






6.4 系统聚类的性质及类的确定
(3)根据统计量确定
上一讲介绍了 R-square,这里再补充 3 个用于确定分类个数的统计量。
- 半偏 R-square:
即 k+1 类的 R-square 减去 k 类的 R-square,其用于衡量 k 类与 k+1 类的 R-square 的增值 。如果半偏 R-square 比较大,说明 k+1 类的 R-square 更大,更合理,因此不应该合并为 k 类。
- 伪 F 统计量:
因为比较像 F 分布的定义,所以称为“伪F”
Bk 是组间平方,我们希望 B_k 比较大,进而当伪 F 统计量的值比较大的时候,认为其效果良好。
- 伪 t2 统计量:
评价将类 K 和类 L 合并的效果。这是半偏 R-square 的变形,同样地,当它比较大的时候,认为 k+1 类更好。
(4)根据谱系图
几个准则:
- 各类重心之间的距离必须很大(各类差异性显著);
- 确定的类中,各类所包含的元素不要很多;
- 类的个数必须符合实用目的;
- 若采用几种不同的聚类方法处理,则在各自的聚类图中应发现相同的类。
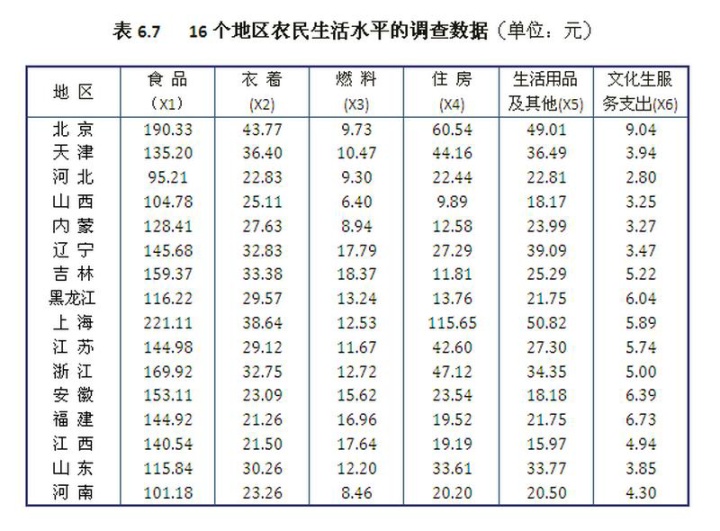
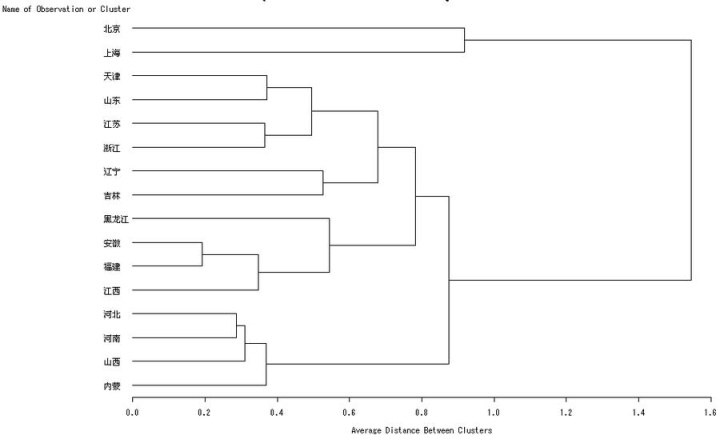
例子-- 16 个地区的聚类
6.5 动态聚类法
当样本量比较大时,系统聚类的计算量很大。
动态聚类法基本思想:首先选取 k 个点,其两两间的距离比较大;由此确定出初始的分类,并评估该分类的好坏,如果不好则调整分类。
流程图如下
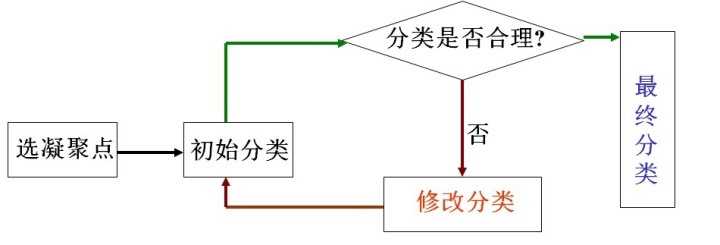
其优点是适用于大样本,计算简单。缺点是依赖于初始的 k 个点。
改进:换一批凝聚点,如果两种分类结果相同,则接受。否则考虑另外的聚类算法。
(一)凝聚点的选取与初始分类的确定
(1)凝聚点选取
人为选择的三种方法:
- 用经验来确定分类数目,并从每一类中挑具有代表性的
- 先人为分成 k 类,然后取每一类的重心
- 确定一个正数 d,首先将所有样本的均值作为凝聚点,如果某样本与现有的凝聚点的距离均大于 d,则加入凝聚点。
密度法确定凝聚点(常用):首先确定半径 d,然后计算以每个样本为中心,半径为 d 的球中样本的数目,称为该样本的密度。
密度越大,说明与该样本接近的样本比较多,适合作为某一类的中心
- 选择密度最大的作为第一凝聚点
- 人为选取 D(常取为 2d),当密度第二大的样本与第一凝聚点的距离大于 D 时,加入作为凝聚点;否则舍去,再考察密度第三大的
- 按密度大小依次考察,直至选择完毕
随机选取(一般不用):如果对样本的性质一无所知,可以随机数生成,或就取前 k 个
(2)初始分类的确定
方法:
- 人为经验确定
- 每个样品归并到与其最近的凝聚点中(可以在归并过程中,将类的重心作为新的凝聚点)
- 极值标准化,令
对每个样品计算
如果这个数最接近整数 l,那么归入第 l 类。
- 用某种聚类方法得到初始分类。样本量大的时候,可以用部分样品聚类,选取每类重心作为凝聚点,然后再将其它样本归到每个类.
(二)逐步聚类法
(1)按批修改法
确定好初始分类后,计算每一类的均值作为新的凝聚点,然后再对所有样本按照“距离最近”原则进行重新分类。
自然地,如果当最后所有的凝聚点都与上一步相同时,停止。(但如果凝聚点始终再变化?)
- 分类函数
定义样品 i 到第 j 类的距离为
分类函数定义为
其中
分类函数就是所有样品到其所属类别的距离之和最小,也就是“ 离差平方和最小”
按批修改的原则是使得分类函数达到最小,直至不能再减小时停止。
例 将 1 4 5 7 11 用按批修改法进行动态聚类
解
- 首先选取凝聚点:
令 d = 2,D = 4,得到各个点的密度为0 1 2 1 0。第一个凝聚点为 5,第二、第三凝聚点分别为 1、11(与第一凝聚点的距离大于 D).
- 得到初始分类:
初始的分类为{1}、{4 5 7}、{11}.
- 修改重心:各类的均值分别为1、16/3、11
- 重新分类:发现结果与上一步相同,停止。
注1:按批修改法的优点是计算量小,速度快,但结果依赖于凝聚点的选择.
注2︰有时并不要求过程收敛,只是人为规定这个修改过程重复若干次就行了.
注3:在按批修改法中,有人将步骤3改为:计算每一类重心,取老凝聚点与重心连线的对称点作为新凝聚点转到步骤2。如果某一步新老凝聚点重合,则过程终止。这样做某些场合会有好的结果.
(2)逐步修改法( K-means)
按批修改:所有点都分好类之后再改
逐步修改:先确定 k 个凝聚点,将其余 n-k 个点逐个分类,并在分类之后用该类的均值作为新的凝聚点。
步骤:
- 定义样品间的距离,认为决定分类数 K,类间距离的最小值 C,类内距离的最大值 R。取前 K 个作为凝聚点
- 计算这 K 个凝聚点两两之间的距离,如果最小距离小于 C,就将其合并为一类,令其重心作为新的凝聚点。不断重复,至所有类间距离都至少为 C.
- 将剩下的 n-K 个样品不断归类,如果某个样品到所有凝聚点的最小距离都大于 R(说明不该分为同一类),则作为新的凝聚点;反之,如果最小距离小于等于 R,则将其归入该类,并用归并后的重心作为新的凝聚点。(此时需要判断所有凝聚点的距离是否大于等于 C,如果有两个凝聚点的距离小于 C,返回上一步迭代)
- 所有样品归类后,得到最终的凝聚点。选取这组凝聚点重新开始迭代,如果结果相同则停止,否则继续迭代。
例 将 1 4 5 7 11 用逐步修改法(K-means)进行动态聚类
解
- 定义距离,确定三个参数:
用欧氏距离,取 K=3,C=2,R=3,用 1 4 5 作为初始凝聚点
- 计算凝聚点两两距离:
发现 4 和 5 的距离为 1,小于给定的 C,因此将其归并为{4,5},取重心 4.5 作为新的凝聚点。此时凝聚点为 1 和 4.5
- 考虑剩下的样品:
首先考虑 7,它与 4.5 接近,且距离为 2.5 小于给定的 R,分到 {4 5} 中。此时凝聚点为 1 和 16/3。然后考虑 11,它到 16/3 的距离更近,但是距离为 17/3,大于给定的 R,应该作为新的凝聚点。
至此分为 {1}、{4 5 7}、{11}三类
- 用最终凝聚点从头开始分类:上一步最后的凝聚点为 1、16/3、11,令为初始凝聚点重复第二第三步,得到相同结果,分类结束。
注1:逐步修改法与考虑样本的顺序有关,如果上面过程在考虑样本时从后往前,那么结果不同。
注2:逐个修改法的最终分类与三个参数有关,因此在计算过程中最好让三个参数适当变化,最后根据实际问题的要求取舍聚类结果。
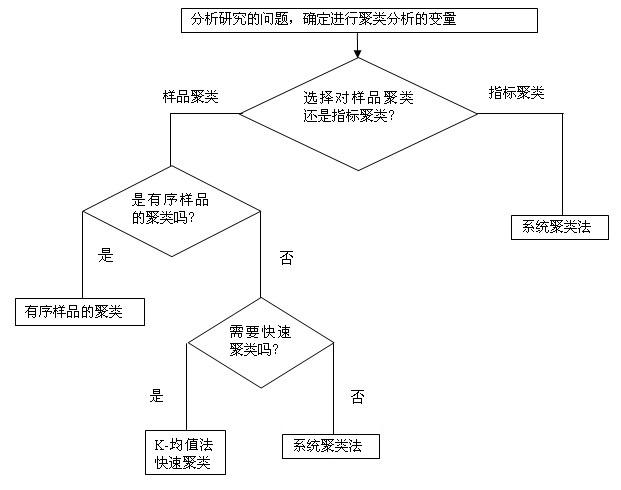
实际分析聚类问题时,考虑按照如下流程图
6.6 有序样品的聚类法(最优分割法)
如果我们的样品有某种顺序,那么在聚类的时候不能打乱这种顺序。例如:① ② ③ ④不能聚类为{① ③}和{② ④}。
实际问题中的有序样品:按照深度划分地层的结构
有序样品聚类问题其实也就是划分问题,要确定的是每一类的起点和中点。
基本思想:一开始分为 1 类,然后分为 2,3 直到 n 类,要求分类后的离差平方和达到最小。
(一)步骤
(1)定义类的直径
常用这一类样品的离差平方和作为这一类的直径:
其中 i 和 j 分别为类 G 的起点和终点。
如果分类分对了,那么每一点与该类的中心的距离不能太大,进而每一类的直径都不会太大,再而所有类的直径之和不会太大
如果样品是一维的,也可以定义直径为
其中
(2)定义分类的损失函数
损失函数就是所有类的离差平方和再加起来。
离差平方和的和
要寻求分点,使得这个损失函数最小。
(3)递推公式
如果是两类,那么只需要确定一个结点 j,这时对 j 从 2 到 n 取遍,计算损失函数的最小值。而考虑分为 3 类时,分为两类的最佳结点 j 可以沿用,此时考察将 1 到 j-1 分为 2类,计算这一部分样本分为两类后的总离差平方和,再加上 j 到 n 部分的离差平方和,得到分为 3 类的损失函数的最小值。
4 类及以上同理。
(4)最优解的求法(递归)
递归一步有
再递归
不断进行下去,最终递归基为二分类问题,二分类用循环暴力找最优结点,然后就可以确定回溯得到多分类的最优结点。
****有时间就编程实现一下****
(二)应用举例
将下面的有序数据进行聚类
- 计算直径D(i,j):
例如 D(1,2) 为 (9.3,1.8) 的离差平方和
得到直径矩阵如下

- 通过递归得到最小损失函数:
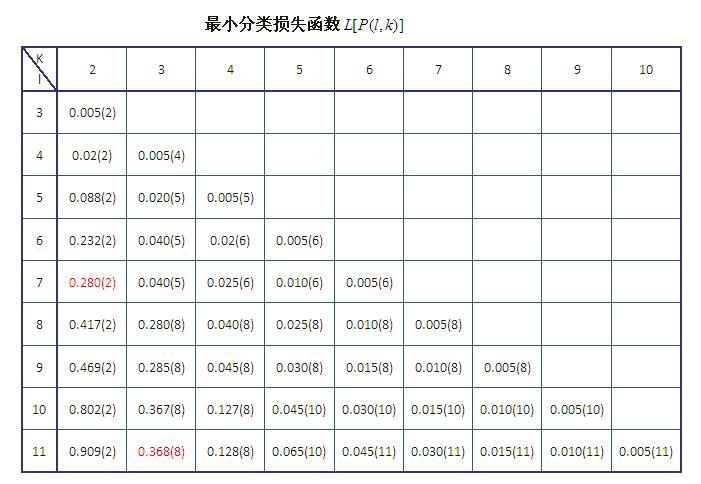
- 决定分类个数:
如果分为 3 类,根据上表,最后的结点为 8,然后再查看 1-7 分为两类的最优结点是 2,所以分为 3 类的结果为{1},{2 3 4 5 6 7},{8 9 10 11}
- 如何确定分类个数?
观察损失函数的最小值随着 k 的变化曲线
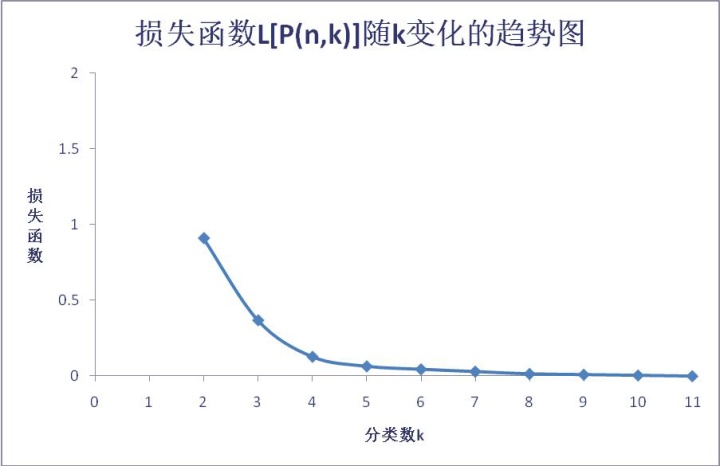
在 k = 3 或 4 处拐弯,取分类个数为 3 或 4 较好。
此外如果曲线比较平缓,没有明显的拐弯点,可采用均方比或特征根法。
6.7 变量聚类方法
前面都是对样本聚类,现在考虑对随机变量来聚类。
(一)变量聚类的系统聚类法
(1)就当样本聚类做
此时数据矩阵作一转置,但这样做没有考虑到变量之间的相似性
(2)相关阵距离
生成变量的相关矩阵,然后用 1-相关矩阵的绝对值 得到变量间的距离矩阵。进而用各种系统聚类方法求解。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









