







上大学的时候接触到机器学习就觉得好厉害的样子,竟然可以预测未来即将发生的事请。在成为一名研究生之后幸运地参加了实验室里的集料数据预测方面的研究。作为与实际生产紧密联系的方向,我们实验室的集料研究方向的所有数据均为自己筛分采集存储,自己掌握数据来源才是最可靠的,在数据有问题的时候可以对原始数据进行追溯,排查问题点。以下是我做集料预测方向关于数据质量问题的一点小心得,以记录自己在数据预测方面走过的弯路。
数据为中心or算法为中心
假设我们已经完成了初步的数据分析,模型的性能达到了比较好的效果。但实际使用过程中的预测精度还不足,不能完全满足业务的需要。那么接下来我们可以分析预测错误的结果,在输入数据中寻找可能是异常的数据,或者选择一种更复杂的模型算法。但总的来说,如果不能给模型中输入良好的输入数据,那即便采用更先进的机器学习算法,也不会产生太好的效果。因此我们要将更多的目光放在数据的质量上。
数据质量提升
缺失值
缺失值是我们在处理数据时常见的一种可能导致数据预测精度不高的数据问题。
有缺失值的数据不仅可能导致模型效果差,还可能直接导致模型训练失败。
缺失值会使系统丢失大量有用信息、可能是系统中所表现出的不确定性更加显著、可能数据分析挖掘过程陷入混乱、导致不可靠输出、还有可能导致模型训练失败。

可以使用非常简单的一行代码来检查数据中是否有空值
data.isnull()
- 1
或者使用
data.info()
- 1
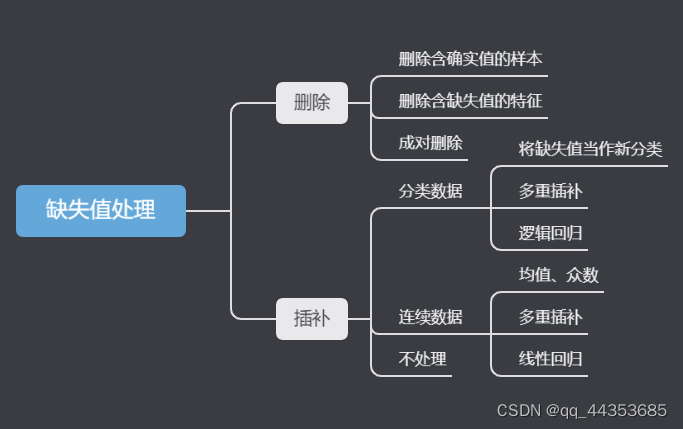
处理的方法也有很多比如直接删除、插补、或者不处理。
1.直接删除
直接删除是比较直接的处理缺失值的办法其优点是简单易行,在对象有多个属性缺失值、被删除的含缺失值的对象与初始数据集的数据量相比较小的情况下非常有效。缺点是当缺失数据所占比例较大,特别当遗漏数据非随机分布时,这种方法可能导致数据发生偏离,从而引出错误的结论。
总结就是直接删除方法只适合少量、随机的缺失值处理。其他情况就得使用接下来的这种方法了
2.插值法
平均值填充
对初始数据集中的数值型缺失值,就可以根据该属性在其他所有对象的取值的平均值来填充该缺失的属性值。如果是非数值型的缺失数据则使用该属性在其他所有对象的取值次数最多的值(即出现频率最高的值)来补齐该缺失的属性值。
热卡填充(就近补齐)
对一个,热卡填充法在完整数据中找到一个与它最相似的对象,然后用这个相似对象的值来进行填充。不同的问题可能会选用不同的标准来对相似进行判定。该方法概念上很简单,且利用了数据间的关系来进行空值估计。这个方法的缺点在于难以定义相似标准,主观因素较多。
回归
基于完整的数据集,建立回归方程,或利用机器学习中的回归算法。对于包含空值的对象,将已知属性值代入方程来估计未知属性值,以此估计值来进行填充。当变量不是线性相关时会导致有偏差的估计。这种方法比较常用,缺失值补充也较合理。但必须要注意的一点是防止回归模型过拟合,过拟合后的回归填充数据对模型预测并不是一件好事。
3.不处理缺失值
可以使用贝叶斯网络或者人工神经网络直接在包含缺失值的数据上进行数据分析
贝叶斯网络提供了一种自然的表示变量间因果信息的方法,用来发现数据间的潜在关系。在这个网络中,用节点表示变量,有向边表示变量间的依赖关系。贝叶斯网络仅适合于对领域知识具有一定了解的情况,至少对变量间的依赖关系较清楚的情况。否则直接从数据中学习贝叶斯网的结构不但复杂性较高(随着变量的增加,指数级增加),网络维护代价昂贵,而且它的估计参数较多,为系统带来了高方差,影响了它的预测精度。
当然了缺失值处理的方法还有很多
上面说到的是我自己比较常用到的,大家有详细的需求可以自己再查阅其他方法的详细资料。
异常值处理
异常值也是我在处理数据的时候碰到的一个大麻烦。首先在异常值的确定上就犯难了,那些离群值还好判断但”离群“不是那么远的呢,要不要算作异常值呢?所以,异常值有时候并不像缺失值那样明显。下面介绍两种我常用的异常值检测方法。
什么是异常值?异常值是指那些数据集中存在的不合理的值,此处的不合理指的是偏离正常范围的值而不是错误值,如一颗集料的重量为1kg、外接矩形的边长为1m等。
为什么会出现异常值?数据集中的异常值可能是由于传感器故障、人工录入错误或异常事件导致。使用线性回归模型、K均值聚类建模时可能得到错误结论。
1.箱线图
箱线图是通过数据集的四分位数形成的图形化描述,是非常简单而且效的可视化离群点的一种方法。是我比较常用的一种方法
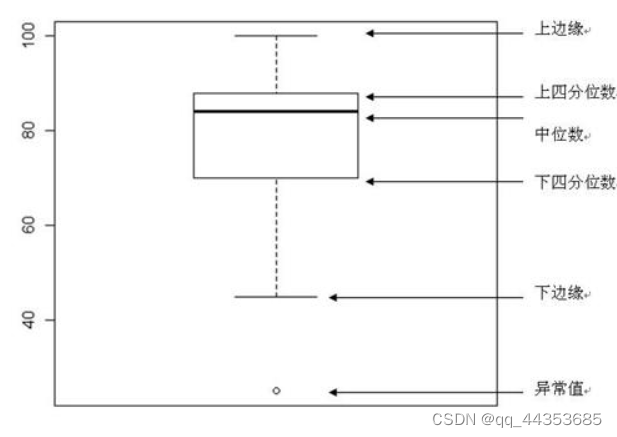
上下边缘为数据分布的边界,只要是高于上边缘,或者是低于下边缘的数据点都可以认为是离群点或异常值。
下四分位数:25%分位点所对应的值(Q1)、中位数:50%分位点对应的值(Q2)、上四分位数:75%分位点所对应的值(Q3)、上边缘:Q3+1.5(Q3-Q1)、下边缘:Q1-1.5(Q3-Q1)。Q3-Q1表示四分位差。
使用excel就可以很简单的绘制出箱线图,找到异常值进行处理后就可以进行测试,看看效果有没有提升了。
2.基于树的方法-孤立森林
顾名思义,孤立森林就是通过树的方法将异常值“孤立”出来。
大概原理是:首先,我们用一个随机的平面对数据空间一分为二,生成两个子空间。然后再使用随机平面对上面得到的两个子空间,进行分割。如此循环直到每个子空间内都只包含一个数据为止。那些比较集中的数据需要被切割好多此才会停止切割,而异常值在分布上比较稀疏,所以会比较早的被分割到一个只包含它的数据空间。转换到树的生成上就是异常值能更早的被划分到子结点上。
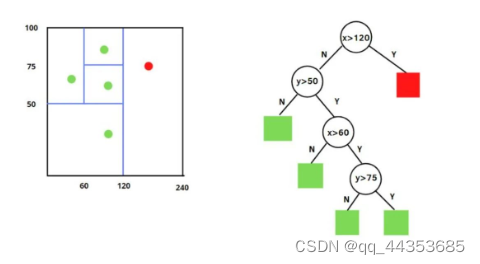
上图中红色的点为孤立森林判断出的异常值。
数据的重要性就相当于修房子时的地基,只有处理好数据这个地基,机器学习模型的房子才建的牢靠。那关于数据质量的话题就说到这里啦。上面只是根据介绍了不多的几种数据质量改善的方法,还有很多的机器学习数据质量提升的方法等着大家去探索,让我们一起加油吧!
注:本篇博客内容由团队硕士生发表,欢迎交流指导,联系方式:1601889033@qq.com














 4253
4253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









