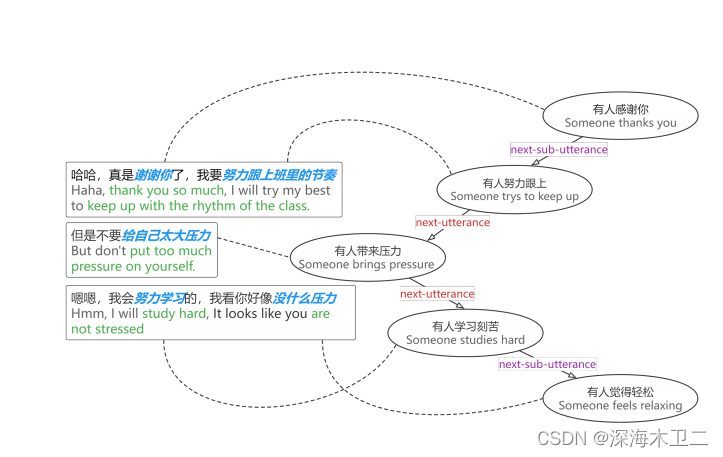
- 概念流:除了短语级的事件,ATOMIC还有实体级的事件。检测句子里的动词,形容词等,然后和ATOMIC里的实体匹配去构造概念流,有助于规划和转换主题
-
-
尾-尾结构:基于情感的情绪流
两种:情感原因流和情绪意图共情流。情绪-原因的对话流反映了特定情绪的原因,这对细粒度的情绪理解很有用。情绪意图共情流表明当另一个人处于特定情绪时,反应意图适合使用,这对反应共情至关重要。
-
预处理:尾实体共分为三类,Tail(emotion)反映了人们对某件事(head)的心理反应,Tail(before)说明事件发生在head之前,Tail(after)说明某件事发生在head之后。连接Tail(emotion)就是情感原因,如果把Tail(emotion)和Tail(after)连起来就可以得到隐含的连接,这也是一种推理。比如,某人运动-xAttr-累了;某人运动-xWant-补充能量=》某人累了需要补充能量
-
过滤:使用SentiLARE匹配Tail(emotion)类别的尾部为四个情感之一,对于SentiLARE里没有的情感,设一个阈值从“其他”类别里找出来
-
情感原因流:Tail(before)的头部如果能和Tail(emotion)头部匹配,说明Tail(emotion)尾部的情绪的原因就是Tail(before)的尾部,就能够构建一个情感原因流。
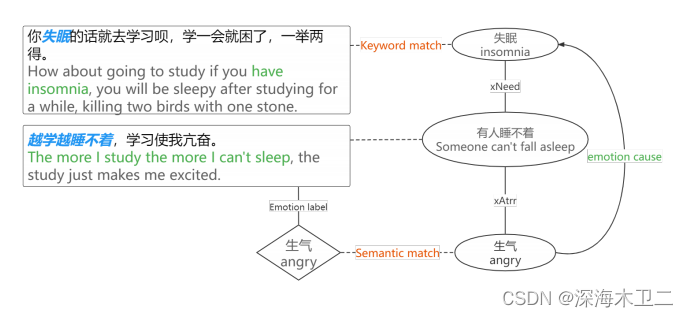
- 情感意图流:Tail(after)的头部如果能和Tail(emotion)的头部匹配,说明Tail(emotion)尾部的情绪的意图是Tail(after)的尾部的,就能够构建一个情感意图流。
-
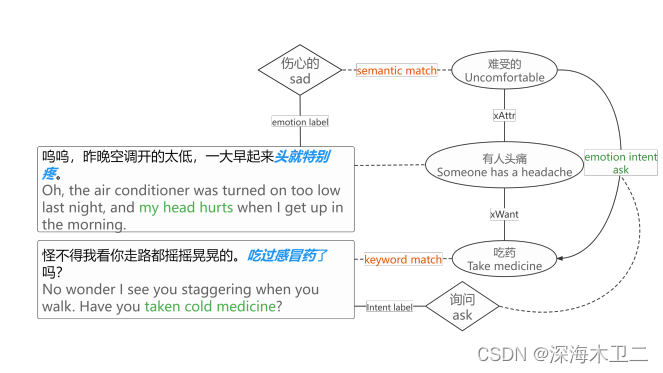
未来任务:
- 情感预测:用bert模型,加上情感原因流里的相关状态
- 意图识别:用bert模型,加上oReact, oEffect 关系的尾部一起
C3KG这个常识性知识图谱能够帮助研究者更方便的探索多轮对话中用户的情感和意图,可以辅助情感对话更好的理解用户,增加用户黏性吧主要是。
《Towards Emotional Support Dialog Systems》(ESConv)清华 2021ACL
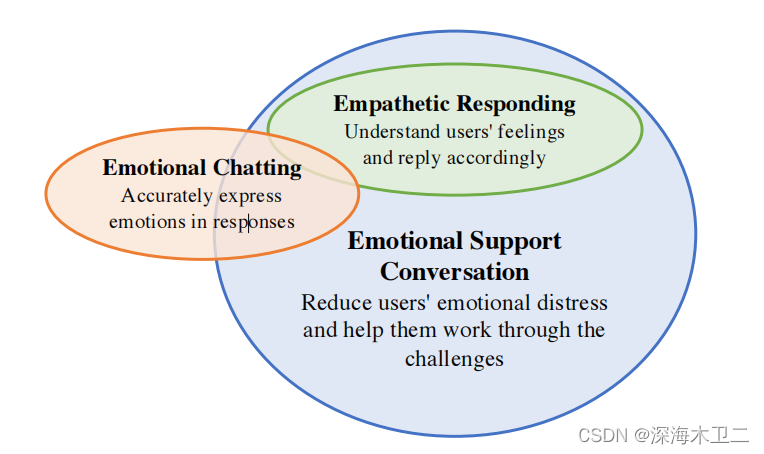
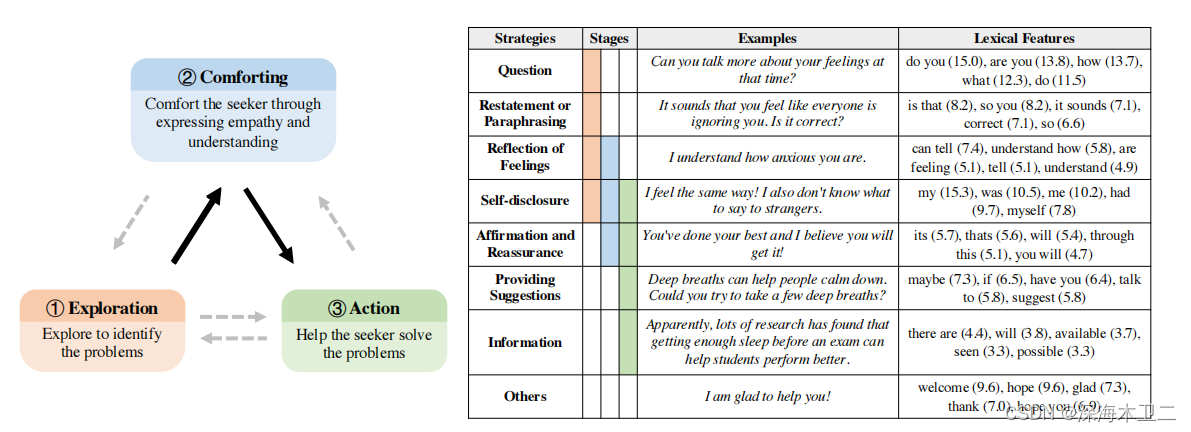
- 定义了情感支持对话(ESC)任务,并且提出了一个基于Helping Skills Theory的ESC框架,该框架主要包含三个阶段(Exploration, Comforting and Action)
-
任务范围划分:
- 情感支持对话(ESC)能够缓解用户的痛苦,并且帮助他们解决问题
- 共情反应:理解用户的感受并且能够给出合适的回应
- 情感聊天:在回复中准确的表达情绪
-
ESC任务定义:当用户处于糟糕的情绪状态时,会寻求帮助以改善他们的情绪状态。用户会被标记一个负面情绪标签e,并且会打上情绪强度l(1-5),并且有用户正在经历的潜在挑战,支持者需要在对话中使用技巧安慰用户,降低他们的负面情绪强度。支持者需要在对话过程中识别出用户所面临的问题,然后安慰用户并给出建议帮助用户解决问题。
ESC任务有几个子问题:
- 支持策略选择和受策略约束的相应生成:应用策略的时机与ES的有效性有关,因此要生成符合指定策略的响应
- 情绪状态建模:无论用于动态策略选择还是衡量ESC的有效性,动态的建模和追踪用户的情绪状态是很重要的
- 评估支持的有效性:除了评估对话的相关性、一致性和用户参与度等传统方面外,还有个新维度
-
ESC框架:主要包含三个步骤:探索(识别用户问题)-安慰(同情心和理解)-动作(给出建议),虽然步骤有顺序,但是还是要灵活,所以也不用严格按照顺序。同时,还为每个阶段提供了几种推荐的对话技能(8种,问题、陈述或转述、感情的反应、自我表露、肯定和保证、提供建议、信息、其他,而且不同的策略有常用的一些词汇,也就是词汇特征)
- 问题:询问求助者,问清楚面临的问题,开放性问题最好,封闭域问题也可以
- 陈述或转述:对寻求帮助者的简单、更简洁的重述,可以帮助他们更清楚地看到自己的情况。
- 感情的反应:清晰地表达和描述求助者的感受。
- 自我表露:用你相似的经历或你与寻求帮助者分享的情感来表达你的同理心。
- 肯定和保证:确认求助者的优势、动力和能力,并提供安慰和鼓励
- 提供建议:提供关于如何改变的建议,但要小心不要越界,告诉他们该怎么做。
- 信息:为求助者提供有用的信息,例如提供数据、事实、意见、资源,或通过回答问题。
- 其他
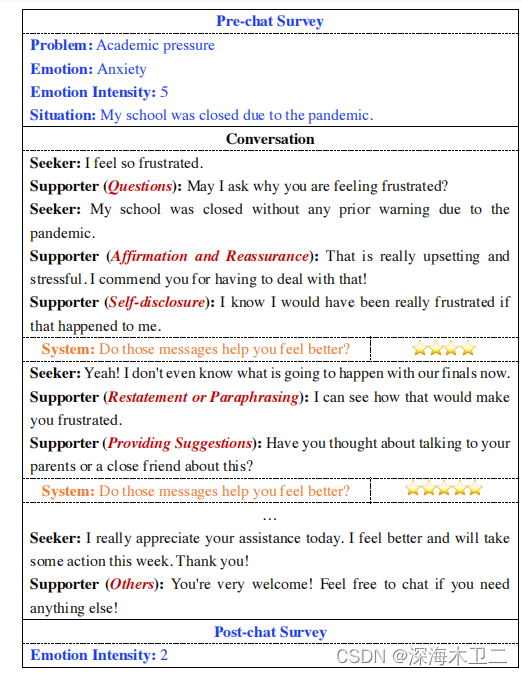
ESConv数据集构建
共1053个对话,31410个轮次,通过众包的方式产生对话,标注人员经过培训和考试,并且有自动和手动的过滤机制过滤低质量对话。文章里对标注方法,人工、自动过滤方法写的很详细,感兴趣的可以自己看一下~
如图所示,对话前会有调查,标记了问题类别,情感类别,情绪强度和求助者的情况简介。对话过程中支持者用到的策略会被标记出来,并且求助者会对支持者每一轮次打分。最后会给出聊完之后的情绪强度(肯定是希望降低)
《Towards an Online Empathetic Chatbot with Emotion Causes》(EMMA)小米 2021SIGIR
-
有情感原因的在线共情聊天机器人
-
目前的情绪感知会话模型的侧重点主要在于控制反应内容,生成特定情感的回复(ECM?),但是对同理心的关注不够=》了解能够唤起用户共情反应情绪的原因很重要=》利用咨询策略,开发了一个利用情感原因的共情聊天机器人,不仅要了解情绪,还要了解情绪背后的原因。
-
数据有两部分,一部分是EmpatheticDialogues数据集的8000条数据,另一部分是小爱的真实对话数据共8000个。
-
X-EMAC:数据集,首先给用户的查询标记情感,然后编写模板询问情感产生的原因,得到了用户响应之后就得到了带有标注情感原因信息的对话数据集。
-
Emma,检测用户情绪类别,并识别情绪的原因,如果没有就引导用户进行表达。然后,根据历史对话、检测到的情绪类别和原因给出共情响应。
具体来说,如图所示,对于输入的对话,首先对对话进行情感识别和原因识别(联合训练)(那不就是情感原因对任务吗,同时抽取对话中的情感和原因),然后用GPT做生成,说话者的信息也被放到query里了,包括上下文的信息(如果有的话),形如: [CLS][speaker1] q1 [speaker2] r1 [speaker1] q2 [sep] label [SEP] hasCause [SEP] Cause [SEP]。
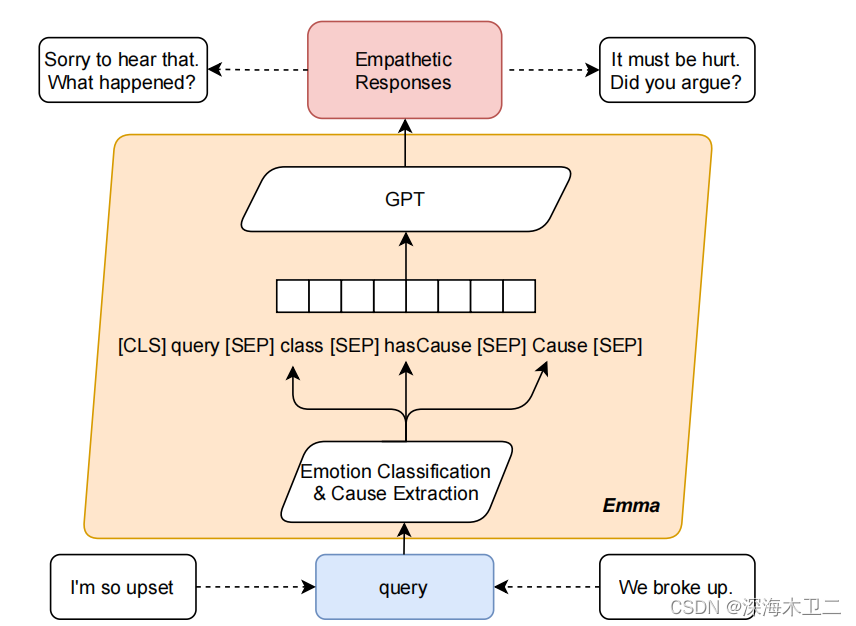
总结一下就是:用了小爱的真实对话语料和别的一个数据集,一共约16000条数据,得到了一个包含情感原因标注(人工)的多轮对话数据集。设计了上图的模型,先是联合任务学习情感识别和原因识别,然后用GPT,以上文、query、情感、原因当作输入,得到共情的输出。
《MISC: A MIxed Strategy-Aware Model Integrating COMET for Emotional Support Conversation 》(MISC) 小米 2022ACL
-
现有的情感支持对话的问题:
- 通常使用对话级别的情绪标签,太粗粒度,无法捕捉用户的即时心理状态
- 更想要表达同理心,而不是减轻用户的痛苦
=>MISC:首先推断用户的细粒度情绪状态,然后用混合策略产生响应,基于COMET(一个适应性框架,可以用来补充知识图谱,输入是主语和关系,输出是宾语,如:(s=“打盹”, r=“导致”, o=“有精力”),COMET的任务是根据s和r的输入生成o)。这里主要是利用COMET(在ATOMIC上预训练)去对对话中的event进行推理吧
-
数据集:ESConv,这是个情感支持数据集,有八种策略
-
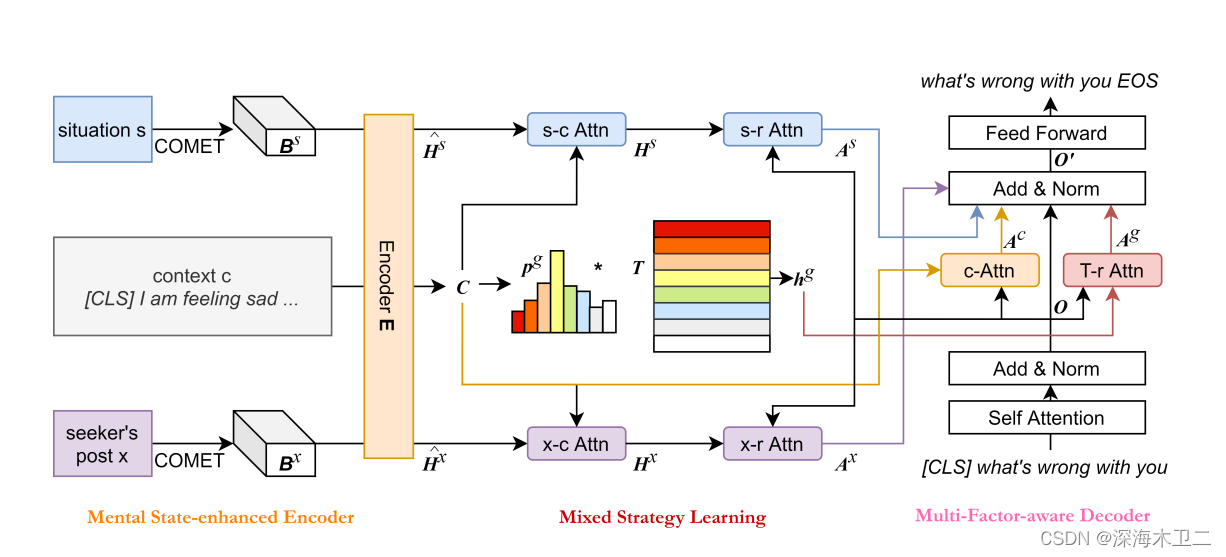
模型主要包含三部分:精神状态增强编码器、混合策略学习模块、多因素感知解码器
-
精神状态增强编码器:
- 开头加cls,中间用eos,得到上下文的编码C
- 将ESConv数据集里标注的场景s当作一个event,输入COMET,得到该事件-某个关系-输出B(s),B(s)是s的某个心理状态(因为输入的关系选择的是心理状态相关的)
- 用户当前轮的对话x,经过COMET也可以得到一个B(x)
然后,经过编码器之后变成了C,H’(s), H’(x),分别用H’(s), H’(x)当query,C当key和value,搞个注意力,这就增强了常识性知识。
-
混合策略学习模块:利用C里cls处的编码训练一个分类器当策略,然后学VQ-VAE的方法,用d维表示了8种策略(主要是对C的处理)
-
多因素感知解码器:decoder的输入经过self-attention和add&norm之后得到了向量O,疯狂cross-attention(O分别和H,H(s),H(x),H(g)做cross-attention),然后相加经过一个LN得到O’,然后得到响应
-
总结一下就是:
- 输入有上下文、情景(其实可以看作一个事件)和当前post,情景和当前对话分别经过COMIC模型(输入event和关系,得到情绪相关的表达)得到一个结果,然后三个一起给编码器;
- 对于情景和post的输出,用上下文编码C做个注意力,C取第一维做个策略选择;
- 对标准回复,经过self-attention和add&norm之后,得到的向量分别和三个输出以及H做cross-attention,然后相加得到O’,再去生成响应。
主要就是结合了细粒度的状态(体现在两个event经过COMIC上)和混合策略(体现在对C做策略分类上),最后生成的响应更连贯,也能根据不同的策略生成更符合用户需求的响应。
总结
- ATOMIC主要是包含很多常识性信息,并且用九种关系连接了各个实体,这九种关系有一些是事件,有一些是表达对某件事的心理状态,但是元组之间是孤立的,并且同一个事件可能会连接意思相反的尾实体
- C3KG基于小米自己的对话语料库和ATMOIC-zh,对话中标注了情感,所以将对话中的事件与ATOMIC里的实体匹配,再通过特定的关系类别连接到别的实体,再搭配上情感,就能够做情感预测和情感意图识别任务(根据某个事件,做两跳甚至多跳的预测任务),对情感对话很有帮助
- ESConv是一个情感支持数据集,数据集内每一个对话都有求助者的情绪标签、强度、描述等,对话主要分为三个阶段,询问-安慰-建议,基本上支持者给几轮反馈之后求助者会打个分,最后会给一个求助者目前的情绪强度。
- EMMA属于情感共情模型,有两个辅助任务:情感抽取和原因抽取,然后希望能够生成共情的对话缓解用户的痛苦
- MISC是个情感支持模型,能够推断细粒度的情绪状态,并且用混合策略产生响应。策略主要是8种(就是ESConv数据集里的那八种,包含三个阶段)。这种响应方式或者说这种任务,不仅能够通过共情缓解用户的痛苦,还能提出一些建议尝试帮助用户解决问题,理论上来说是比较全面的一种方法。

















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









