







【S2ST】Direct Speech-to-Speech Translation With Discrete Units
Abstract
Applying a self-supervised method extracts discrete units(rather than target text) from target speech, speech-to-unit translation(S2UT). Model unit to target speech.
应用自监督方法,生成target speech离散的units(S2UT), 从离散的units建模speech。当target text可以获得时,本文设计了一个语音和文本联合训练的框架,可以同时产生文本和语音两个模态的输出。在Fisher SpanishEnglish dataset数据集上,与Transformer Translatotron相比提升了6.7 BLEU。当没有任何文本的transcription时,模型达到了和有文本监督的时候相当的效果,说明了模型在unwrittern language的translation的潜力。
Introduction
传统的speech-to-text translation (S2T)方法,应用ASR+MT级联,近年来为了减缓级联系统的误差累计,end-to-end S2T方法被提出,这些S2T模型进一步接一个text-to-speech (TTS)模型,即可以产生speech和text的translation,具有广泛的应用场景。
最近,researcher开始探索direct speech-to-speech translation (S2ST), 不依赖中间的text generation过程[Translatotron][Translatotron2]。与级联系统相比,直接 S2ST 具有更低的计算成本和推理延迟的好处,因为需要更少的解码步骤。此外,直接 S2ST 是可以翻译unwriiten language。Translatotron 首先通过训练基于注意力的序列到序列模型来解决这个问题,该模型将source频谱图映射到target频谱图。模型训练难度大,因为它需要模型不仅可以学习两种语言之间的对齐,还可以学习两种语言的声学和语言特征。因此,直接 S2ST 系统和 S2T+TTS 级联系统之间存在性能差距。最近对语音自我监督学习的成功表明,从大型未标记语音语料库中学习到的语音表示可以在包括 ASR 、说话人和语言识别等各种下游任务上取得令人印象深刻的性能。此外,从自监督语音表示的聚类中获得的离散语音单元允许研究人员利用现有的语音 NLP 建模技术,例如spoken generative language modeling。
在这项工作中,我们通过预测target语音的自监督离散表示而不是梅尔谱图特征来解决在直接 S2ST 中建模目标语音的挑战。与谱图特征相比,自监督离散units可以将语言内容与说话人识别或语音中的韵律信息区分开来。
对于有target transcription的语言,联合学习S2ST和S2T,发现离散单元+speech text联合训练+beam search能达到ST+TTS的性能。接着探索了用source speech和target speech 离散的单元multi task learning,这为不用text,训练直接的S2ST提供了可能性。除此之外,本文测量了推理时间和memory,本文提出的系统比cascaded系统更有效率。
Related work
Cascaded ASR+MT->ST->S2ST
Model
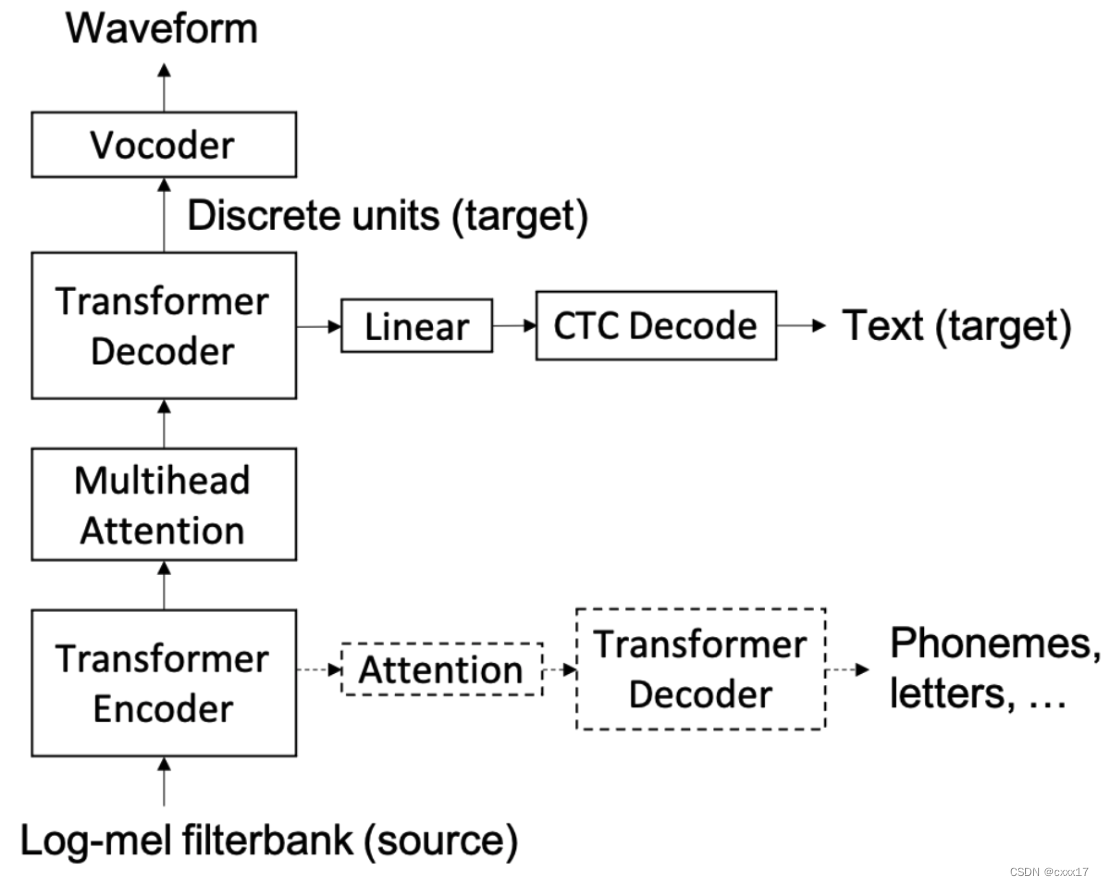
Speech-to-unit translation (S2UT) model
Hubert generate units, s2ut model refer to MT model(transformer based)
Multitask learning
Encoder 接辅助模块,识别phoneme, character, subword units 或者source、target句子的其他tokens。
对于written target languages,添加了以离散单元解码器中间层为条件的目标文本CTC解码,用于模型生成双模态输出。CTC 的使用可以减轻语音和文本输出之间的长度不匹配。然而,由于它只允许单调对齐,因此source和target之间的reorder依赖transformer层。
Unit-based vocoder
Unit hifigan
Experiments
Data
Fisher Spanish-English speech translation corpus(是个st的数据集,需要调TTS接口生成target speech)
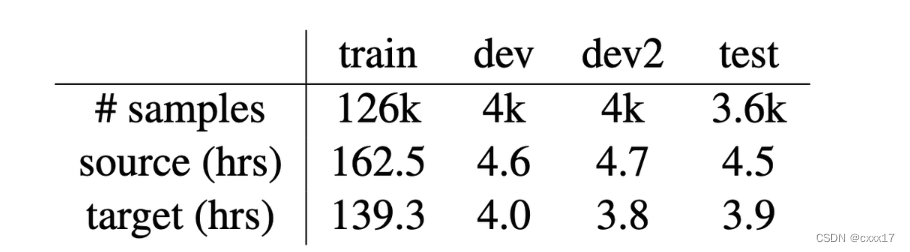
System setup
HuBERT base, extract units on English speech. 在source speech应用倒谱均值和方差归一化和SpecAugment. 应用了4个辅助任务, source phonemes (sp), target phonemes (tp), source characters (sc) and target characters (tc). Sp 和 sc 接在第六层,tp和tc接在encoder 的第8层和decoder。
Baseline
Two cascaded baselines, ASR+MT+TTS, S2T+TTS; One direct S2ST baseline.
ASR
transformer-based Spanish ASR, transformer-based
MT
gru_transformer
TTS
transformer-based TTS model
S2T
尝试了LSTM-based model 和 transformer-based model, LSTM-based model更好。
Transformer Translatotron
Evaluation
translation quality and the speech quality
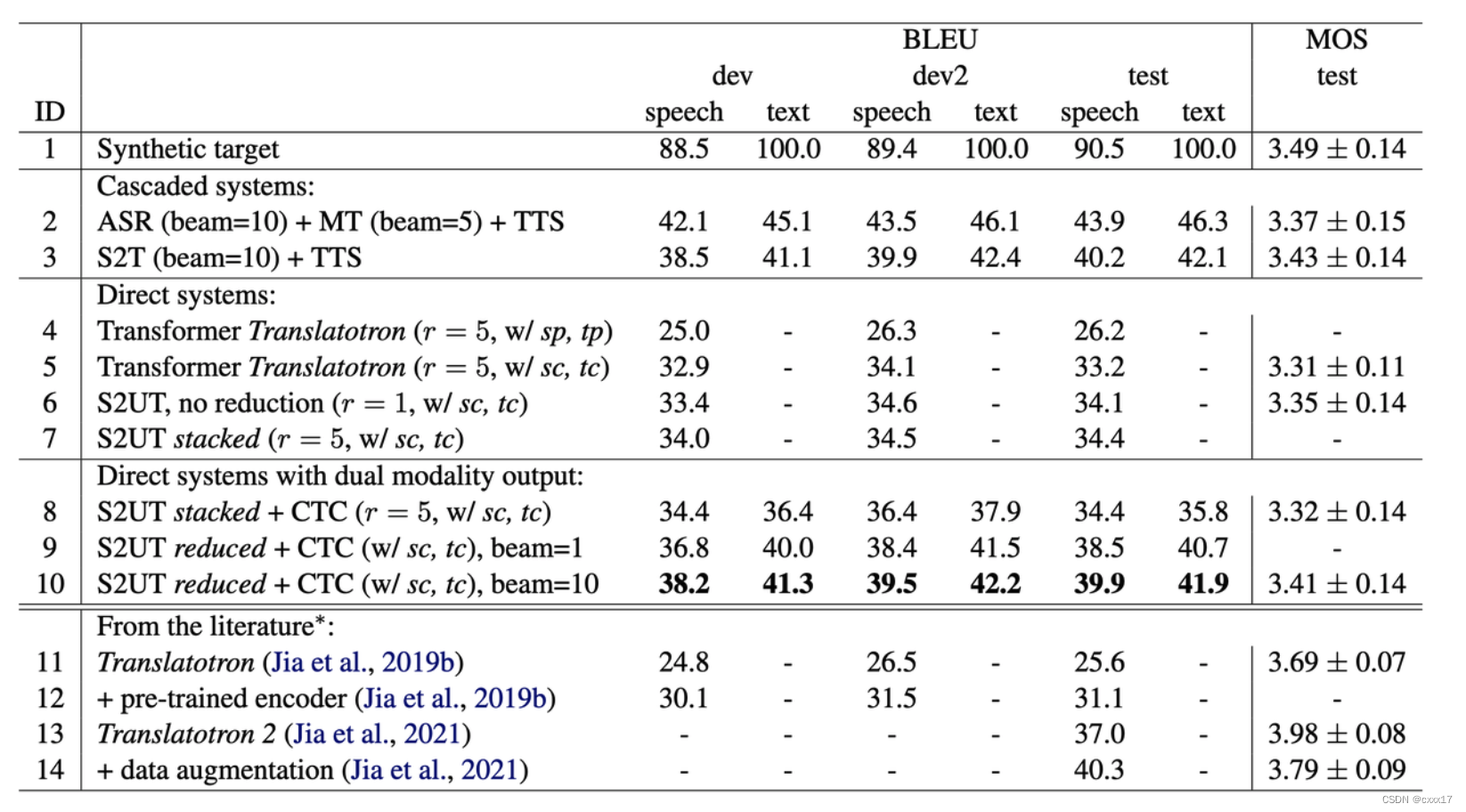
different targets for the auxiliary tasks(4 vs. 5)
character 比 phoneme要好
proposed S2UT model vs transformer Translatotron(5 vs 7)
Discrete units are easier to learn. 6 vs 7 means r=5 doesn’t hurt the performance.
incorporate target text CTC decoding to the S2UT model
With dual modality, the bleu improved, increase the beam size, the bleu can increase more.
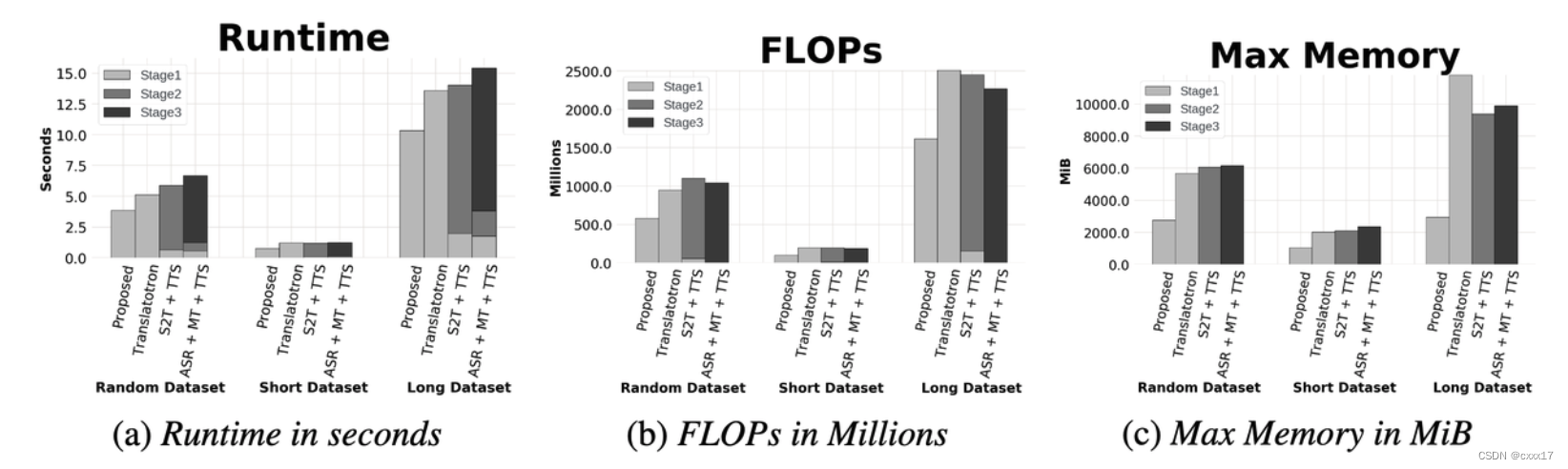
System benchmark















 896
896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









