







多层索引(Hierarchical indexing)又叫多层索引,它为一些非常复杂的数据分析和操作(特别是处理高维数据)提供了方法。从本质上讲,它使你可以在Series(一维)和DataFrame(二维)等较低维度的数据结构中存储和处理更高维度的数据。
文章目录
8.1 概述
本节介绍多层数据的一些基本概念和使用场景,以及如何创建多层索引数据。理解了多层数据的基本概念和使用场景,我们就能更好地应用它的特性来解决实际数据分析中的问题。
8.1.1 什么是多层索引
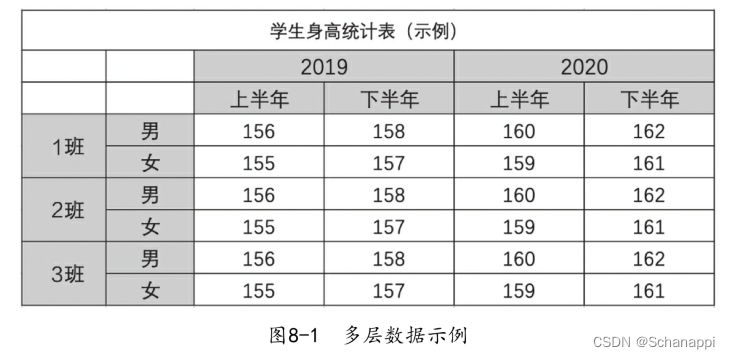
多层数据可以只有在行上为多层,可以只在列上为多层,也可以在两个方向上都为多层,理论上层数是没有限制的。除了原生数据为多层外,在做数据分组聚合等操作时也会产生多层数据。本质上,这其实是一个以低维形式展示的多维数据。
8.1.2 通过分组产生多层索引
多个分组条件会产生多层索引:
# eg:按团队分组,个图案段中平均成绩及格的人数
df.groupby(['team', df.mean(1)>=60]).count()
"""
name Q1 Q2 Q3 Q4
team
A False 14 14 14 14 14
True 3 3 3 3 3
B False 14 14 14 14 14
True 8 8 8 8 8
C False 17 17 17 17 17
True 5 5 5 5 5
D False 10 10 10 10 10
True 9 9 9 9 9
E False 15 15 15 15 15
True 5 5 5 5 5
"""
另外,如果对一列应用多个聚合计算方法,也会产生多层索引。比如计算某列的最大值和最小值,在行上就会产生两层索引。
8.1.3 由序列创建多层索引
MultiIndex对象是Pandas标准Index的子类,由它来表示多层索引业务。可以将MultiIndex视为一个元组对序列,其中每个元组对都是唯一的。可以通过以下方式生成一个索引对象。
序列数据:
# 定义一个序列
arrays = [[1, 1, 2, 2], ['A', 'B', 'A', 'B']]
# 生成多层索引
index = pd.MultiIndex.from_arrays(arrays, names=('class', 'team'))
"""
MultiIndex([(1, 'A'),
(1, 'B'),
(2, 'A'),
(2, 'B')],
names=['class', 'team'])
"""
可以用这个多层索引对象生成DataFrame:
pd.DataFrame([{'Q1':60, 'Q2':70}], index=index)
"""
Q1 Q2
class team
1 A 60 70
B 60 70
2 A 60 70
B 60 70
"""
8.1.4 由元组创建多层索引
可以使用pd.MultiIndex.from_tuples()将由元组组成的序列转换为多层索引。
# 定义一个两层的序列
arrays = [[1, 1, 2, 2], ['A', 'B', 'A', 'B']]
# 转换为元组
tuples = list(zip(*arrays)) # [(1, 'A'), (1, 'B'), (2, 'A'), (2, 'B')]
# 生成多层索引
index = pd.MultiIndex.from_tuples(tuples, names=['class', 'team'])
# 使用多层索引对象
pd.Series(np.random.randn(4), index=index)
"""
class team
1 A -0.526717
B -1.408692
2 A -1.003524
B -0.499982
dtype: float64
"""
8.1.5 可迭代对象的笛卡尔积
使用上述方法的时候需要将所有层的所有值都写出来,而pd.MultiIndex.from_product()可以做笛卡尔积计算,将所有情况排列组合出来。
_class = [1, 2]
team = ['A', 'B']
# 生成多层索引对象
index = pd.MultiIndex.from_product([_class, team], names=['class', 'team'])
# Series应用多层索引对象
pd.Series(np.random.randn(4), index=index)
"""
class team
1 A 0.923623
B 0.525440
2 A 0.832210
B -2.446039
dtype: float64
"""
8.1.6 将DataFrame转为多层索引对象
pd.MultiIndex.from_frame()可以将DataFrame的数据转化为多层索引对象。
df_i = pd.DataFrame([['1', 'A'], ['1', 'B'], ['2', 'A'], ['2', 'B']], columns=['class', 'team'])
# 将DataFrame中的数据转化为多层索引对象
index = pd.MultiIndex.from_frame(df_i)
# 应用多层对象
pd.Series(np.random.randn(4), index=index)
"""
class team
1 A -0.367022
B -0.226560
2 A -0.367938
B -0.118559
dtype: float64
"""
8.2 多层索引操作
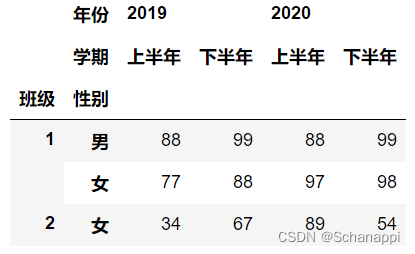
8.2.1 生成数据
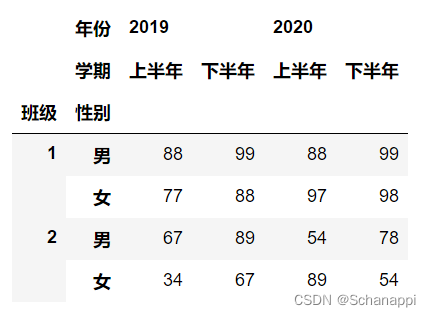
在介绍多层索引的构建时,我们将多层索引对象应用到了DataFrame和Series上,使其成为一个多层索引的DataFrame或Series。以下是一个典型的多层索引数据的生成过程:
# 索引
index_arrays = [[1, 1, 2, 2], ['男', '女', '男', '女']]
# 列名
columns_arrays = [['2019', '2019', '2020', '2020'], ['上半年', '下半年', '上半年', '下半年']]
# 索引转换为多层
index = pd.MultiIndex.from_arrays(index_arrays, names=('班级', '性别'))
# 列名转换为多层
columns = pd.MultiIndex.from_arrays(columns_arrays, names=('年份', '学期'))
# 应用到DataFrame中
df = pd.DataFrame([(88, 99, 88, 99), (77, 88, 97, 98),
(67, 89, 54, 78), (34, 67, 89, 54)],
columns=columns, index=index)
8.2.2 索引信息
多层索引也可以查看行、列及行与列的名称。
df.index # 索引,是一个MultiIndex
"""
MultiIndex([(1, '男'),
(1, '女'),
(2, '男'),
(2, '女')],
names=['班级', '性别'])
"""
df.columns # 列索引,也是一个MultiIndex
"""
MultiIndex([('2019', '上半年'),
('2019', '下半年'),
('2020', '上半年'),
('2020', '下半年')],
names=['年份', '学期'])
"""
# 查看行索引名称
df.index.names
# FrozenList(['班级', '性别'])
8.2.3 查看层级
多层索引由于层级较多,在数据分析时需要查看它共有多少个层级。
df.index.nlevels # 行层级数 2
df.index.levels # 行的层级 FrozenList([[1, 2], ['女', '男']])
8.2.4 索引内容
可以取指定层级的索引内容,也可以按索引名取索引内容:
# 获取索引第2层的内容
df.index.get_level_values(1)
# Index(['男', '女', '男', '女'], dtype='object', name='性别')
# 获取列索引第二层内容
df.columns.get_level_values(1)
# Index(['上半年', '下半年', '上半年', '下半年'], dtype='object', name='学期')
# 按索引名称取索引内容
df.index.get_level_values('班级')
# Int64Index([1, 1, 2, 2], dtype='int64', name='班级')
8.2.5 排序
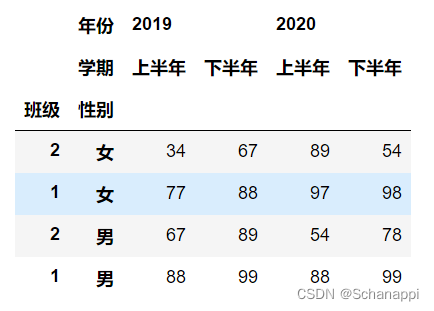
多层索引可以根据需要实现较为复杂的排序操作:
# 使用索引名可进行排序,可以指定具体的列
df.sort_values(by=['性别', ('2020', '下半年')]) # 先按照性别,然后按照2020-下半年,升序排列
df.index.reorder_levels([1, 0]) # 等级顺序,互换
# 班级:性别 -> 性别:班级
"""
MultiIndex([('男', 1),
('女', 1),
('男', 2),
('女', 2)],
names=['性别', '班级'])
"""
df.index.reindex(df.index[::-1]) # 顺序颠倒
"""
(MultiIndex([(2, '女'),
(2, '男'),
(1, '女'),
(1, '男')],
names=['班级', '性别']),
array([3, 2, 1, 0], dtype=int64))
"""
df.index.sortlevel(level=0, ascending=True) # 按指定级别排序
# 在请求的级别对MultiIndex进行排序。结果将遵守该级别上关联因子的原始排序
# 首先level=0:班级,按照1->2的顺序排列,其次,考虑班级的关联因子:性别,按照female->male
"""
(MultiIndex([(1, '女'),
(1, '男'),
(2, '女'),
(2, '男')],
names=['班级', '性别']),
array([1, 0, 3, 2], dtype=int64))
"""
idx.set_codes([1, 1, 0, 0], level='foo') # 设置顺序
8.2.6 其他操作
# 生成一个笛卡尔积的元组对序列
df.index.to_numpy()
# array([(1, '男'), (1, '女'), (2, '男'), (2, '女')], dtype=object)
# 返回没有使用的层级
df.index.remove_unused_levels()
"""
MultiIndex([(1, '男'),
(1, '女'),
(2, '男'),
(2, '女')],
names=['班级', '性别'])
"""
df.swaplevel(0, 1) # 交换索引
df.index.droplevel(0) # 删除指定等级并返回
df.index.get_locs((2, '女')) # 返回索引位置
idx.set_levels(['a', 'b'], level='bar') # 设置新的索引内容
idx.set_levels([['a', 'b', 'c'], [1, 2, 3, 4]], level=[0, 1])
idx.to_flat_index() # 转为元组对序列
8.3 数据查询
8.3.1 查询行
查询第一层级的某个索引下的内容,可以直接使用df.loc[]传入它的索引值:
df.loc[1] # 查看一班的数据
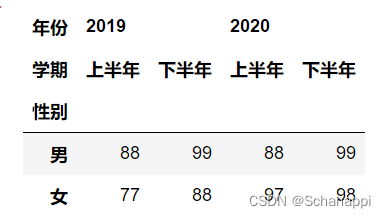
此外,切片(如df.loc[1:2]查询1班和2班的数据)也适用。
如果需要同时根据一二级索引查询,可以将需要查询的索引条件组成一个元组:
df.loc[(1, '男')] # 1班男生

8.3.2 查询列
查询列时,可以直接用切片选择需要查询的列,使用元组指定相关的层级数据:
df['2020'] # 整个一级索引下
df[('2020', '上半年')] # 指定二级索引
df['2020']['上半年'] # 同上
8.3.3 行列查询
行列查询和单层索引一样,指定层内容也用元组表示。slice(None)可以在元组中占位,表示本层所有内容:
df.loc[(1, '男'), '2020'] # 只显示2020年1班男生
"""
学期
上半年 88
下半年 99
Name: (1, 男), dtype: int64
"""
df.loc[:, (slice(None), '下半年')] # 只看下半年
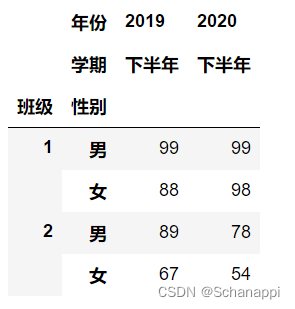
df.loc[(slice(None), '女'), :] # 只看女生
df.loc[(1, slice(None)), :] # 只看1班
8.3.4 条件查询
按照一定条件查询数据,和单层索引的数据查询一样,不过在选择列上要按多层的规则。
# 2020年上半年大于80的数据
df[df[('2020', '上半年')] > 80]
8.3.5 用pd.IndexSlice索引数据
pd.IndexSlice可以创建一个切片对象,轻松执行复杂的索引切片操作:
idx = pd.IndexSlice
idx[0] # 0
idx[:] # slice(None, None, None)
idx[0, 'x'] # (0, 'x')
idx[0:3] # slice(0, 3, None)
idx[0.1:1.5] # slice(0.1, 1.5, None)
idx[0:5, 'x':'y '] # (slice(0, 5, None), slice('x', 'y', None))
应用在查询中:
idx = pd.IndexSlice
df.loc[idx[:, ['男']], :] # 只显示男生
df.loc[:, idx[:, ['上半年']]] # 只显示上半年
8.3.6 df.xs()
使用df.xs()方法采用索引内容作为参数来选择多层索引数据中特定级别的数据:
df.xs((1, '男')) # 1班男生
df.xs('2020', axis=1) # 2020年 表头搭配axis
df.xs('男', level=1) # 所有男生 索引搭配level
8.4 本章小结
多层数据是基于业务需要产生的,它能够让数据的逻辑和归属更加清晰和明确,对于数据的展示和分析操作有重要意义。
在Pandas中,很多函数和方法都支持level参数,可以对指定层级的数据进行操作。
但是,要尽量避免让数据多层级化,以免数据处理复杂,可以先将数据筛选完成,再创建索引,保持一层索引。















 1917
1917











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









