






一、EDA介绍
探索性数据分析 (Exploratory Data Analysis,简称EDA) 是通过分析数据集以决定选择哪种方法适合统计推断的过程,也称为描述统计分析。 比如,对于一维数据,人们想知道数据是否近似地服从正态分布,是否呈现拖尾或截尾分布? 它的分布是对称的,还是呈偏态的?分布是单峰、双峰,还是多峰的? 这时就需要我们对数据进行探索性分析。
二、实例流程图
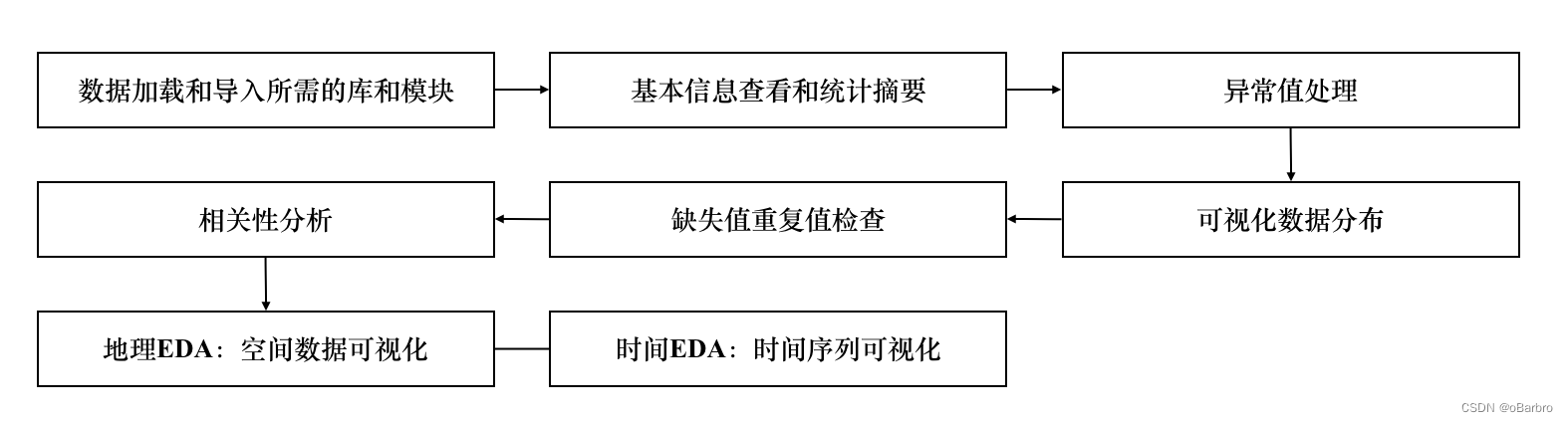 三、代码分析 (From kaggle; inversion (Owner) & Zaraki Kenpachi (Editor))
三、代码分析 (From kaggle; inversion (Owner) & Zaraki Kenpachi (Editor))
1.安装和导入库
%%capture
# 安装相关库
!pip install geopandas folium
# Import libraries
import pandas as pd
import numpy as np
import random
import os
from tqdm.notebook import tqdm
import geopandas as gpd
from shapely.geometry import Point
import folium
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
pd.options.display.float_format = '{:.5f}'.format
pd.options.display.max_rows = None
%matplotlib inline
import warnings
warnings.filterwarnings('ignore')
# You can ignore the Shapely GEOS warning :-)
# Set seed for reproducibility
SEED = 2023
random.seed(SEED)
np.random.seed(SEED)%%capture是一个单元格魔法命令,用于捕获安装命令的输出,防止在笔记本中显示。!pip install geopandas folium命令用于安装geopandas和folium库。这两个库通常用于处理地理空间数据和创建交互地图。- 该代码导入了一些在数据分析、机器学习和地理空间分析中常用的Python库。以下是被导入库的简要解释:
pandas: 数据操作和分析。numpy: Python中的数值操作。random: 生成随机数。os: 与操作系统交互。tqdm: 在迭代过程中显示进度条。geopandas: 处理地理空间数据。shapely.geometry: 使用Shapely库进行几何运算。folium: 创建交互地图。matplotlib.pyplot: 绘图和可视化。seaborn: 统计数据可视化。sklearn.ensemble: 用于机器学习的随机森林回归器。sklearn.model_selection: 用于模型选择的工具。sklearn.metrics: 机器学习模型的评估指标。warnings: 处理Python中的警告。
- 代码的最后一部分设置了一个种子,以实现在生成随机数时的可重复性,再次运行代码,将得到相同的随机结果。
2.加载数据
DATA_PATH = '/kaggle/input/playground-series-s3e20'
# 加载文件
train = pd.read_csv(os.path.join(DATA_PATH, 'train.csv'))
test = pd.read_csv(os.path.join(DATA_PATH, 'test.csv'))
samplesubmission = pd.read_csv(os.path.join(DATA_PATH, 'sample_submission.csv'))
# 预览训练数据集、预览测试数据集、预览样本提交文件
train.head()
test.head()
samplesubmission.head()
# 检查数据集的大小和形状
train.shape, test.shape, samplesubmission.shape
# 计算训练集与测试集的比例
(test.shape[0]) / (train.shape[0] + test.shape[0])pd.read_csv(os.path.join(DATA_PATH, 'sample_submission.csv'))用于从CSV文件加载样本提交文件。
3.统计摘要
# 训练数据集的统计摘要
train.describe(include='all')
# 目标变量分布
sns.set_style('darkgrid')
plt.figure(figsize=(13, 7))
sns.histplot(train.emission, kde=True, bins=15)
plt.title('Target variable distribution', y=1.02, fontsize=15)
# 显示图形和目标变量的偏度
display(plt.show(), train.emission.skew())train.describe(include='all')生成了训练数据集的统计摘要,包括计数、均值、标准差、最小值、25%,50%,75% 分位数以及最大值等信息。sns.set_style('darkgrid')设置了 seaborn 库的图形样式。plt.figure(figsize=(13, 7))创建了一个图形对象,指定了图形的大小。sns.histplot(train.emission, kde=True, bins=15)绘制了目标变量emission的直方图,并显示了核密度估计。plt.title('目标变量分布Target variable distribution', y=1.02, fontsize=15)设置了图形的标题。display(plt.show(), train.emission.skew())显示了绘制的图形,并输出目标变量emission的偏度(skewness)。这里使用了display()函数,同时显示图形和输出的偏度值。
4.异常值
# 绘制 CO2 排放的箱线图
sns.set_style('darkgrid')
plt.figure(figsize=(13, 7))
sns.boxplot(train.emission)
plt.title('Boxplot showing CO2 emission outliers', y=1.02, fontsize=15)
plt.show()sns.set_style('darkgrid')设置了 seaborn 库的图形样式。plt.figure(figsize=(13, 7))创建了一个图形对象,指定了图形的大小。sns.boxplot(train.emission)绘制了 CO2 排放的箱线图。箱线图可以用于可视化数据的分布和检测异常值。plt.title('****Boxplot showing CO2 emission outliers', y=1.02, fontsize=15)设置了图形的标题。plt.show()显示了绘制的箱线图。
通过观察箱线图,可以识别 CO2 排放中的异常值。箱线图展示了数据的中位数、四分位数、离群点等信息,有助于判断数据的分布情况和异常值的存在。
5.地理可视化-EDA
# 合并训练和测试数据以便于可视化
train_coords = train.drop_duplicates(subset=['latitude', 'longitude'])
test_coords = test.drop_duplicates(subset=['latitude', 'longitude'])
train_coords['set_type'], test_coords['set_type'] = 'train', 'test'
all_data = pd.concat([train_coords, test_coords], ignore_index=True)
# 创建点几何体
geometry = gpd.points_from_xy(all_data.longitude, all_data.latitude)
geo_df = gpd.GeoDataFrame(
all_data[["latitude", "longitude", "set_type"]],
geometry=geometry
)
# 预览 geopandas 数据框
geo_df.head()
# 创建地图画布
all_data_map = folium.Map(prefer_canvas=True)
# 从 GeoDataFrame 创建几何列表
geo_df_list = [[point.xy[1][0], point.xy[0][0]] for point in geo_df.geometry]
# 遍历列表,并根据类型设置颜色添加每个点的标记
i = 0
for coordinates in geo_df_list:
# 为类型设置颜色标记
if geo_df.set_type[i] == "train":
type_color = "green"
elif geo_df.set_type[i] == "test":
type_color = "orange"
# 放置标记
all_data_map.add_child(
folium.CircleMarker(
location=coordinates,
radius=1,
weight=4,
zoom=10,
popup="Set: " + str(geo_df.set_type[i]) + "<br>"
"Coordinates: " + str([round(x, 2) for x in geo_df_list[i]]),
color=type_color),
)
i = i + 1
# 调整地图边界
all_data_map.fit_bounds(all_data_map.get_bounds())
all_data_map- 首先合并训练数据和测试数据,创建了一个包含独特经纬度坐标的数据框。
gpd.points_from_xy(all_data.longitude, all_data.latitude)创建了点几何体,将经纬度坐标转换为地理空间点。folium.Map(prefer_canvas=True)创建了一个 Folium 地图对象,用于后续的可视化。- 通过迭代
geo_df_list列表,为每个数据点添加了一个颜色标记,并将它们放置在地图上。 all_data_map.fit_bounds(all_data_map.get_bounds())调整了地图边界,确保所有点都在可视区域内。all_data_map显示了最终的地图。这个地图包含了训练集和测试集的地理坐标点,用不同颜色标记它们的来源。这种可视化有助于理解数据的地理分布。
6.缺失值和重复值
# 检查缺失值
train.isnull().sum().any(), test.isnull().sum().any()
# 在训练集中绘制缺失值
ax = train.isna().sum().sort_values(ascending=False)[:15][::-1].plot(kind='barh', figsize=(9, 10))
plt.title('Percentage of Missing Values Per Column in Train Set', fontdict={'size': 15})
for p in ax.patches:
percentage = '{:,.0f}%'.format((p.get_width()/train.shape[0])*100)
width, height = p.get_width(), p.get_height()
x = p.get_x()+width+0.02
y = p.get_y()+height/2
ax.annotate(percentage, (x, y))
# 检查重复值
train.duplicated().any(), test.duplicated().any()train.isnull().sum().any(), test.isnull().sum().any()检查训练集和测试集是否存在缺失值。如果有任何缺失值,返回True。ax = train.isna().sum().sort_values(ascending=False)[:15][::-1].plot(kind='barh', figsize=(9, 10))创建一个条形图,显示训练集中前15个缺失值最多的列的百分比。[::-1]是为了反转条形图的顺序,使最大的缺失值在图的底部。plt.title('Percentage of Missing Values Per Column in Train Set', fontdict={'size': 15})设置图形标题。- 针对每个条形,使用
ax.annotate添加百分比标签。 train.duplicated().any(), test.duplicated().any()检查训练集和测试集是否存在重复值。如果有任何重复值,返回True。
7.日期功能EDA
# 年份计数图
plt.figure(figsize=(14, 7))
sns.countplot(x='year', data=train)
plt.title('Year count plot - Train')
plt.show()
# 年份计数图
plt.figure(figsize=(4, 7))
sns.countplot(x='year', data=test)
plt.title('Year count plot - Test')
plt.show()
# 周计数图
plt.figure(figsize=(14, 7))
sns.countplot(x='week_no', data=train)
plt.title('Week count plot - Train')
plt.show()
# 计算每年周数的统计摘要
train.drop_duplicates(subset=['year', 'week_no']).groupby(['year'])[['week_no']].count()sns.countplot(x='year', data=train)绘制了训练集中年份的计数图,显示每年的样本数量。sns.countplot(x='year', data=test)绘制了测试集中年份的计数图。sns.countplot(x='week_no', data=train)绘制了训练集中周数的计数图,显示每周的样本数量。train.drop_duplicates(subset=['year', 'week_no']).groupby(['year'])[['week_no']].count()计算了训练集中每年的周数,并显示了统计摘要。
这些图形和计数有助于了解数据中日期特征的分布情况,例如每年有多少样本,每周有多少样本等。这对于理解数据的时间结构和进行时间相关的分析是很有帮助的。
8.相关性——EDA
# 目标变量与前20个相关特征
top20_corrs = abs(train.corr()['emission']).sort_values(ascending=False).head(20)
top20_corrs
# 计算特征之间的相关性
corr = train[list(top20_corrs.index)].corr()
# 绘制热力图
plt.figure(figsize=(13, 8))
sns.heatmap(corr, cmap='RdYlGn', annot=True, center=0)
plt.title('Correlogram', fontsize=15, color='darkgreen')
plt.show()abs(train.corr()['emission']).sort_values(ascending=False).head(20)计算了目标变量emission与其他特征的绝对相关性,并选择了前20个相关性最高的特征。train[list(top20_corrs.index)].corr()计算了这些选定特征之间的相关性。sns.heatmap(corr, cmap='RdYlGn', annot=True, center=0)绘制了一个热力图,显示了这些特征之间的相关性。颜色越深,相关性越高。annot=True在热力图上显示相关系数的数值。plt.title('****Correlogram', fontsize=15, color='darkgreen')设置图形的标题。
这些操作有助于识别与目标变量最相关的特征,以及特征之间的相关性。热力图提供了一种直观的方式来可视化特征之间的关系。
9.时间序列可视化-EDA
# 选择一个唯一的地点并可视化其排放情况
train.latitude, train.longitude = round(train.latitude, 2), round(train.longitude, 2)
sample_loc = train[(train.latitude == -0.51) & (train.longitude == 29.29)]
# 绘制折线图
sns.set_style('darkgrid')
fig, axes = plt.subplots(nrows=3, ncols=1, figsize=(13, 10))
fig.suptitle('CO2 emissions for location lat -23.75 lon 28.75', y=1.02, fontsize=15)
for ax, data, year, color in zip(axes.flatten(), sample_loc, sample_loc.year.unique(), ['#882255', '#332288', '#999933', 'orangered']):
df = sample_loc[sample_loc.year == year]
sns.lineplot(x=df.week_no, y=df.emission, ax=ax, label=year, color=color)
plt.legend()
plt.tight_layout()round(train.latitude, 2), round(train.longitude, 2)将训练集中的经纬度坐标四舍五入,以确保匹配相同地点。train[(train.latitude == -0.51) & (train.longitude == 29.29)]选择了一个特定地点的数据,即纬度为 -0.51、经度为 29.29 的数据。fig, axes = plt.subplots(nrows=3, ncols=1, figsize=(13, 10))创建了包含三个子图的图形对象。fig.suptitle('****CO2 emissions for location lat -23.75 lon 28.75', y=1.02, fontsize=15)设置了图形的总标题。for ax, data, year, color in zip(axes.flatten(), sample_loc, sample_loc.year.unique(), ['#882255', '#332288', '#999933', 'orangered']):遍历每个子图,绘制每年的 CO2 排放折线图。sns.lineplot(x=df.week_no, y=df.emission, ax=ax, label=year, color=color)绘制了每年的 CO2 排放折线图。plt.legend()添加了图例,显示了每年的折线颜色对应的年份。plt.tight_layout()调整了布局,确保子图之间的间距合适。
这个时间序列可视化可以帮助您理解特定地点的 CO2 排放随时间的变化情况。















 2670
2670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









