






训练模型
一、讨论两种训练方法二、线性回归三、如何训练四、正规方程五、示例六、模型图像七、梯度下降八、梯度下降的陷阱
一、讨论两种训练方法
1、直接使用封闭方程进行求根运算,得到模型在当前训练集上的最优参数(即在训练集上使损失函数达到最小值的模型参数)
二、线性回归
线性回归预测模型
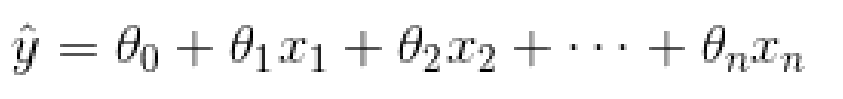

三、如何训练
训练一个模型指的是设置模型的参数使得这个模型在训练集的表现较好。为此,我们首先需要找到一个衡量模型好坏的评定方法。在回归模型上,最常见的评定标准是均方根误差。因此,为了训练一个线性回归模型,需要找到一个θ值,它使得均方根误差(标准误差)达到最小值。实践过程中,最小化均方误差比最小化均方根误差更加的简单,这两个过程会得到相同的θ因为函数在最小值时候的自变量,同样能使函数的方根运算得到最小值。
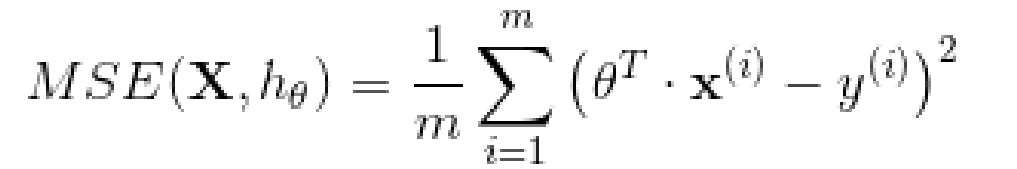
四、正规方程
为了找到最小化损失函数的 值,可以采用公式解,换句话说,就是可以通过解正规方程直接得到最后的结果。

五、示例
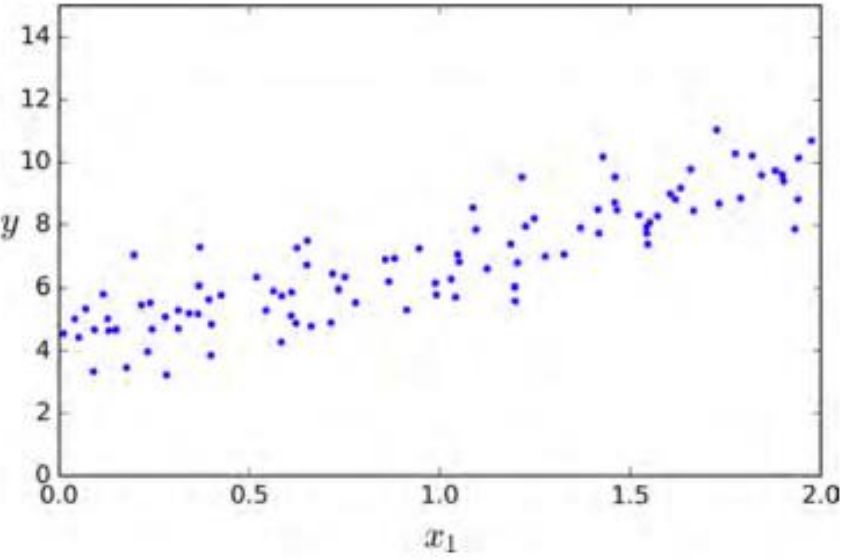
生成一些近似线性的数据来测试一下这个方程。
import numpy as np
X = 2 * np.random.rand(100, 1)
y = 4 + 3 * X + np.random.randn(100, 1)
X_b = np.c_[np.ones((100, 1)), X]
theta_best = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y)
实际上产生数据的两个系数是4和3 。让我们看一下最后的计算结果。
>>> theta_best
array([[4.21509616],[2.77011339]])
由于存在噪声,参数不可能达到到原始函数的值。现在我们能够使用 来进行预测:
X_new = np.array([[0],[2]])
X_new_b = np.c_[np.ones((2, 1)), X_new]
y_predict = X_new_b.dot(theta_best)
y_predict
>>>array([[4.21509616],[9.75532293]])
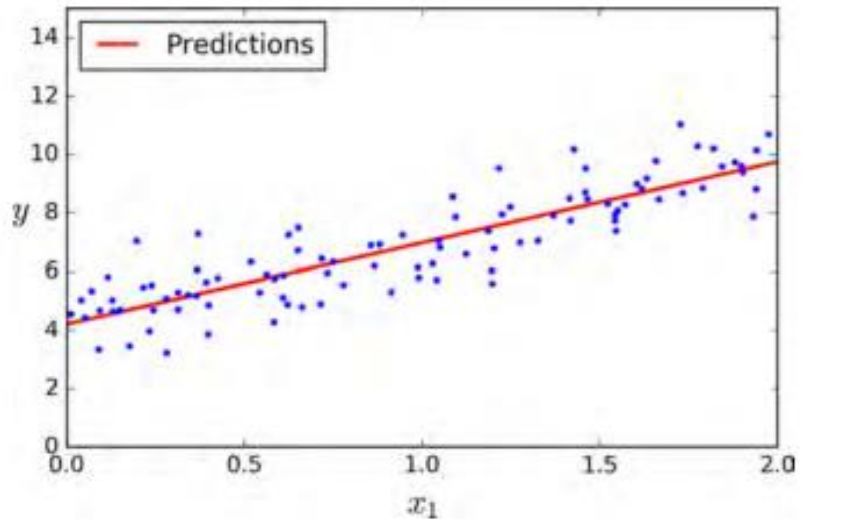
六、模型图像
plt.plot(X_new,y_predict,"r-")
plt.plot(X,y,"b.")
plt.axis([0,2,0,15])
plt.show()
使用下面的 Scikit-Learn 代码可以达到相同的效果:
from sklearn.linear_model import LinearRegression
lin_reg = LinearRegression()
lin_reg.fit(X,y)
lin_reg.intercept_, lin_reg.coef_
(array([4.21509616]),array([2.77011339]))
lin_reg.predict(X_new)
array([[4.21509616],[9.75532293]])
七、梯度下降
梯度下降是一种非常通用的优化算法,它能够很好地解决一系列问题。梯度下降的整体思路是通过的迭代来逐渐调整参数使得损失函数达到最小值。
八、梯度下降的陷阱
幸运的是线性回归模型的均方差损失函数是一个凸函数,这意味着如果你选择曲线上的任意两点,它们的连线段不会与曲线发生交叉(译者注:该线段不会与曲线有第三个交点)。这意味着这个损失函数没有局部最小值,仅仅只有一个全局最小值。同时它也是一个斜率不能突变的连续函数。这两个因素导致了一个好的结果:















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









