










1.代码
1.1 源码(拷贝直接使用)
⭐️ 直接拷贝以下代码到模型中使用(已经测试通过,评论区可以讨论)
import keras.backend as K
def my_tp_tn_fp_fn(y_true, y_pred):
true_posi_sum = K.cast(K.sum(y_true), "int32")
true_nag_sum = K.cast(K.sum(y_true-1), "int32")*(-1)
pred_posi_sum = K.sum(K.cast(K.greater(y_pred, 0.5), "int32"))
tp = K.sum(K.cast(K.greater(K.clip(y_true * y_pred, 0.0, 1.0), 0.50), "int32"))
fn = true_posi_sum - tp
fp = pred_posi_sum - tp
tn = true_nag_sum - fp
tp = K.cast(tp, "float32")
tn = K.cast(tn, "float32")
fp = K.cast(fp, "float32")
fn = K.cast(fn, "float32")
return tp, tn, fp, fn
def keras_hanmingloss(y_true, y_pred):
tp, tn, fp, fn = my_tp_tn_fp_fn(y_true, y_pred)
num_wrong = fp + fn
total = tp + tn + fp + fn
hanming_loss = (num_wrong + K.epsilon())/ total
return hanming_loss
1.2 构造思路
⭐️ 0. 流程图
⭐️ 1. 先求出所有的TP、TN、FP、FN
⭐️ 2. 再根据所有的TP、TN、FP、FN结合汉明损失公式构造损失函数
⭐️ 3. 结合Sci-kitlearn库的hanminglossAPI进行验证
1.3 结合sklearn进行验证
⭐️ 自定义代码效果,如下图值为:0.06353355

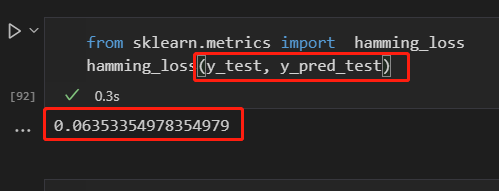
⭐️ sklearn的汉明损失效果,如下图值为:0.06353354978354979(由于前者是float32,所以后者float64精度会更高一些)
1.4 实验效果
⭐️ 训练阶段效果

⭐️ 评估阶段效果

2.汉明损失
2.1 介绍
⭕️ 汉明距离:求解两个 相同尺寸数组 对应位置元素 不相同的个数
⭕️ 汉明损失:汉明距离 除以 数组元素个数
⭕️ 汉明损失实际上就是汉明距离除以元素的总个数
1. 汉明距离是使用在数据传输差错控制编码里面的,汉明距离是一个概念,它表示两个(相同长度)字符串对应位置的
不同字符的数量,我们以d(x,y)表示两个字x,y之间的汉明距离。
2. 对两个字符串进行异或运算,并统计结果为1的个数,那么这个数就是汉明距离。
2.2 公式
⭐️ y ^ \hat y y^ 为预测结果, y y y 为真实结果, y i j y_{ij} yij为第i个元素第j列, i的最大值为n,j的最大值为m,换句话说, y ^ 和 y \hat y和y y^和y 均为 n*m大小的矩阵
H a m m i n g − l o s s ( y , y ^ ) = 1 n ∑ i = 1 n 1 m ∑ j = 1 m 1 ∗ ( y ^ i j ≠ y i j ) Hamming-loss(y, \hat{y}) = \frac{1}{n} \sum_{i=1}^{n} \frac{1}{m} \sum_{j=1}^{m}1*(\hat y_{ij} \neq y_{ij}) Hamming−loss(y,y^)=n1∑i=1nm1∑j=1m1∗(y^ij=yij)
2.3 应用场景
⭐️ 一般应用在多标签分类任务中
⭐️ 一般用作损失函数或者评价函数
3.参考资料
📚 1. CSDN: TP、TN、FP、FN超级详细解析
📚 2. 百度百科: 汉明距离
📚 3. CSDN: 可能是最全的机器学习模型评估指标总结
📚 4. 未知来源: 常用数学符号的 LaTeX 表示方法















 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









