









简介
TinyBERT是知识蒸馏的一种模型,于2020年由华为和华中科技大学来拟合提出。
常见的模型压缩技术主要分为:
- 量化
- 权重减枝
- 知识蒸馏
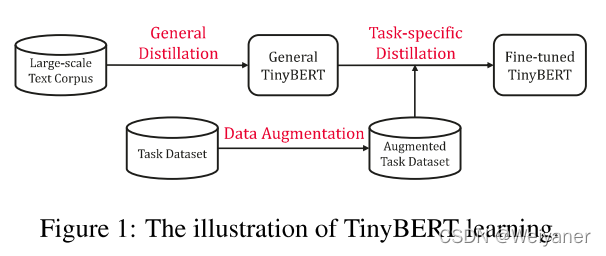
为了加快推理速度并减小模型大小,同时又保持精度,Tinybert首先提出了一种新颖的transformer蒸馏方法,引入了一个新的两阶段蒸馏框架,如下图:
Transformer蒸馏方法用来提取BERTteacher中嵌入的知识。具体来说,设计了三种类型的损失函数,以适应BERT层的不同表示形式:
- 1)嵌入层的输出;
- 2)源自Transformer层的隐藏状态和注意力矩阵;
- 3)预测层输出的logits。
性能表现:在GLUE基准测试中, 具有4层TinyBERT效果,达到BERTBASE的性能96.8%以上,而推理速度则快7.5倍至9.4倍。
Transformer 蒸馏
问题表述:
假设student模型具有M个Transformer层,teacher模型具有N个Transformer层。
我们首先从teacher模型的N个层中选择M个,以进行Transformer层蒸馏。然后将函数n = g(m)定义为从student层到teacher层的索引之间的映射函数,这意味着第m层student模型从第g(m)层teacher模型中学习信息。
准确地说,我们将0设为嵌入层的索引,将M +1设为预测层的索引,并将相应的层映射定义为0 = g(0)和N +1 = g(M + 1 )。在实验部分研究了选择不同映射函数对性能的影响。正式地,student可以通过最小化以下目标从teacher那里获得知识:
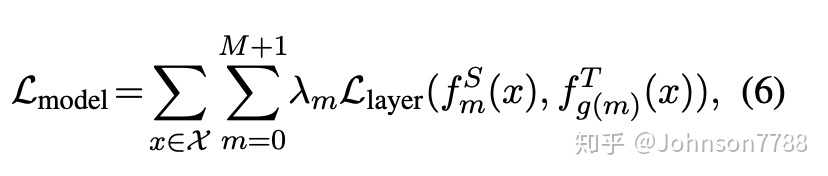
其中
L
l
a
y
e
r
L_layer
Llayer表示给定模型层(例如,transformer层或嵌入层)的损失函数,fm(x)表示从第m层导出的行为函数,而λm是表示第m层蒸馏的重要性的超参数层。
Transformer层蒸馏主要包括注意力attn的蒸馏和隐藏层hidn的蒸馏
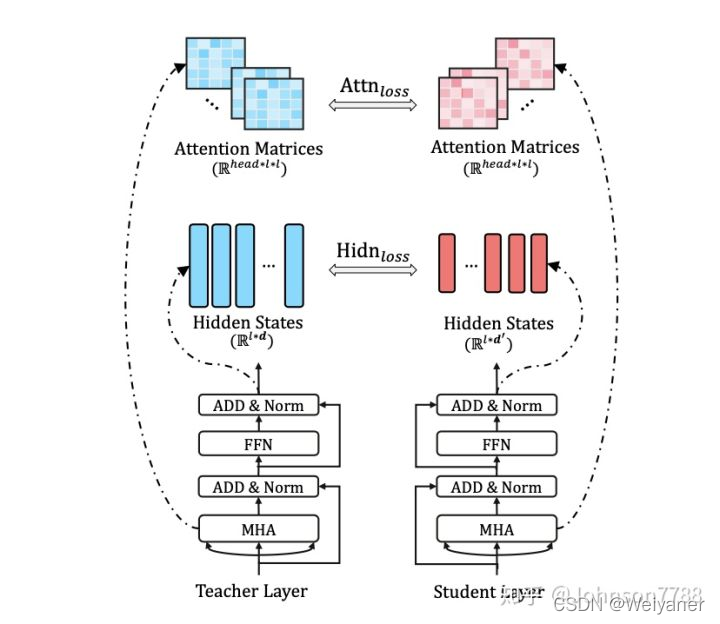
基于注意力的蒸馏
BERT学习的注意力权重可以捕获丰富的语言知识(Clark等。2019)。这种语言知识包括语法和相关信息,这对于自然语言理解至关重要。提出了基于注意力的蒸馏,以鼓励语言知识可以从teacher(BERT)转移到student。具体来说,student学习在teacher网络中拟合多头注意力矩阵,目标定义为:
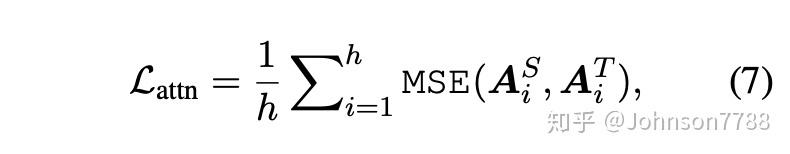
其中h是注意力头的数量,Ai∈Rl×l表示对应于第i个teacher或student的头注意力矩阵,MSE()表示均方误差损失函数。
在这项工作中,非归一化的注意力矩阵Ai被用作拟合目标,而不是其softmax输出softmax(Ai),因为我们的实验表明,前一种设置具有更快的收敛速度和更好的性能。
基于隐藏状态的蒸馏
对隐层的输出进行蒸馏:
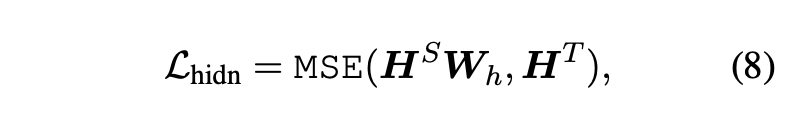
其中矩阵HS ∈ Rl×d和HT ∈ Rl×d分别指代student和teacher网络的隐藏状态,它们由transformer的前馈神经网络(FNN)计算得出。标量值d和d’表示teacher和student模型的hidden size。并且d’通常小于d,以获得较小的student网络。矩阵Wh∈Rd’×d是可学习的线性变换,它将student网络的隐藏状态转换为与teacher网络的状态相同的空间。
还有对嵌入层进行蒸馏,类似于隐含状态:
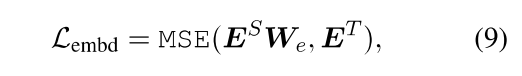
其中矩阵ES和HT分别指的是student和teacher网络的嵌入。在本文中,它们具有与隐藏状态矩阵相同的形状。矩阵We是线性变换,起着与Wh相似的作用
预测层蒸馏
和之前的知识蒸馏思路一样,针对预测输出层进行蒸馏,拟合教师模型的输出,惩罚了student网络的logits与teacher logits信息之间的软交叉熵损失:

其中zS和zT分别是student和teacher预测的logits向量,CE表示交叉熵损失,t表示温度值。在我们的实验中,我们发现t = 1表现良好
使用以上蒸馏目标(即方程式7、8、9和10),我们可以统一teacher和student网络之间相应层的蒸馏损失:
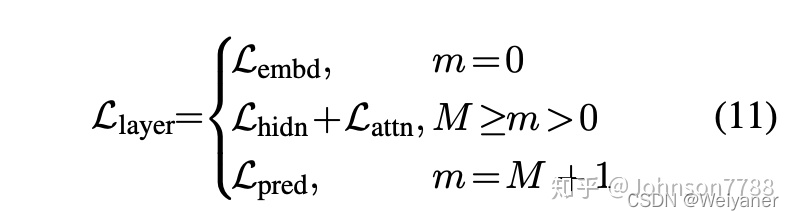
TinyBERT学习
在bert的应用中,通常分为预训练和微调。在这里,也分成两个阶段,通用蒸馏和特定任务蒸馏。
General Distillation
针对通用bert预训练模型进行蒸馏,得到通用的tinybert,通用形式蒸馏帮助TinyBERT学习预训练BERT中嵌入的丰富知识,这在改进TinyBERT的泛化能力中起着重要作用。
在原始的BERT,作为teacher model,并使用大型文本语料库作为训练数据。通过对来自一般领域的文本执行Transformer蒸馏,我们获得了可以针对下游任务进行微调的常规TinyBERT。
然而,由于隐藏/嵌入大小和层数的显着减少,一般TinyBERT的性能通常比BERT差。
TinyBERT在预训练阶段主要学习BERT的中间结构。从我们的初步实验中,我们还发现,在已经进行了transformer层蒸馏(Attn和Hidn蒸馏)和嵌入层蒸馏的情况下,在预训练阶段进行预测层蒸馏不会对下游任务带来额外的改进。
Data Augmentation
主要基于BERT微调模型以及词向量(文中选择的Glove词向量)进行词级别的替换,实现数据增强。
在官方代码中进行了17( N α N_\alpha Nα)倍的增强,以GLUE/QQP数据集为例效果如下:
id qid1 qid2 question1 question2 is_duplicate
402555 536040 536041 how do i control my 40-something emotions ? How do you control your horniness? 1
402555 536040 536041 but do i control my horny brain ? How do you control your horniness? 1
402555 536040 536041 way do i control my horny urges ? How do you control your horniness? 1
402555 536040 536041 when do i control my horny emotions ? How do you control your horniness? 1
402555 536040 536041 how do i suppress my rubbery self ? How do you control your horniness? 1
402555 536040 536041 how do i control my horny emotions ? How do you control your horniness? 1
402555 536040 536041 how do i contain my ornery emotions ? How do you control your horniness? 1
402555 536040 536041 how do i controls my tipsy self ? How do you control your horniness? 1
402555 536040 536041 and do i control my horny emotions ? How do you control your horniness? 1
402555 536040 536041 and do i control my horny emotions ? How do you control your horniness? 1
402555 536040 536041 and do i control my horny emotions ? so do you control your horniness ? 1
402555 536040 536041 and do i control my horny emotions ? what do you control your horniness ? 1
402555 536040 536041 and do i control my horny emotions ? why do you control your horniness ? 1
402555 536040 536041 and do i control my horny emotions ? how do you hide your horniness ? 1
402555 536040 536041 and do i control my horny emotions ? how do you tame your horniness ? 1
402555 536040 536041 and do i control my horny emotions ? """ do you control your horniness ?" 1
402555 536040 536041 and do i control my horny emotions ? how do you control your horniness ? 1
数据增强算法:

在以上算法中,核心主要分为两步:
- 对于single_piece word
如果x[i]是single_piece word,标记为{MASK],通过bert预训练模型预测该词,取概率最大的前k个词,放进C - 对于一般的word
通过Glove计算词向量相似性,找到距离最近的k个词,放进C - 对于C,随机一个概率p(0,1)。如果大于阈值pt,则从C中随机取一个词替换x[i],进而得到增强后的句子。
Task-specific Distillation
在特定任务的蒸馏中,我们在增强的特定任务的数据集上重新执行提议的Transformer蒸馏。
具体来说,使用微调的BERT作为teacher,并提出了一种数据扩充方法来扩展特定任务的训练集。通过训练更多与任务相关的样本,可以进一步提高student模型的泛化能力。
这里主要分为两个步骤,分别是transformer层蒸馏和输出预测层蒸馏。
任务1:中间层蒸馏
python task_distill.py --teacher_model /data/models/pytorch_models/bert_based_uncased_pytorch/ \
--student_model /data/models/pytorch_models/TinyBERT_4L_en \
--data_dir /data/datasets/glue_data/QQP \
--task_name 'QQP' \
--output_dir TMP_TINYBERT_DIR \
--max_seq_length 128 \
--train_batch_size 64 \
--num_train_epochs 2 \
--eval_step 500 \
--aug_train \
--do_lower_case
任务2:预测层蒸馏
python task_distill.py --pred_distill \
--teacher_model /data/models/pytorch_models/bert_based_uncased_pytorch/ \
--student_model TMP_TINYBERT_DIR/QQP/03300837/ \
--data_dir /data/datasets/glue_data/QQP \
--task_name 'QQP' \
--output_dir TINYBERT_DIR \
--do_lower_case \
--aug_train \ # 采用增强后的训练集
--learning_rate 3e-5 \
--num_train_epochs 3 \
--eval_step 1000 \ # 每隔1000进行验证集
--max_seq_length 128 \
--train_batch_size 32















 3919
3919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











