







在这段视频中,我们将会找出一种稍微简单一点的方法来写代价函数,来替换我们现在用的方法。同时我们还要弄清楚如何运用梯度下降法,来拟合出逻辑回归的参数。因此,听了这节课,你就应该知道如何实现一个完整的逻辑回归算法。
这就是逻辑回归的代价函数:

这个式子可以合并成:

逻辑回归的代价函数:

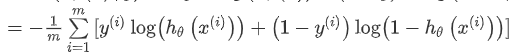
根据这个代价函数,为了拟合出参数,该怎么做呢?我们要试图找尽量让
J
(
θ
)
J(\theta)
J(θ)取得最小值的参数
θ
\theta
θ。
m
i
n
J
(
θ
)
min J(\theta)
minJ(θ)所以我们想要尽量减小这一项,我们将得到某个参数
θ
\theta
θ。如果我们给出一个新的样本,加入某个特征x,我们可以用拟合训练样本的参数
θ
\theta
θ,来输出对假设的预测。另外,我们家属的输出,实际上就是这个概率值:
p
(
y
=
1
∣
x
;
θ
)
p(y=1|x;\theta)
p(y=1∣x;θ),就是关于x以
θ
\theta
θ为参数,
y
=
1
y=1
y=1的概率,你可以认为我们的假设就是估计
y
=
1
y=1
y=1的概率,所以,接下来就是弄清楚如何最大限度地最小化代价函数
J
(
θ
)
J(\theta)
J(θ),作为一个关于
θ
\theta
θ的函数,这样我们才嫩为训练集拟合出参数
θ
\theta
θ。
最小化代价函数的方法,是使用梯度下降法(gradient descent)。这是我们的代价函数:
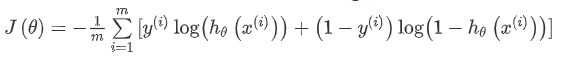
如果我们要最小化这个关于
θ
\theta
θ的函数值,这就是我们通常用的梯度下降法的模板。

我们要反复更新每个参数,用这个式子来更新,就是用它自己减去学习率
α
\alpha
α乘以后面的微分项。求导后得到:

如果你计算一下的话,你会得到这个等式:
θ
j
:
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}
θj:=θj−αm1∑i=1m(hθ(x(i))−y(i))xj(i)我把它写在这里,将后面这个式子,在
i
=
1
i=1
i=1到
m
m
m上求和,其实就是预测误差乘以
x
j
(
i
)
x_{j}^{(i)}
xj(i) ,所以你把这个偏导数项
∂
∂
θ
j
J
(
θ
)
\frac{\partial}{\partial\theta_{j}}J(\theta)
∂θj∂J(θ)放回到原来式子这里,我们就可以将梯度下降算法写作如下形式:
θ
j
:
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}
θj:=θj−αm1∑i=1m(hθ(x(i))−y(i))xj(i)
所以,如果你有 n个特征,也就是说:
θ
=
[
θ
0
θ
1
θ
2
.
.
.
θ
n
]
\theta =\begin{bmatrix} \theta_{0}\\ \theta_{1}\\ \theta_{2}\\ ...\\ \theta_{n} \end{bmatrix}
θ=⎣⎢⎢⎢⎢⎡θ0θ1θ2...θn⎦⎥⎥⎥⎥⎤,参数向量包括
θ
0
,
θ
1
,
θ
2
\theta_{0},\theta_{1},\theta_{2}
θ0,θ1,θ2 一直到
θ
n
\theta_{n}
θn,那么你就需要用这个式子:
θ
j
:
=
θ
j
−
α
1
m
∑
i
=
1
m
(
h
θ
(
x
(
i
)
)
−
y
(
i
)
)
x
j
(
i
)
\theta_{j}:=\theta_{j}-\alpha\frac{1}{m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})x_{j}^{(i)}
θj:=θj−αm1∑i=1m(hθ(x(i))−y(i))xj(i)
来同时更新所有的值。
现在,如果你把这个更新规则和我们之前用在线性回归上的进行比较的话,你会惊讶地发现,这个式子正是我们用来做线性回归梯度下降的。
那么,线性回归和逻辑回归是同一个算法吗?要回答这个问题,我们要观察逻辑回归看看发生了哪些变化。实际上,假设的定义发生了变化。
对于线性回归假设函数:
h
θ
(
x
)
=
θ
T
X
=
θ
0
x
0
+
θ
1
x
1
+
.
.
.
+
θ
n
x
n
h_{\theta}(x)=\theta^{T}X=\theta_{0}x_{0}+\theta_{1}x_{1}+...+\theta_{n}x_{n}
hθ(x)=θTX=θ0x0+θ1x1+...+θnxn
而现在逻辑函数假设函数:
h
θ
(
x
)
=
1
1
+
e
−
θ
T
X
h_{\theta}(x)=\frac{1}{1+e^{-\theta^{T}X}}
hθ(x)=1+e−θTX1
因此,即使更新参数的规则看起来基本相同,但由于假设的定义发生了变化,所以逻辑函数的梯度下降,跟线性回归的梯度下降实际上是两个完全不同的东西。
在先前的视频中,当我们在谈论线性回归的梯度下降法时,我们谈到了如何监控梯度下降法以确保其收敛,我通常也把同样的方法用在逻辑回归中,来监测梯度下降,以确保它正常收敛。
当使用梯度下降法来实现逻辑回归时,我们有这些不同的参数 θ \theta θ,就是KaTeX parse error: Expected '}', got 'EOF' at end of input: …eta_{1}\theta_{一直到,我们需要用这个表达式来更新这些参数。我们还可以使用 for循环来更新这些参数值,用 for i=1 to n,或者 for i=1 to n+1。当然,不用 for循环也是可以的,理想情况下,我们更提倡使用向量化的实现,可以把所有这些 个参数同时更新。
最后还有一点,我们之前在谈线性回归时讲到的特征缩放,我们看到了特征缩放是如何提高梯度下降的收敛速度的,这个特征缩放的方法,也适用于逻辑回归。如果你的特征范围差距很大的话,那么应用特征缩放的方法,同样也可以让逻辑回归中,梯度下降收敛更快。
就是这样,现在你知道如何实现逻辑回归,这是一种非常强大,甚至可能世界上使用最广泛的一种分类算法。















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









