







作者 | 梁云1991
来源 | (ID:)
Pandas库的名字来源于其中3种主要数据结构开头字母的缩写:
Panel,Dataframe,Series。其中Series表示一维数据,Dataframe表示二维数据,Panel表示三维数据。但实际上,当数据高于二维时,我们一般用包含多层级索引的Dataframe进行表示,而不是使用Panel。原因是使用多层级索引展示数据更加直观,操作数据更加灵活,并且可以表示3维,4维乃至任意维度的数据。
一、多层级索引的创建
1. 指定多维列表作为columns

2.使用pd.MultiIndex中的方法显式生成多层级索引
可以使用pd.MultiIndex中的from_tuples等方法生成多层级索引。

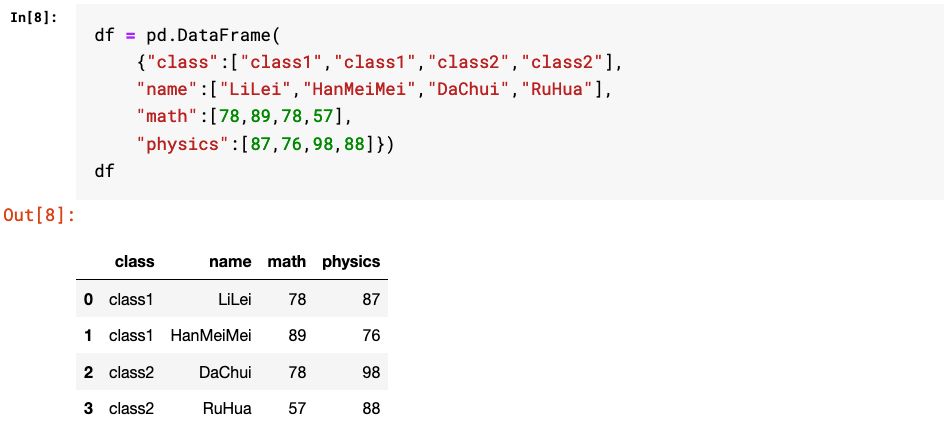
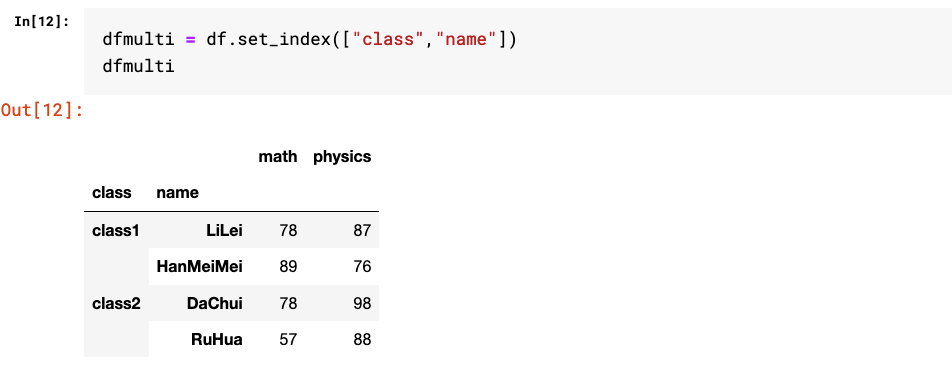
3.使用set_index方法将普通列转成多层级索引
这种方法只能生成多层级行索引。
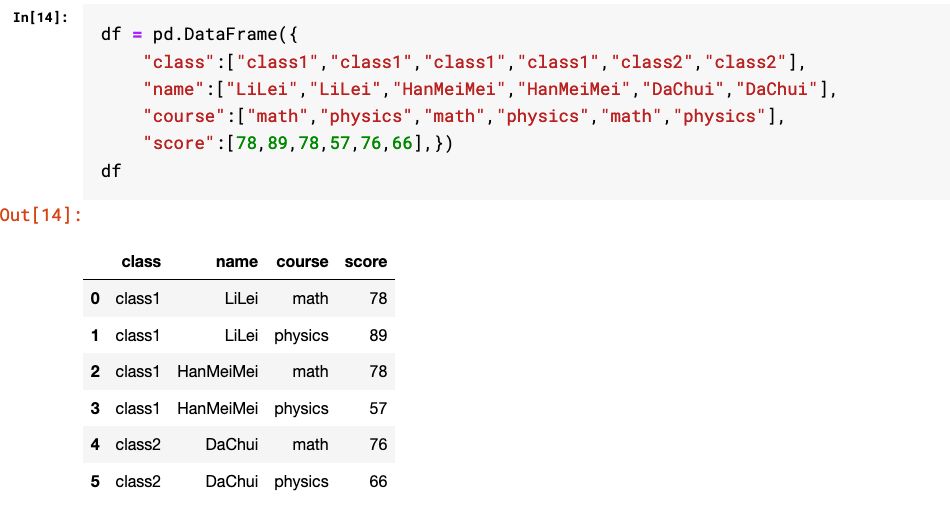
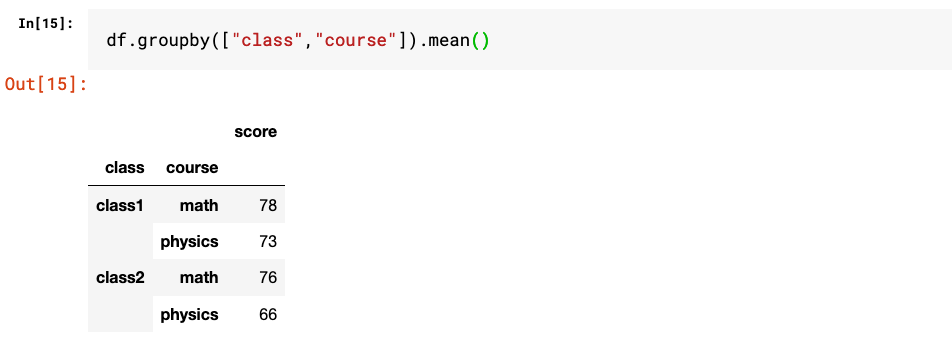
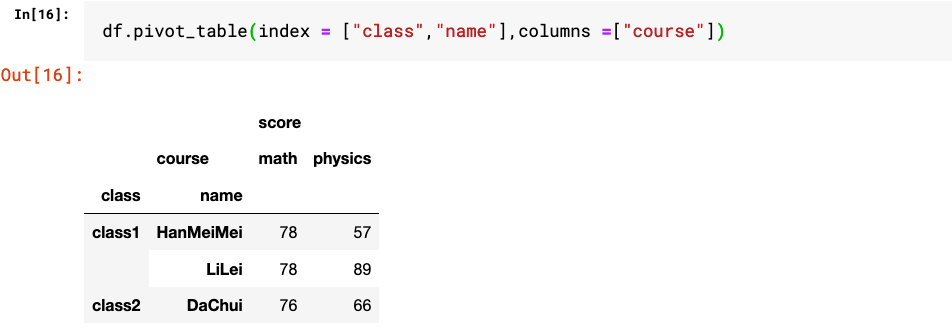
4. groupby和pivot_table等方法也可以生成带有多层级索引的结果
二、多层级索引的取值
多层级索引Series或多层级DataFrame支持方括号直接取值,loc取值,和pd.IndexSlice切片取值等方法。
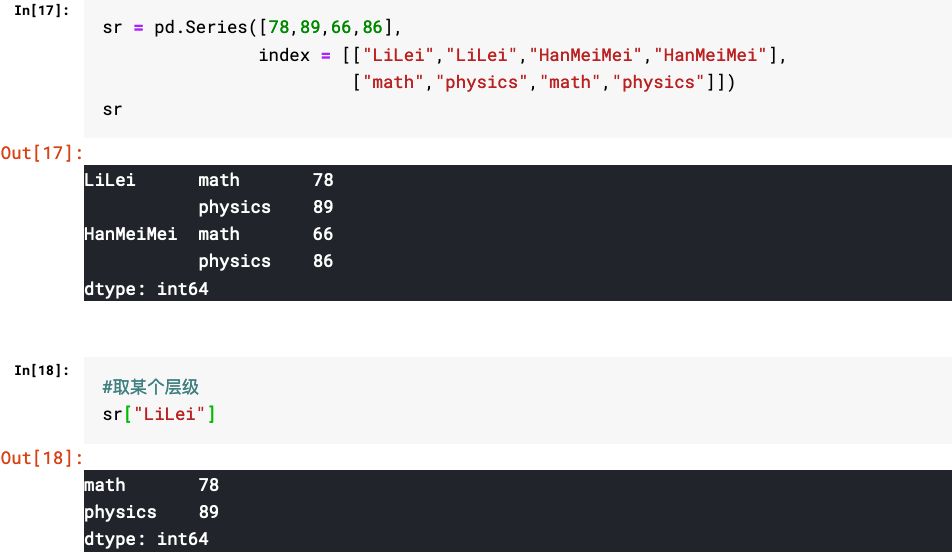
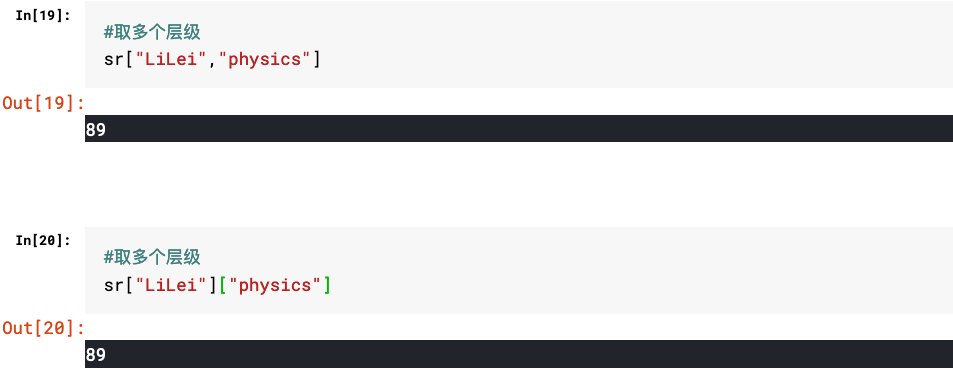
1.多层级Series的取值
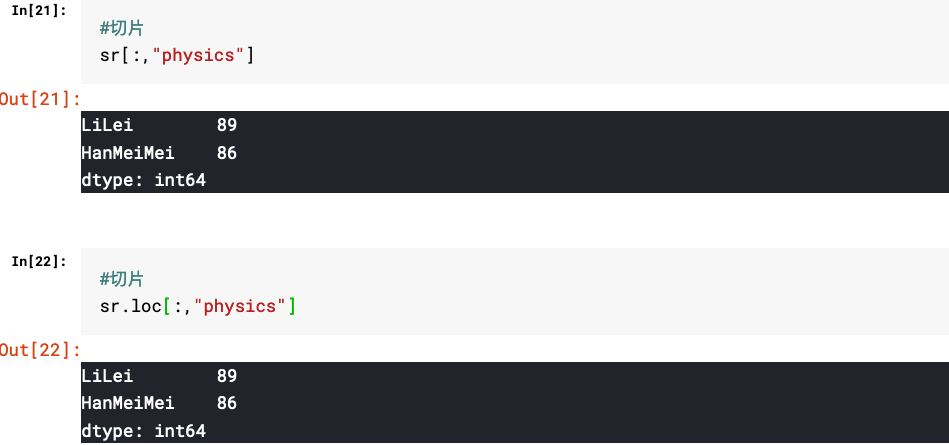

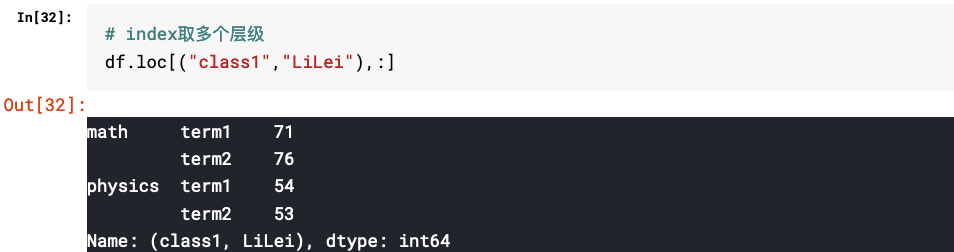
2.多层级DataFrame的取值

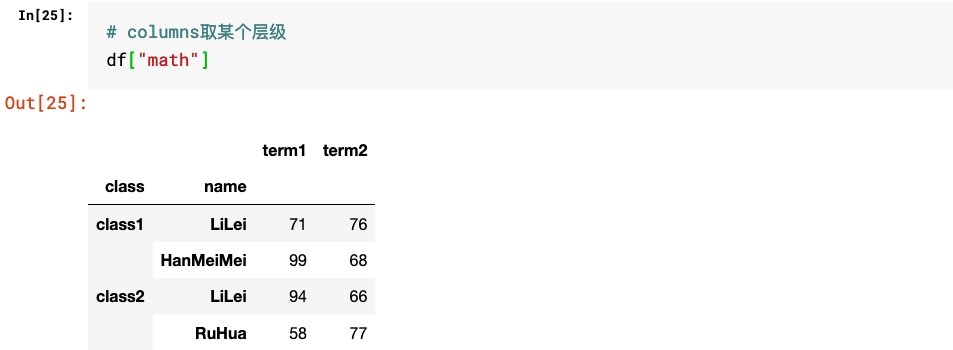
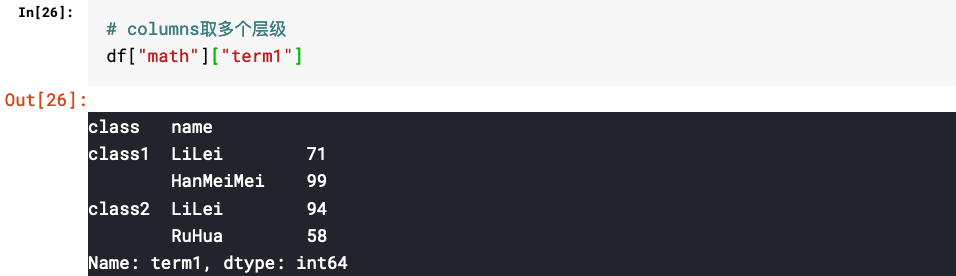
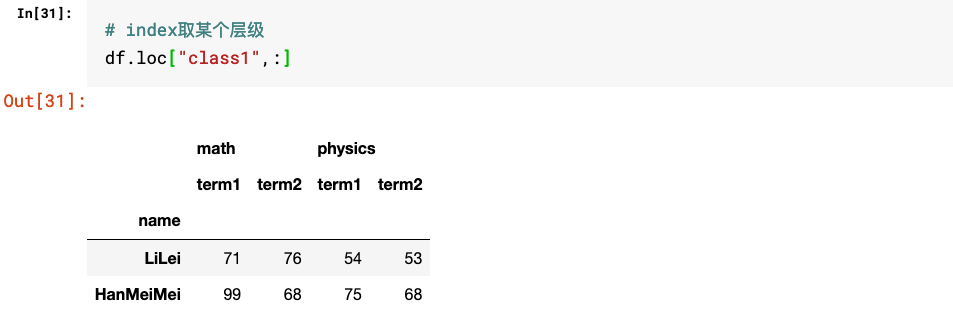

三、多层级索引相关操作
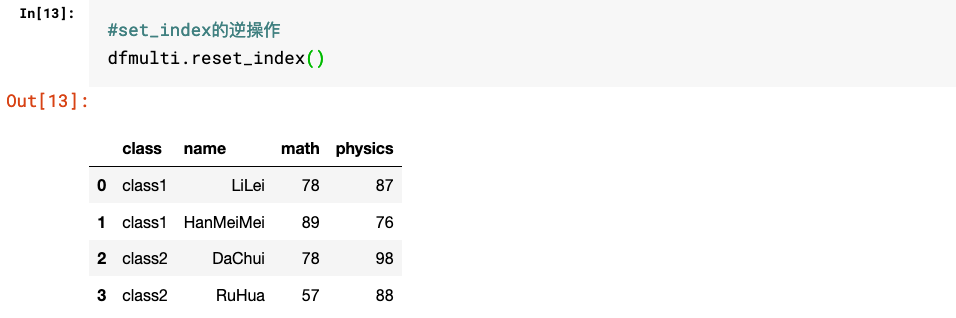
多层级索引相关操作包括stack和unstack,set_index和reset_index,以及指定level的相关方法。
1.stack和unstack

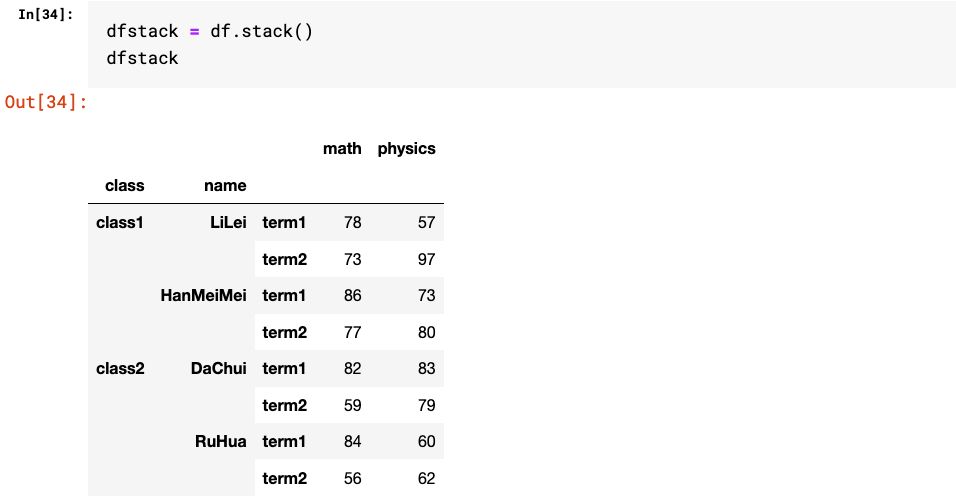
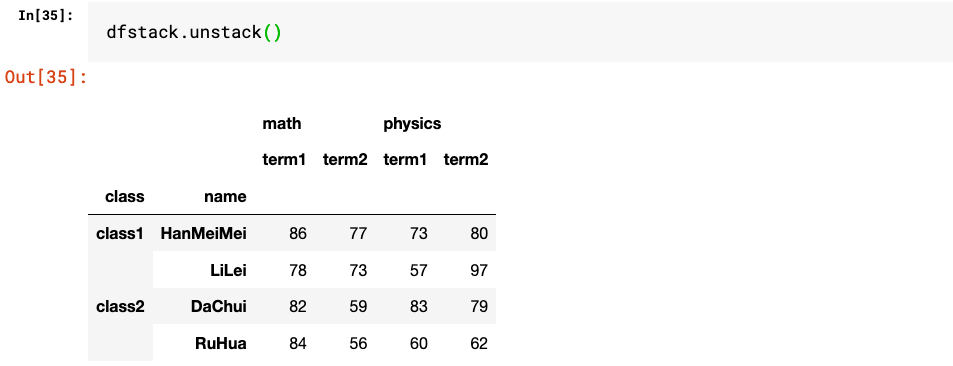
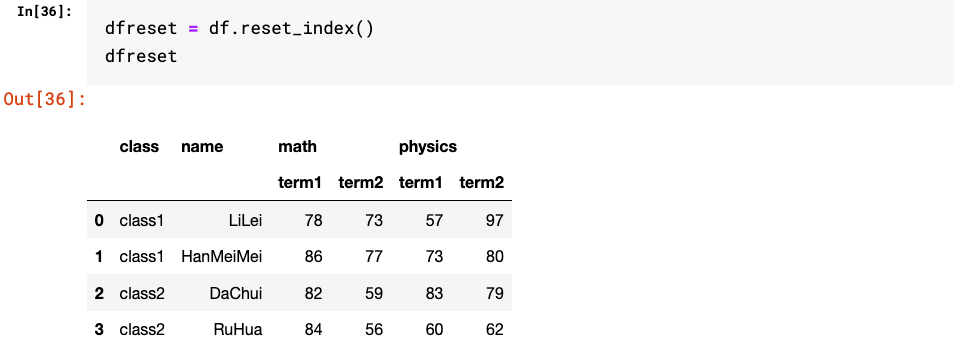
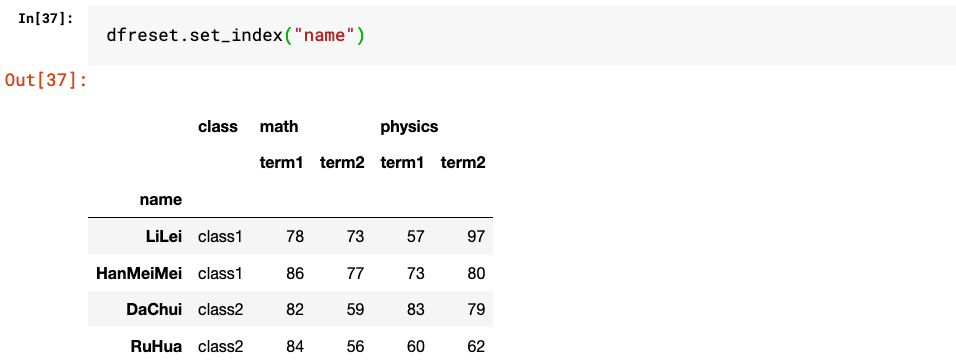
2.set_index和reset_index
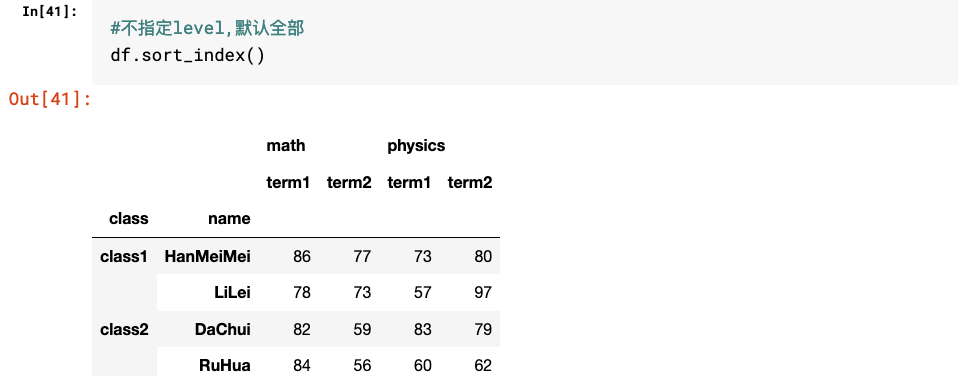
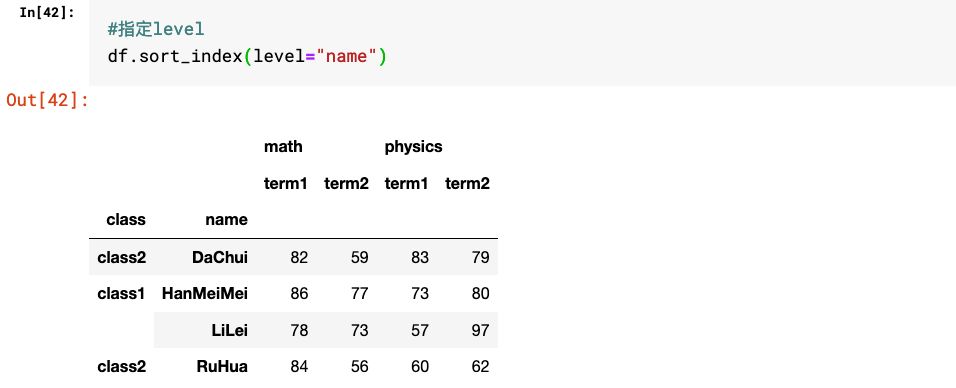
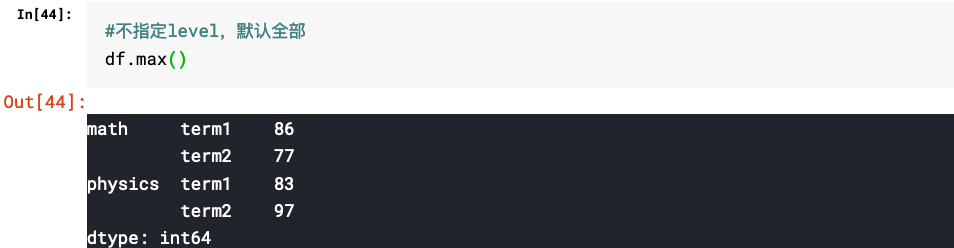
3.指定level的相关方法

(*本文是Python大本营转载文章,转载请联系原作者)
社群福利
扫码添加小助手,回复:大会,加入2019 AI开发者大会福利群,每周更新技术福利,还有不定期的抽奖活动~

推荐阅读

你点的每个“在看”,我都认真当成了喜欢















 1218
1218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









