









HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis
官方code: hifigan
基于GAN的声码器提升了合成效率降低了memory,但是合成的音质还没有做到像自回归的声码器和基于glow的声码器那么好。本文提出了一种高效率高保真的声码器,由于语音音频由具有不同周期的正弦信号组成,本文证明了对音频的周期性模式进行建模对于提高样本质量至关重要。在效率方面,在Tesla V100 GPU上,生成22.05k采样率的高保真音频的实时率达到了167.9,a small foot print版本, 在CPU比自回归的声码器实现了13.4倍的加速。效果方面,在单说话人语料上,MOS得分达到和真实音频相同,更近一步地探索了HiFi-GAN的泛化性。
1. Introduction
随着神经网络的发展,语音合成技术得到了快速发展。大部分语音合成模块应用了两阶段的pipeline。第一阶段:从文本建模低分辨率的中间表示,如mel特征,即声学模型;第二阶段:应用中间表达重建音频,即声码器。本文的工作承担的是第二阶段的任务,即声码器。
声码器的研究主要围绕着两个方面:提升音质和提升合成的效率。WaveNet 可以生成超过传统方法音质的音频,但是由于自回归结构,效率不高;基于Flow生成模型的声码器意在提升声码器的效率如Parallel WaveNet、WaveGlow 等工作。Generative adversarial networks (GANs)也被应用到语音合成中,如MelGAN能够实现CPU实时合成。但是音质与WaveNet和基于flow的声码器相比还有一定的差距。本文提出了HiFi-GAN,有着高推理效率以及与WaveNet音质持平的声码器。
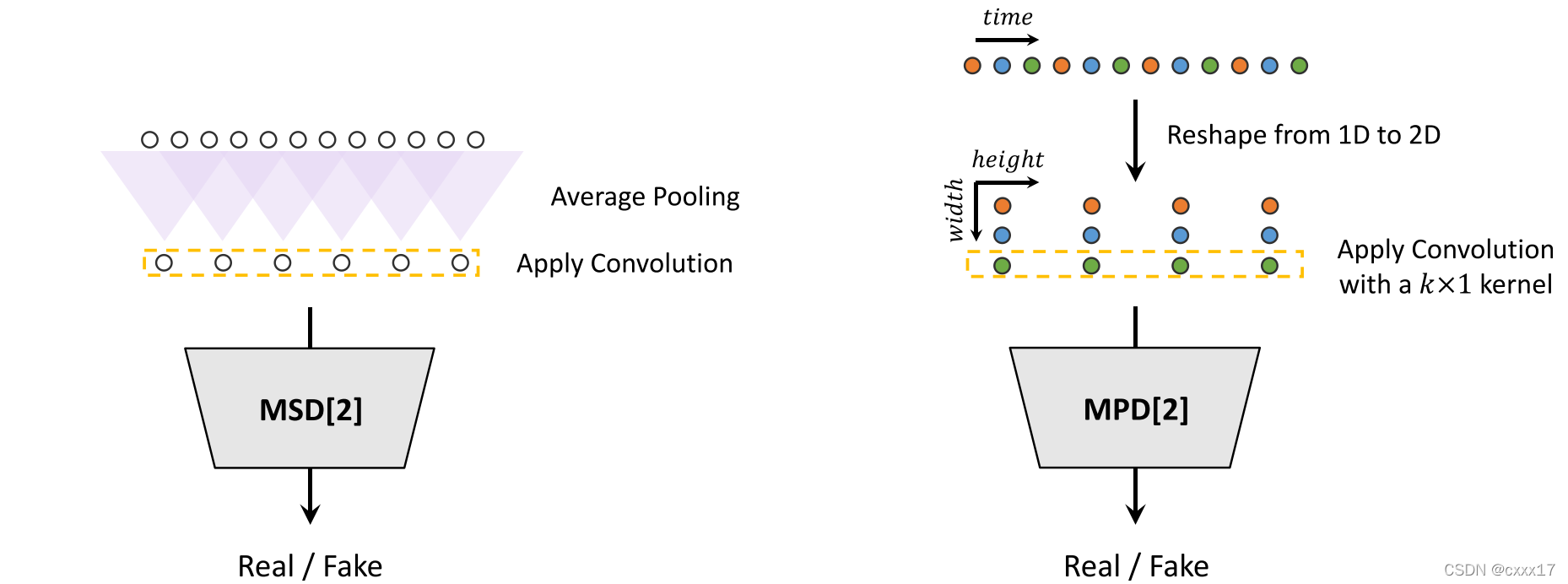
由于语音音频由具有不同周期的正弦信号组成,因此对周期模式进行建模对于生成逼真的语音音频很重要。 因此,本文提出了一个由小的子鉴别器组成的鉴别器,每个子鉴别器只获得原始波形的特定周期部分。这种架构是本周模型成功合成逼真语音音频的基础。 为鉴别器提取音频的不同部分时,本文还设计了一个模块,该模块放置多个残差块,每个残差块并行观察各种时长部分,并将其应用于生成器。
HiFi-GAN在MOS分上超过了WaveNet 和WaveGlow。合成音频demo链接,官方开源code。
2. Generator
是个全卷积的网络,输入是mel谱,通过反卷积(transposed conv)上采样,直到长度与音频采样点长度match。每层反卷积层后面跟着一个Multi-Receptive Field Fusion模块,Multi-Receptive Field Fusion模块是一组感受野不同的卷积层,能够并行地观察不同长度上下文。每组卷积层,层与层之间有残差链接。Generator结构和Multi-Receptive Field Fusion模块结构如下图所示。

3. Discriminator
一共有两个Discriminator一个是利用了不同时长的上下文的临近信息(Multi-Period Discriminator),另一个与MelGAN相同,对整句音频进行鉴别(Multi-Scale Discriminator);结构分别如下图所示:
4. Training Loss Terms
4.1 GAN Loss
常规的GAN Discriminator和Generator互相监督的Loss;
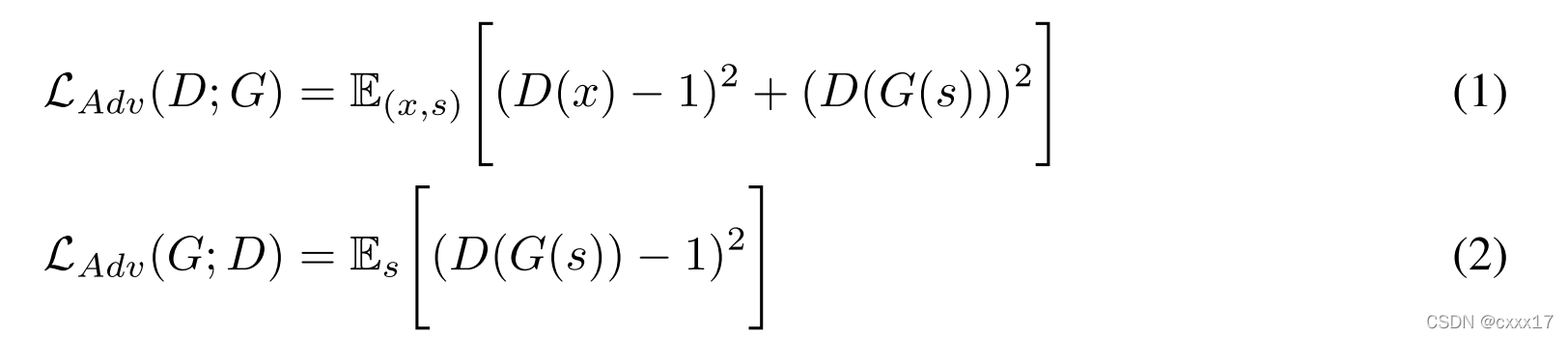
4.2 Mel-Spectrogram Loss
生成音频的mel与原音频的mel做Loss。
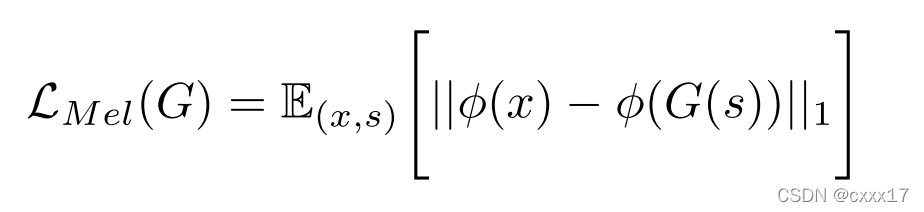
4.3 Feature Matching Loss
生成音频与真实音频在鉴别器中间结果的Loss

4.4 Final Loss
以上几个Loss加权相加。
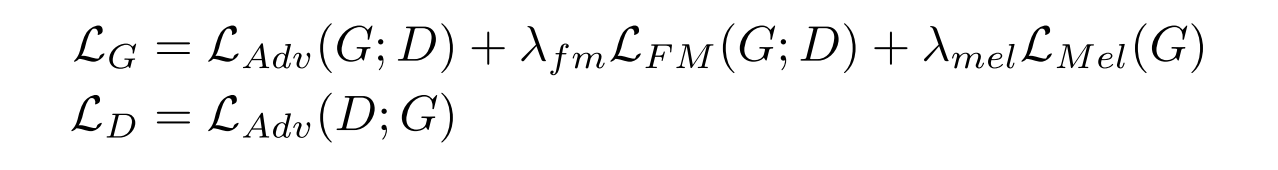
5. Experiments
5.1 主观评测
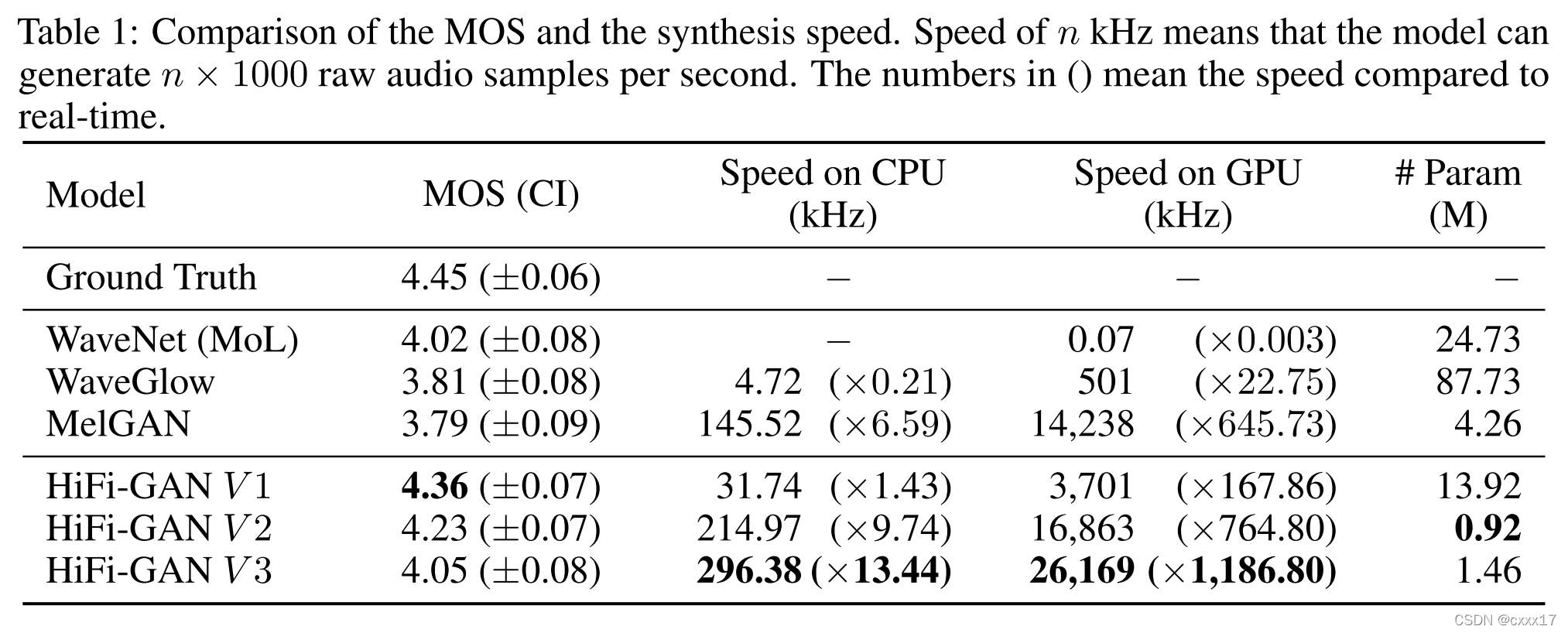
5.2 Ablation Study
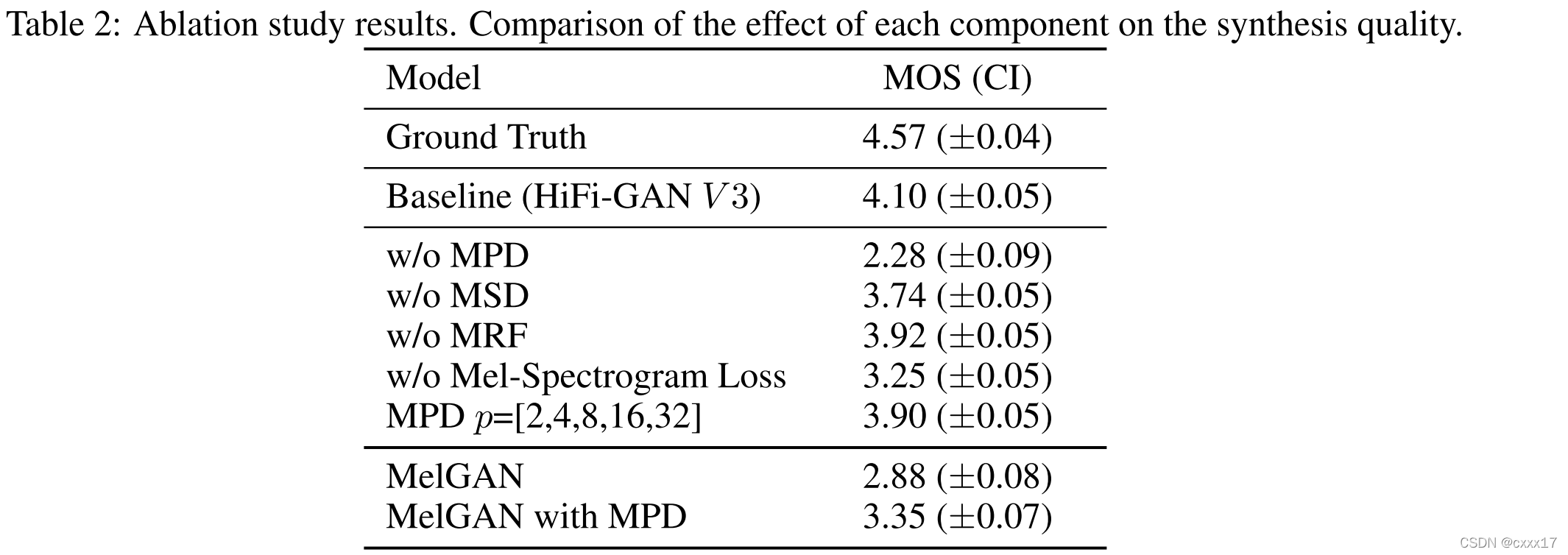
5.3 Generalization to Unseen Speakers
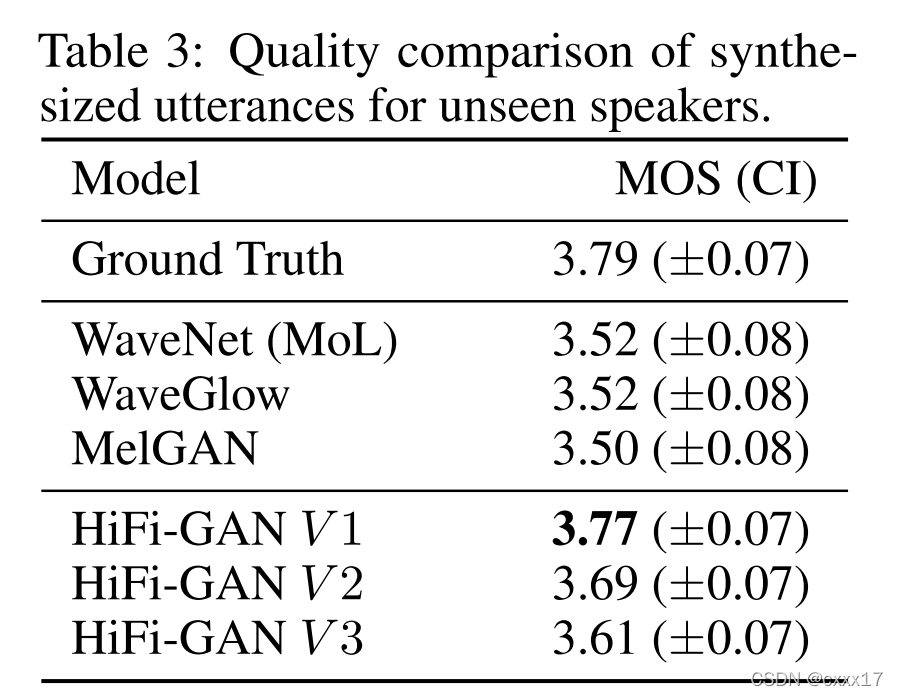
5.4 End-to-End Speech Synthesis
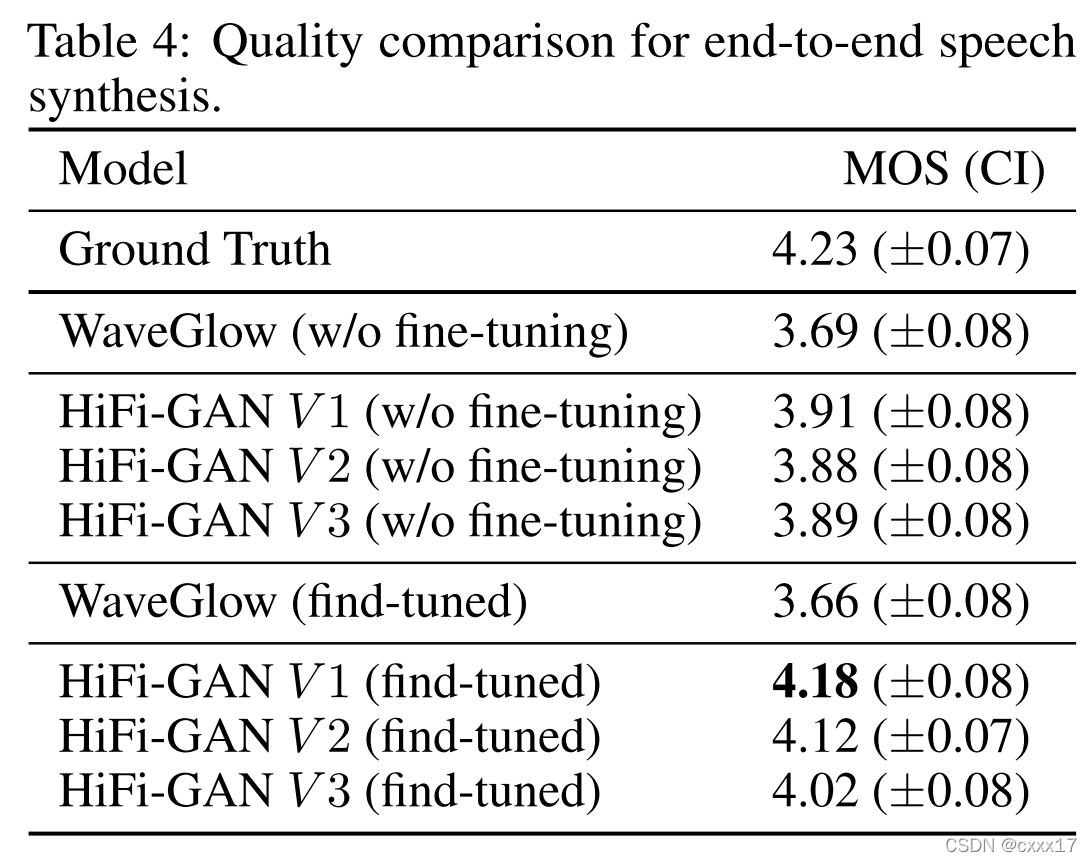

















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









