







- RL背景
强化学习解决定义在马尔科夫过程(Makov Decision Processing, MDP)下的连续决策问题。 其中经典算法Q-learning使用如下方程更新
2. RL面临的挑战: 奖励稀疏性(sparse reward )
大部分任务的state-action空间中,奖励信号都为0. 我们称之为奖励函数的稀疏(sparsity of reward)。 稀疏的奖励函数,导致算法收敛缓慢。 Agent需要和环境多次交互采并学习大量样本才能,收敛到最优解.
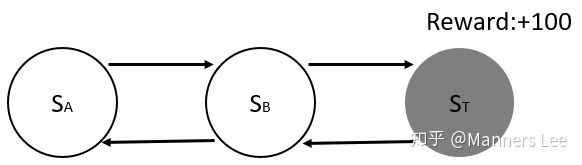
如上图MDP, Agent 从状态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1056
1056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









