







代价函数
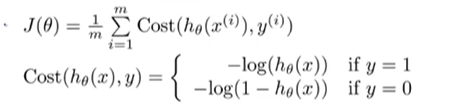
将cost分段函数整合成一个函数:
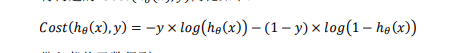
即y=1时cost=−𝑙𝑜𝑔(ℎ𝜃(𝑥)),y=0时cost=−𝑙𝑜𝑔(1 − ℎ𝜃(𝑥))。
代入代价函数得:
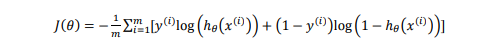
梯度下降法
在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能使 代价函数𝐽(𝜃) 最小的参数𝜃了min𝜃𝐽(𝜃)。
假如某个特征 𝑥,我们可以用拟合训练样本的参数𝜃,来输出对假设的预测;这个输出值𝑝(𝑦 = 1|𝑥; 𝜃)实际是关于x以𝜃为参数。y=1的概率值;而我们的参数𝜃使得输出值更好得拟合训练集。
梯度函数原式:
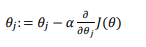
其中: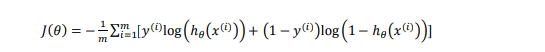
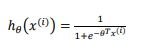
将h代入代入J函数得: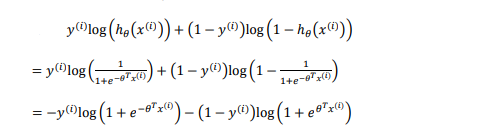
在将得到得J函数代入梯度下降函数得:
**注意:**虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里的ℎ𝜃(𝑥) = 𝑔(𝜃𝑇𝑋)与线性回归中不同,所以实际上是不一样的。
一些梯度下降算法之外的选择: 除了梯度下降算法以外,还有一些常被用来令代价函数最小的算法,比梯度下降算法要更加快速。这些算法有:共轭梯度法、BFGS (变尺度法) 和 L-BFGS (限制变尺度法) 。这些算法 不需要手动选择学习率α。算法利用一个内部循环(即为线性搜索(line search)算法)自动尝试不同得学习率α。
当我们遇到一个很大得机器学习问题时,应该选择这些高级算法,而不是梯度下降算法。
一对多的分类算法
多是指分类的类别数量。


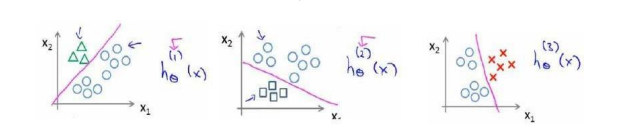
我们将多个类中的一个类标记为正向类(𝑦 = 1),然后将其他所有类都标记为负向类,这个模型记作ℎ𝜃(1)(𝑥)。接着,类似地第我们选择另一个类标记为正向类(𝑦 = 2),再将其它类都标记为负向类,将这个模型记作 ℎ𝜃(2)(𝑥),依此类推。
每次训练一个逻辑回归分类器:每个分类器都是只针对其中一种分类情况进行训练**,将多元分类问题化成多个二元分类问题**。
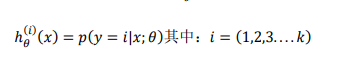
总结:ℎ𝜃(𝑖)(𝑥),其中 𝑖 对应每一个可能的 𝑦 = 𝑖,最后,为了做出预测,我们给出输入一个新的 𝑥值,用这个做预测。我们要做的就是在我们三个分类器里面输入 𝑥,然后我们选择一让 ℎ𝜃(𝑖)(𝑥)最大的𝑖,即max𝑖ℎ𝜃(𝑖)(𝑥)。
无论𝑖值是多少,我们都有最高的概率值,我们预测𝑦就是那个值。















 312
312











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









