







03dataFrame的索引
pandas取行或者列的注意点:
方括号里写数组,表示取行,对行进行操作
方括号里写字符串,表示取列的索引,对列进行操作
pandas取行:df[:2]
pandas取列:df[“age”]
pandas排序:df.sort_values(by=‘tel’)
对于一些同时取多行多列的操作,采用*loc和iloc
df.loc与df.iloc的区别:loc通过标签获取行数据;iloc通过位置索引获取行数据
缺损值判断:
处理方式:
1.删除:df.dropna(axis=0)#只要是nan就删除哪一行
2.填充df.fillna(df.mean())
#只填充某一列
df[‘age’].fillna(df[‘age’].mean())
对全0项先赋nan然后再作处理
df[df==0]=np.nan
其他注意事项:
df[‘info’].str.split(’/’).tolist()#info中的字符串(str)用/分离

import pandas as pd
t = [{'name':'xiaoming','age':12,'tel':10010},{'name':'xiaoyue','tel':10086},{'name':'xiaogang','age':32}]
t
[{‘age’: 12, ‘name’: ‘xiaoming’, ‘tel’: 10010},
{‘name’: ‘xiaoyue’, ‘tel’: 10086},
{‘age’: 32, ‘name’: ‘xiaogang’}]
df = pd.DataFrame(t)
df
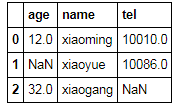
df[:2]
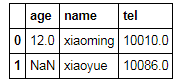
df[:2]['age']
0 12.0
1 NaN
Name: age, dtype: float64
df['age']
0 12.0
1 NaN
2 32.0
Name: age, dtype: float64
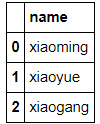
df[['name']]
type(df['age'])#一维series
pandas.core.series.Series
type(df[['name']]) #二维DataFrame
pandas.core.frame.DataFrame
关于dataframe:
只有一列是Series
多列是DataFrame
对于一些同时取多行多列的操作,采用loc和iloc:

import numpy as np
import pandas as pd
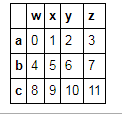
t3 = pd.DataFrame(np.arange(12).reshape(3,4),index=list('abc'),columns=list('wxyz'))
t3
t3.loc['a','z'] #取a行,z列的数据
3
type(t3.loc['a','z'])
numpy.int32
t3.loc['a']
w 0
x 1
y 2
z 3
Name: a, dtype: int32
t3.loc[:,'x']#单独的df.loc['w']是没用的,需要有行才行,单独只有列是没用的,会报错
a 1
b 5
c 9
Name: x, dtype: int32
t3.loc['a',:] #与上式效果一样
w 0
x 1
y 2
z 3
Name: a, dtype: int32
t3.loc[:,'y']
a 2
b 6
c 10
Name: y, dtype: int32
type(t3.loc[:,'y'])
pandas.core.series.Series
t3.loc[['a','c']]#取多行
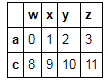
t3.loc[['a','c'],:]#取多行 --与上式效果一样
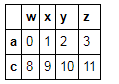
t3.loc[:,['x','y']]#取多列
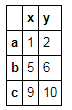
t3.loc[['a','b'],['w','y']]#取多行多列
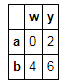

t3.iloc[1,:]#取第一行
w 4
x 5
y 6
z 7
Name: b, dtype: int32
t3.iloc[:,2]#取第2列
a 2
b 6
c 10
Name: y, dtype: int32
t3
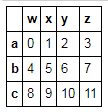
t3.iloc[:,[2,1]]#取第2,1列,并按将第2列排在前面
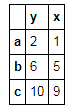
t3.iloc[[1,2],[2,1]]#取多行多列
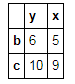
t3.iloc[1:,:2]
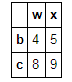
t3.iloc[1:,:2]=30
t3
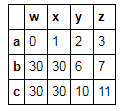
t3.iloc[1:,:2] = np.nan
t3
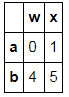
d
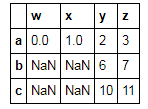
注意 df.loc和df.iloc的另一个区别:
t3
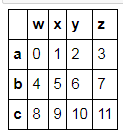
t3.loc[:'c',:'y'] #包括了c行和y列
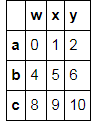
t3.iloc[:2,:2]
04bool索引和缺失数据的处理


import numpy as np
import pandas as pd
t = np.arange(500,1000,20).reshape(5,5)
t
array([[500, 520, 540, 560, 580],
[600, 620, 640, 660, 680],
[700, 720, 740, 760, 780],
[800, 820, 840, 860, 880],
[900, 920, 940, 960, 980]])
df = pd.DataFrame(t,index = list('abcde'),columns = list('wxyzq'))
df
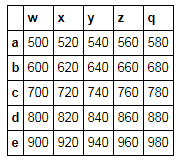
df[(df['w']>700)&(df['y']<900)]
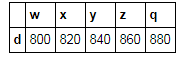
df[(df['w']>700)|(df['y']<600)]
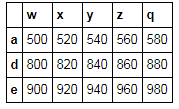
df['info'] =[ '黄荣/爱你/的人/是我/真的啦','黄荣/爱你/的人/是我','黄荣/爱你/的人/','黄荣/爱你/的人','黄荣/爱你']
df
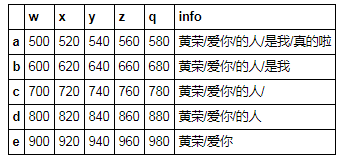
df['info'].str.split('/')
a [黄荣, 爱你, 的人, 是我, 真的啦]
b [黄荣, 爱你, 的人, 是我]
c [黄荣, 爱你, 的人, ]
d [黄荣, 爱你, 的人]
e [黄荣, 爱你]
Name: info, dtype: object
df['info'].str.split('/').tolist()#info中的字符串(str)用/分离
[[‘黄荣’, ‘爱你’, ‘的人’, ‘是我’, ‘真的啦’],
[‘黄荣’, ‘爱你’, ‘的人’, ‘是我’],
[‘黄荣’, ‘爱你’, ‘的人’, ‘’],
[‘黄荣’, ‘爱你’, ‘的人’],
[‘黄荣’, ‘爱你’]]
print(df['info'].str) #是Seris
<pandas.core.strings.StringMethods object at 0x000000000893AC18>
pandas处理缺失值得做法:

import pandas as pd
t = [{'name':'xiaoming','age':12,'tel':10010},{'name':'xiaoyue','tel':10086},{'name':'xiaogang','age':32}]
df = pd.DataFrame(t)
df
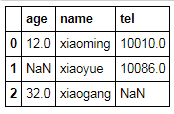
pd.isnull(df)
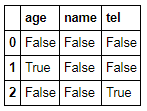
pd.notnull(df)
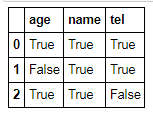
df[pd.notnull(df['age'])] #获得age非0的行
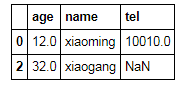
pd.notnull(df['age'])
0 True
1 False
2 True
Name: age, dtype: bool
1.缺损值处理方式1—删除0那一行
df.dropna(axis=0)#只要是nan就删除哪一行
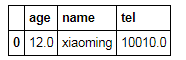
df.dropna(axis=0,how='any')#只要是nan就删除哪一行
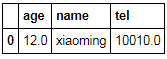
df.dropna(axis=0,how='all')#全部都是nan才删除哪一行
df.dropna(axis=0,how='any',inplace=True)#inplace表示是否更换df内的数值,变更df
df

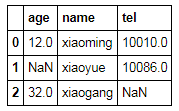
2.处理数据方式2----填充数据
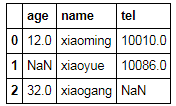
df = pd.DataFrame(t)
df
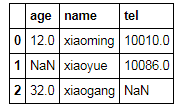
df.fillna(100)
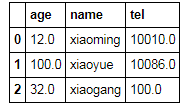
df.fillna(df.mean())
df.mean()
age 22.0
tel 10048.0
dtype: float64
#只填充某一列
df['age'].fillna(df['age'].mean())
0 12.0
1 22.0
2 32.0
Name: age, dtype: float64
df
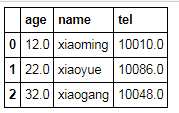
df['age'] = df['age'].fillna(df['age'].mean())
df
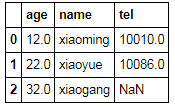
df['age'][1]=np.nan
df
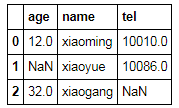
df["age"].mean()
22.0
df['age'][2]=0
df
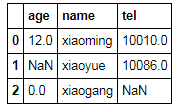
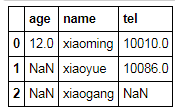
df[df==0]=np.nan
df















 152
152











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









