







1 基本原则
- 可观赏性,代码要求结构清晰,整齐,整体层次分明;
- 可读性,代码在合适的位置需要添加必要的注释;
- 风格统一性,代码上下文要求风格统一,不允许多种风格糅合在一起;
- 命名规范性,表和字段的命名严格遵守数据仓库分层规范
2 命名规范
2.1 通用规范
- 表名、字段名采用一个下划线分隔词根(示例:clienttype->client_type);
- 每部分使用小写英文单词,属于通用字段的必须满足通用字段信息的定义,禁止使用中文拼音;
- 表名、字段名需以字母为开头;
- 表名、字段名最长不超过64个英文字符;
- 字段名禁止使用关键字
- 在表名业务含义部分禁止使用非标准的缩写
2.2 数据表命名
【推荐】表名称 = [数仓分层][业务主题][子主题][表含义][存储格式][更新频率][后缀]
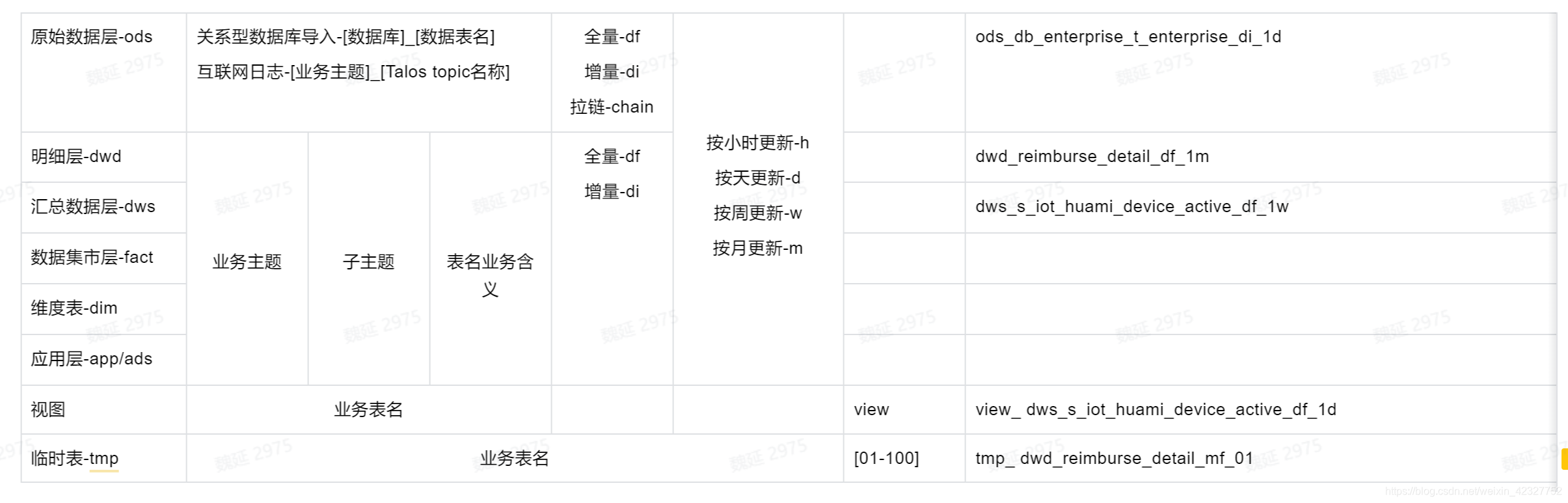
思考:视图使用场景,什么层的使用视图?
2.3 表字段命名
- 【强制】相同业务含义的字段(维度、事实字段、指标度量)在不同的主题,不同事实表,不同的维度表中必须使用同一个字段名称(例如:地址维度不允许既命名为address,又命名为location);
- 【推荐】字段命名优先参考数仓标准配置中的词根管理,词根参考
https://wiki.n.miui.com/pages/viewpage.action?pageId=402282034
3 建表规范
- 表的数据类型不允许全用string,不便于暴露问题和排查问题,合理使用bigint,decimal等数据类型;
- 所有分层的表必须有表级别的注释,建议DW层表有字段级别的注释;
- 所有建表语句需保存为sql或者hql格式文件,并保存到git;
- 【建议】hive表存储格式,除了文件导入用textfile;其他数据表统一使用parquet格式
- kudu表必须指定主键,且有分区字段
- hive表分区字段
- 按天,月分区,分别是date,month,且格式为20200727, 202007, bigint类型
- 按其他业务分区,string类型
- 尽量不出现3级或3级以上分区
- hive分区表增加字段或者修改字段类型时,末尾添加cascade关键字,这样能同时更新表和分区的元数据信息【hive里执行】
4 编码规范
-
【推荐】使用with语句,代替嵌套子查询;
-
【强制】禁止使用SELECT *;
-
【推荐】SQL关键字统一大写或者小写,禁止大小写混用,前后不一致使用;
-
【推荐】使用缩进,使代码结构化,缩进默认使用4个空格;可以将tab键设置为4个空格。

-
规范合理使用换行。
-
【推荐】SELECT、FROM、WHERE、GROUP BY、HAVING、LATERAL VIEW、JOIN关键字必须换行;
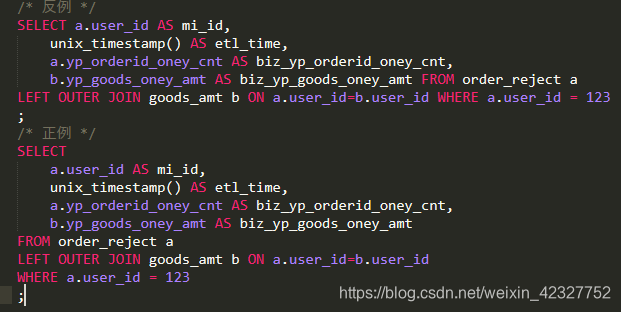
-
【推荐】SELECT多个字段时,字段之间必须换行,且逗号统一放置在字段首端或者末端;推荐放在字段前面,便于排查未加逗号或多加逗号的报错;
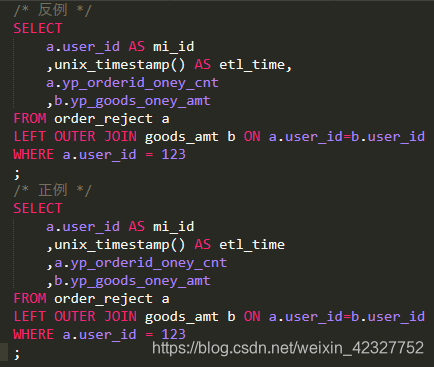
-
【推荐】WITH结构 AS关键字后必须换行
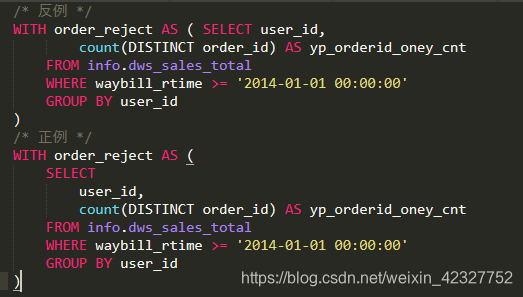
-
【推荐】WITH语句2个代码块间建议添加空行
-
-
规范合理使用空格。
- 【推荐】逻辑运算符两侧建议使用空格;
- 【推荐】逗号后建议添加空格,例如:group by、partition by后多个字段时
-
规范正确使用别名
-
【强制】JOIN操作时,主表和关联的表必须使用别名,且长度不宜过长。获取字段时统一使用别名获取,禁止混合使用;
-
【强制】WITH语句中临时表名必须使用有业务含义的名称,禁止使用a,b,a1,a2等;
-
【强制】字段如需要使用别名,字段与别名之间必须使用AS关键字;
-
【强制】嵌套查询里,外层禁止使用内层表的别名,建议使用不同的别名,增加可读性
-
-
【强制】两表关联时建议使用JOIN关键字,不推荐使用
select c1,c2 from table1 t1, table2 t2 where t1.j1=t2.j1
5 工程规范
- ETL脚本独占一个文件,以.sql结尾
- 在关键逻辑处添加必要注释,格式 /* 这里是注释 */, 且独占一行
- 一个脚本文件一般对应一张数据表的生成,不建议一个文件生成多张表的数据
- 脚本结尾必须增加分号,且分号独占一行。Note1
- 若脚本有参数,参数名称必须大写,如${hiveconf:EXEC_DATE}
6 SQL最佳实践
6.1 SQL调优
- 禁止distinct *。
- 全量分区表必须添加分区字段过滤条件。
- 避免使用IN和NOT IN子查询。使用JOIN代替,或者使用EXISTS 或 NOT EXISTS 代替。在spark sql执行时,in和not in会被优化器处理成broadcast。
- join后必须添加join条件,且请避免使用OR,如果必须使用OR,请关联2次,再UNION。
- 如果某部分逻辑被重复使用,且数据集不大,可以使用cache table。sql结尾必须uncache table。
- 在join查询中,因左表的条件会下推,而右表不会,所以where条件里不允许增加右表的过滤条件Note2。一般2种处理方式:
- 预处理这部分数据
- 将条件写到on子句里
- 对于join查询和group by多个字段,提前探索数据
- 一是避免笛卡尔积,不必要的资源浪费
- 二是检查是否有数据倾斜,数据倾斜的数据请特殊处理
- 对于join、group by和where的字段,避免在字段上做函数操作
正例:where create_time > unix_timestamp()
反例:where from_unixtime(create_time, ‘yyyy-MM-dd’) > now() - 合并小文件,写入表时末尾添加 distribute by cast (rand() * 10 as int)。
- SQL bad case整理
附录
-
Note1:一个隐藏的bug,参见
https://issues.apache.org/jira/browse/SPARK-31955
https://issues.apache.org/jira/browse/HIVE-10541 -
Note2:一个前提是用户不是需要在结果集上过滤这部分数据
-
规范持续补充中,规范是根据过往的经验和其他互联网企业的分享再结合小米的现状总结而来,如果大家对规范有疑义,欢迎大家批评指正。
















 2993
2993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











