







机器学习——特征工程之数据相关性
前言
在样本属性很多的数据集中,一定会存在一些与标签关系不那么强的属性,将这些属性drop掉,可以提高模型的准确性。如何评价两样本之间的相关性?个人总结了四种方法:画图、协方差、相关系数、信息熵(重点说明相关系数中的皮尔逊相关系数)。
图表相关性
图是最直观的数据表达方式,但也是最不精确的一种方法,因为基于图只能看到大概趋势,并没有像相关系数这样精准的值。
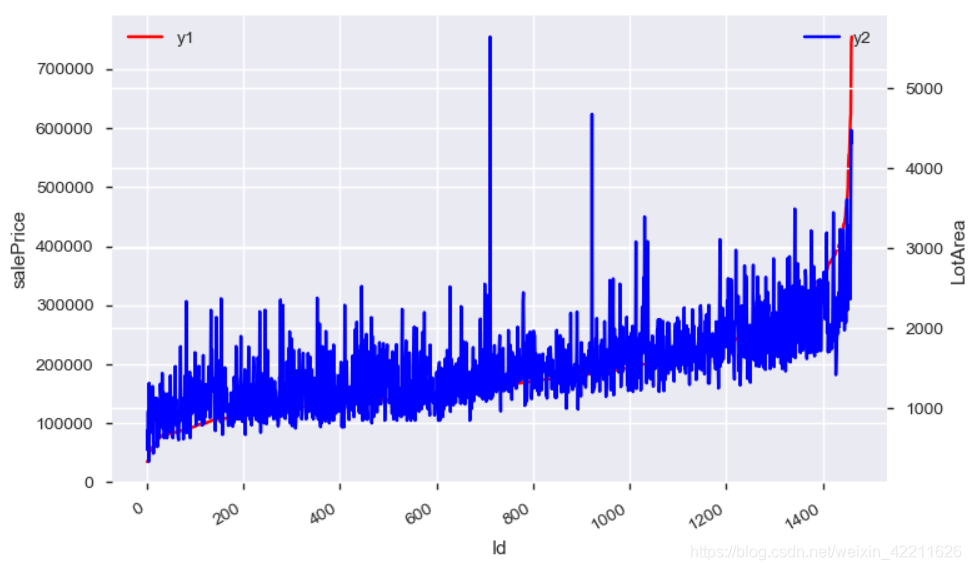
上图就说明了这两个样本具有一定的相关性。
(数据有噪声点,不过不影响原理)
而下面的图说明这两个数据的相关性不是那么强:
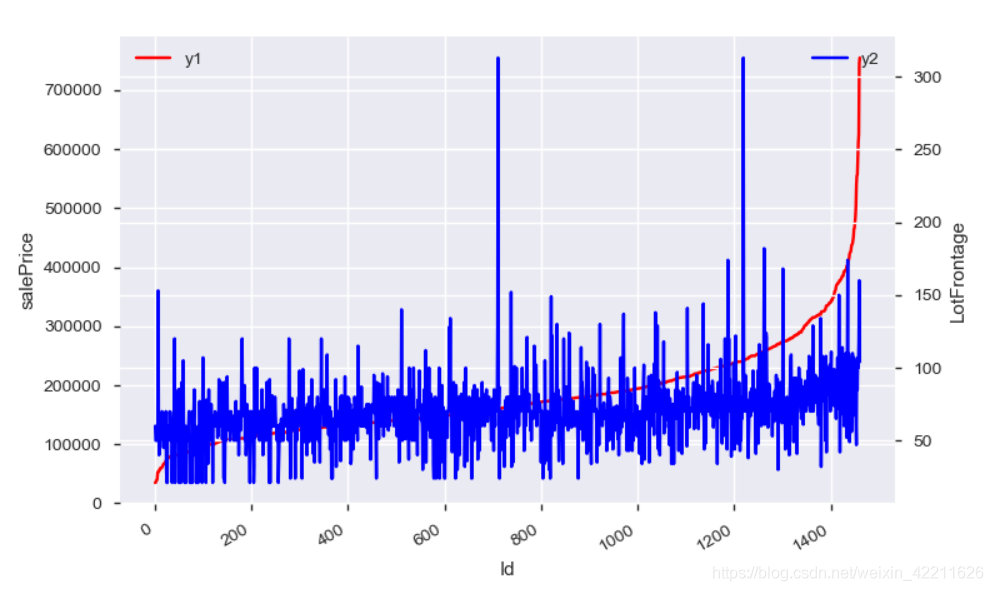 当然也可以使用直方图等其他表现形式。
当然也可以使用直方图等其他表现形式。
协方差和协方差矩阵
公式:
 协方差用来衡量两个变量的总体误差:
协方差用来衡量两个变量的总体误差:
- 如果协方差为正,则说明两个变量的变化趋势一致,两个变量正相关;
- 如果协方差为负,则说明两个变量的变化趋势相反,两个变量负相关;
- 如果协方差等于0,则说明两个变量相互独立,两个变量不相关。
协方差只能对两组数据进行相关性分析,当有两组以上数据时,就需要使用协方差矩阵。下面是三组数据x,y,z的协方差矩阵计算公式:
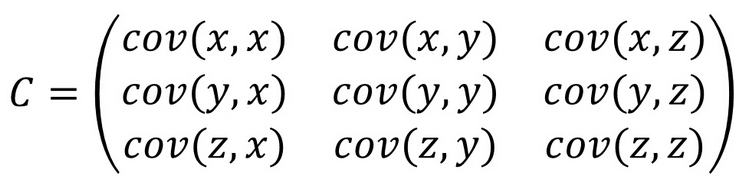 n组数据,其协方差矩阵大小为n*n。
n组数据,其协方差矩阵大小为n*n。
代码实现
#未进行使用说明
import numpy as np
np.cov(x) #这里面的x可以是多组样本数据
相关系数
协方差只能说明数据间是否有相关以及是哪种相关方式(正相关,负相关),而无法说明其密切程度,所以当样本数据很多时,无法说明哪些样本相关性最高,而相关系数可以解决这一问题。
1、皮尔逊相关系数( Pearson correlation coefficient)
定义:
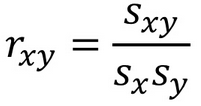
其中rxy表示样本相关系数,由于是样本协方差和样本标准差,因此分母使用的是n-1
Sxy表示样本协方差:
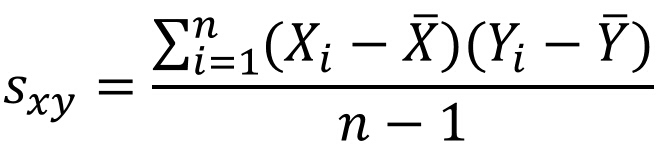
Sx表示X的样本标准差:
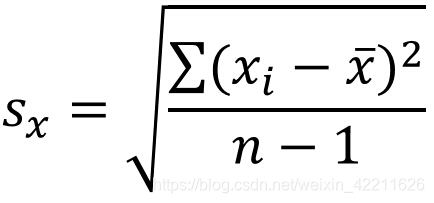
Sy表示y的样本标准差,:
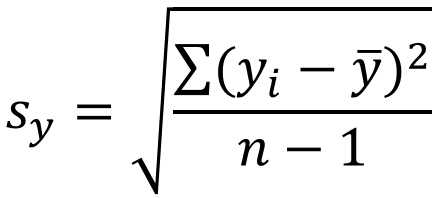
关于rxy的使用:
- rxy的值域在-1和1之间;
- |rxy|越接近于1,说明数据相关性越强;
- 与协方差相同,若rxy>0,则是正相关;rxy<0,则负相关。
代码实现:
#未进行使用说明
############第一种方法###########
import pandas as pd
x = pd.DataFrame(a)
x.corr() #默认值时计算的时皮尔逊相关系数
############第二种方法###########
import numpy as np
co = np.corrcoef(x, y)
############第三种方法###########
from scipy.stats import pearsonr
pccs = pearsonr(x, y)
from scipy.stats import pearsonr
import numpy as np
import pandas as pd
co_use_pandas = pd.DataFrame(pd.concat([LotArea,salePrice],axis =1,ignore_index = True)).corr()
co_use_numpy = np.corrcoef(LotArea,salePrice)
co_use_scipy = pearsonr(LotArea,salePrice)
print("pandas库中的皮尔逊系数:",co_use_pandas)
print("numpy库中的皮尔逊系数:",co_use_numpy)
print("sccipy库中的皮尔逊系数:",co_use_scipy)
打印结果如下:
pandas库中的皮尔逊系数:
0 1
0 1.000000 0.263843
1 0.263843 1.000000
numpy库中的皮尔逊系数:
[[1. 0.26384335]
[0.26384335 1. ]]
sccipy库中的皮尔逊系数:
(0.2638433538714056, 1.1231391549187896e-24)
2、斯皮尔曼相关性系数、秩相关系数(spearman correlation coefficient)
适用范围较Pearson相关系数广,经常被称为非参数相关系数,不是衡量线性相关的,而是衡量秩序的相关性的。
设有两组序列X和Y
其秩序为R(X)和R(Y),(这里R(Xi)=k代表Xi是序列X中的第k大(或第k小))
则SROCC(X, Y) = PLCC(R(X), R(Y)),其中PLCC是Pearson线性相关系数。
SROCC被认为是最好的非线性相关指标,这是因为,SROCC只与序列中元素的排序有关。
因此即使X或Y被任何单调非线性变换作用(如对数变换、指数变换),都不会对SROCC造成任何影响,因为不会影响元素的排序。
也可以称秩相关系数为单调性相关,也就是只要在X和Y具有单调的函数关系的关系,那么X和Y就是完全Spearman相关的,这与Pearson相关性不同,后者只有在变量之间具有线性关系时才是完全相关的,其次,斯皮尔曼不需要先验知识(也就是说,知道其参数)便可以准确获取XandY的采样概率分布。
上面的看不懂耶无所谓,只需要知道该系数的使用场景比皮尔逊广,其值规律也与皮尔逊系数相同。
代码实现:
x = pd.DataFrame(a)
x.corr("spearman")
3、Kendall Rank(肯德尔等级)相关系数
此处不谈详细数学公式,只给出使用例子和实现代码:
举个例子:比如评委对选手的评分(优、中、差等),我们想看两个(或者多个)评委对几位选手的评价标准是否一致;或者医院的尿糖化验报告,想检验各个医院对尿糖的化验结果是否一致,这时候就可以使用肯德尔相关性系数进行衡量。
代码实现:
x = pd.DataFrame(a)
x.corr("kendall")
信息熵和互信息
上面介绍的方法都针对数值型数据,对文本数据需要使用信息熵和互信息。
定义:度量文本特征值之间的相关关系的方法就是互信息。
(理论详情:https://blog.csdn.net/BigData_Mining/article/details/81279612)
或者说当值不连续时候,此时无论是一元统计回归还是相关系数都有些不合适,此时利用互信息,通过这种方法我们可以发现哪一类特征与最终的结果关系密切。
代码示例:
#计算互信息
from sklearn import metrics as mr
mr.mutual_info_score(data['Class'],data['V1'])#计算‘Class’和V1之间的一个互信息,如果互信息越高,说明V1对最终分类的状态影响越大















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









