







To Be Continued..........................
本系列文章目的是分享并记录自己在目标检测领域的个人理解, 内容包括论文翻译和个人分析。纯粹是为了个人学习,不具有参考意义
既然是为了入坑目标检测,那么faster-rcnn系列则是绕不过去的一个点。下面这段话是fasterrcnn论文中对检测任务本质的探讨。
The R-CNN method [5] trains CNNs end-to-end to classify the proposal regions into object categories or background. R-CNN mainly plays as a classifier, and it does not predict object bounds (except for refining by bounding box regression). Its accuracy depends on the performance of the region proposal module (see comparisons in [20]).
RCNN系列主要是训练一个端到端CNN网络对候选区域进行分类(背景或目标类型)。他其实可以看做一个分类器,因为他并没有去预测目标边界。检测精度取决于区域候选模块的表现。作者提出了一个叫做fasterrcnn的检测器,它包括两个模块,一个是用来提出候选区域的深度全卷积网络,另一个是使用提供的候选区域的fast-RCNN检测器。这个RPN其实就类似于attention一样,告诉网络应该朝哪看,哪里可能有object。
RPN输入是任意尺寸的图片,而输出则是一堆矩形框并带有object score.为了和detector部分共享计算,作者使用卷积网络去实现这个模块。为了产生候选区域,作者在feature map 上弄了一个滑动窗口, 每一个窗口映射到低维feature,这个feature然后fed到a box-regression layer (reg) and a box-classification layer (cls).
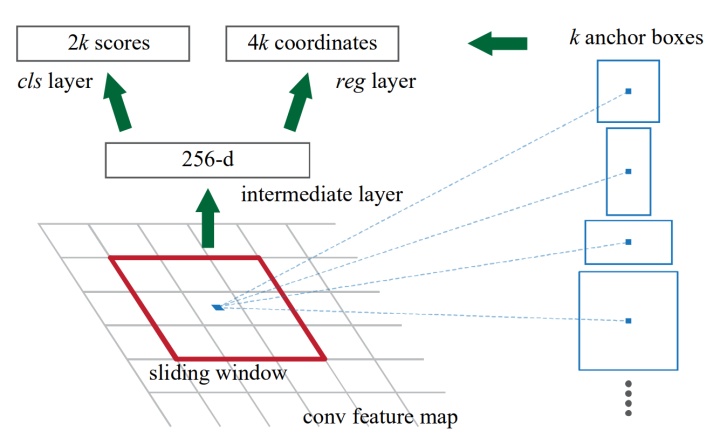
上面这张图特别清晰的展示什么是anchors,在每个窗口的位置,同时预测多个候选区域k,回归层有4k输出(坐标),分类层有2k个probability scores. anchor位于窗口中心,与scale, aspect ratio有关。anchor另外一个重要的性质就是平移不变性,当图片发生旋转的时候,网络依然还能够预测位置。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 875
875











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









