






问题1:Unable to run align_dataset_mtcnn.py getting an attribute error module ‘facenet’ has no attribute ‘store_revision_info’
使用anaconda的环境,将facenet下载保存在本地,也下载lfw数据集,在运行align_dataset_mtcnn.py代码时,正确的填写相关参数,报这么一个错误。这个错误的原因是由于python路径的问题,查看出错代码的位置:
from scipy import misc
import sys
import os
import argparse
import tensorflow as tf
import numpy as np
import facenet
import align.detect_face
import random
from time import sleep
def main(args):
sleep(random.random())
output_dir = os.path.expanduser(args.output_dir)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# Store some git revision info in a text file in the log directory
src_path,_ = os.path.split(os.path.realpath(__file__))
facenet.store_revision_info(src_path, output_dir, ' '.join(sys.argv)) ---------在这个地方出错
dataset = facenet.get_dataset(args.input_dir)
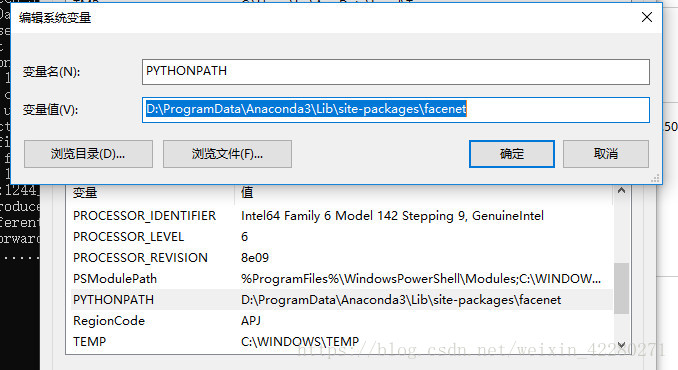
这是github上的源码,这个地方出错,肯定是facenet导入错误。解决办法是将从github上下载的facenet-master文件中src文件夹下所有文件复制粘贴在D:\ProgramData\Anaconda3\Lib\site-packages\facenet下面,当然,因为我是用的anaconda,所以这样做,另外facenet是在D:\ProgramData\Anaconda3\Lib\site-packages下新建的目录。粘贴之后,将这个文件夹下复制到电脑的环境设置中去,大概就是如下图所示:
问题2:W T:\src\github\tensorflow\tensorflow\core\framework\allocator.cc:101] Allocation of 99532800 exceeds 10% of system memory
与问题1相同的环境设置,这是在运行这个代码validate_on_lfw.py,报的错,而且一直持续报错,后来猜想是代码中这个地方有问题:
def parse_arguments(argv):
parser = argparse.ArgumentParser()
parser.add_argument('lfw_dir', type=str,
help='Path to the data directory containing aligned LFW face patches.')
parser.add_argument('--lfw_batch_size', type=int,
help='Number of images to process in a batch in the LFW test set.', default=100)----默认100张图片,内存吃不消
后来将这个参数–lfw_batch_size设置为50,就没有报错了
--------------------9.29号更新--------------------------------------
在运行facenet目录下的contributed中的real_time_face_recognition.py遇到一个小小的问题,就是在导入分类器pickle模型时候出错,编码错误:
UnicodeDecodeError: ‘ascii’ codec can’t decode byte 0x80 in position 1024: ordinal not in range(128)
把源代码修改成如下这样就ok了
def __init__(self):
with open(classifier_model, 'rb') as infile:
self.model, self.class_names = pickle.load(infile,encoding='latin1') ###这个地方的修改主要是python版本不同造成的原因
后续继续更新!
















 6483
6483











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











