







在python中,我们常用的数据分析库莫过于pandas,而数据分析中,我们常用的方法莫过于筛选、拼接、多级列表和数据透视了,下面我将通过四个板块对这四个方面进行介绍。
目录
- 筛选
- 拼接(连接)
- 多级列表
- 数据透视
- 完整代码
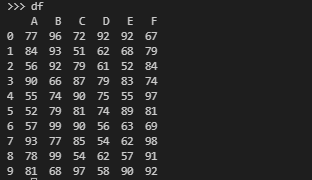
首先创建一个10*6的Dataframe,用到的库有pandas、numpy
import pandas as pd
import numpy as np
df=pd.DataFrame(np.random.randint(50,100, (10, 6)),columns=['A',"B",'C','D','E','F'])
df
一、 筛选
对于excel的常用就是对某列进行筛选操作了,那么我们在pandas中如何进行呢?其实pandas给我们提供了多个方法,不过最常用的还是loc和iloc,这两个方法的筛选逻辑不一样,简单的理解来说就是:loc是关注于列的筛选,iloc关注的行的筛选,两者的功能没有区别下面我分别介绍两种方法。
1.1、loc
上面已经创建好了df,下面我们开始利用df进行讲解
df.loc[a,b]
a表示行,b表示列,注意b只能为字符或者列表,不能为数字,否则报错,下面是相关的方法运用。
单列数据筛选
>>> df.loc[:,"A"]
0 77
1 84
2 56
3 90
4 55
5 52
6 57
7 93
8 78
9 81
Name: A, dtype: int32
多列数据筛选
df.loc[:,["A","B"]]
A B
0 77 96
1 84 93
2 56 92
3 90 66
4 55 74
5 52 79
6 57 99
7 93 77
8 78 99
9 81 68
也可以用:来进行引用,如下
>>> df.loc[:,"A":"E"]
A B C D E
0 77 96 72 92 92
1 84 93 51 62 68
2 56 92 79 61 52
3 90 66 87 79 83
4 55 74 90 75 55
5 52 79 81 74 89
6 57 99 90 56 63
7 93 77 85 54 62
8 78 99 54 62 57
9 81 68 97 58 90
上面简单的介绍了loc方法筛选列,下面来介绍筛选行
对多行的单列值进行筛选:
>>> df.loc[df['B']==99]
A B C D E F
6 57 99 90 56 63 69
8 78 99 54 62 57 91
对B列进行筛选筛选其值等于99的数据。
对多行数据的多列值进行筛选:
>>> df.loc[(df['B']==99)&(df['C']==90)] #注意细节,这里需要加(),否则会报错
A B C D E F
6 57 99 90 56 63 69
这里有个细节,对列的数据进行并列筛选时,注意细节,这里需要加(),否则会报错
1.2、iloc
下面来介绍iloc,用法大概如下
df.iloc[a,b]
这个地方a和b都必须是intege。iloc的列参数只能是整数;
a代表的行,b代表的列
列筛选:
>>> df.iloc[2,:]
A 56
B 92
C 79
D 61
E 52
F 84
Name: 2, dtype: int32
>>> df.iloc[2,3:5]
D 61
E 52
Name: 2, dtype: int32
如果发现这个取数的格式不是我们想的那样,想要如df格式那样,如下:
>>> df.iloc[2:3,3:5]
D E
2 61 52
这里进行总结一下,loc和iloc的主要区别有两个
1、两者参数都是[行,列],但是loc的列参数不能为数字,必须为columns,否则会报错
iloc的参数为数字,否则也会报错
2、: loc的带:参数实行的左闭右闭规则,但是iloc实行的是左闭右开规则,所以取数逻辑不一样。
二、拼接
拼接,又称作连接,对于df的绘制非常的重要,一般常用的有append、merge、concat,在这里,主要讲解merge和concat。
2.1、merge
merge的产生主要如下:
pd.merge(left, right,
how='inner',
on=None,
left_on=None,
right_on=None,
left_index=False,
right_index=False, sort=True,
suffixes=('_x', '_y'),
copy=True,
ind 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3733
3733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









