









python学习中
Python入门
本章将简单地介绍一下Python,看一下它的使用方法。
Python是什么
python的好处:
- 在需要处理大规模数据或者要求快速响应的情况下,使用Python可以稳妥地完成;
- 再者,在科学领域,特别是在机器学习、数据科学领域, Python也被
大量使用。 Python除了高性能之外,凭借着 NumPy、 SciPy等优秀的数
值计算、统计分析库,在数据科学领域占有不可动摇的地位。深度学习的
框架中也有很多使用Python的场景,比如Caffe、 TensorFlow、 Chainer、
Theano等著名的深度学习框架都提供了Python接口。因此,学习Python
对使用深度学习框架大有益处。
综上, Python是最适合数据科学领域的编程语言。
Python的安装
Python版本
Python有Python 2.x和Python 3.x两个版本,这是因为两个版本之间没有兼容性(严格地讲,是没有“向后兼容性”),也就是说,会发生用Python 3.x写的代码不能被Python 2.x执行的情况。
使用的外部库
书的目标是从零开始实现深度学习。因此,除了NumPy库和Matplotlib库之外,我们极力避免使用外部库。之所以使用这两个库,是因为它们可以有效地促进深度学习的实现。
-
NumPy是用于数值计算的库,提供了很多高级的数学算法和便利的数 组(矩阵)操作方法。本书中将使用这些便利的方法来有效地促进深度学习的实现。
-
Matplotlib是用来画图的库。使用Matplotlib能将实验结果可视化,并 在视觉上确认深度学习运行期间的数据。
本书将使用下列编程语言和库。
• Python 3.x(2016年8月时的最新版本是3.5)
• NumPy
• Matplotlib
Anaconda发行版
Python的安装方法有很多种,本书推荐使用Anaconda这个发行版。Anaconda是一个侧重
于数据分析的发行版,前面说的NumPy、 Matplotlib等有助于数据分析的库都包含在其中 A。
Python解释器
Python的版本:python --version(输出版本信息)
输入 python,启动Python解释器。
Python解释器也被称为“对话模式”,用户能够以和Python对话的方式进行编程。比如,当用户询问“1 + 2等于几?”的时候, Python解释器会回答“3”,所谓对话模式,就是指这样的交互。
算术计算
加法或乘法等算术计算,可按如下方式进行:
**>>> 1 - 2
-1**
**>>> 4 * 5
20**
*表示乘法, /表示除法, 表示乘方(32是 3 的 2 次方)。另外,在Python 2.x中,整数除以整数的结果是整数,比如, 7 ÷ 5的结果是1。但在Python 3.x中,整数除以整数的结果是小数(浮点数)。
数据类型
编程中有数据类型(data type)这一概念。数据类型表示数据的性质,有整数、小数、字符串等类型。 Python中的 type()函数可以用来查看数据类型:
**>>> type(10)
<class 'int'>**
**>>> type(2.718)
<class 'float'>**
根据上面的结果可知, 10是 int类型(整型), 2.718是 float类型(浮点型)。
变量
可以使用 x或 y等字母定义变量(variable)。此外,可以使用变量进行计算,也可以对变量赋值。
**>>> x = 10 # 初始化
**>>> print(x) # 输出x
10****
**>>> x = 100 # 赋值
**>>> print(x)
100****
Python是属于“动态类型语言”的编程语言,所谓动态,是指变量的类型是根据情况自动决定的。
另外,“#”是注释的意思,它后面的文字会被Python忽略。
列表
除了单一的数值,还可以用列表(数组)汇总数据。
>>> a = [1, 2, 3, 4, 5] # 生成列表
>>> print(a) # 输出列表的内容
[1, 2, 3, 4, 5]
>>> len(a) # 获取列表的长度
5
>>> a[0] # 访问第一个元素的值
1
>>> a[4]
5
>>> a[4] = 99 # 赋值
>>> print(a)
[1, 2, 3, 4, 99]
元素的访问是通过 a[0]这样的方式进行的。 []中的数字称为索引(下标),索引从 0开始(索引 0对应第一个元素)。此外, Python的列表提供了切片(slicing)这一便捷的标记法。使用切片不仅可以访问某个值,还可以访问列表的子列表(部分列表)。
>>> print(a)
[1, 2, 3, 4, 99]
>>> a[0:2] # 获取索引为0到2(不包括2!)的元素
[1, 2]
>>> a[1:] # 获取从索引为1的元素到最后一个元素
[2, 3, 4, 99]
>>> a[:3] # 获取从第一个元素到索引为3(不包括3!)的元素
[1, 2, 3]
>>> a[:-1] # 获取从第一个元素到最后一个元素的前一个元素之间的元素
[1, 2, 3, 4]
>>> a[:-2] # 获取从第一个元素到最后一个元素的前二个元素之间的元素
[1, 2, 3]
进行列表的切片时,需要写成 a[0:2]这样的形式。 a[0:2]用于取出从索引为 0的元素到索引为 2的元素的前一个元素之间的元素。另外,索引−1对应最后一个元素, −2对应最后一个元素的前一个元素。
字典
列表根据索引,按照 0, 1, 2, . . .的顺序存储值,而字典则以键值对的形式存储数据。字典就像《新华字典》那样,将单词和它的含义对应着存储起来。
>>> me = {'height':180} # 生成字典
>>> me['height'] # 访问元素
180
>>> me['weight'] = 70 # 添加新元素
>>> print(me)
{'height': 180, 'weight': 70}
布尔型
Python中有 bool型。 bool型取 True或 False中的一个值。针对 bool型的运算符包括 and、 or和 not(针对数值的运算符有 +、 -、 *、 /等,根据不同的数据类型使用不同的运算符)
>>> hungry = True # 饿了?
>>> sleepy = False # 困了?
>>> type(hungry)
<class 'bool'>
>>> not hungry
False
>>> hungry and sleepy # 饿并且困
False
>>> hungry or sleepy # 饿或者困
True
if语句
根据不同的条件选择不同的处理分支时可以使用 if/else语句
>>> hungry = True
>>> if hungry:
... print("I'm hungry")`在这里插入代码片`
...
I'm hungry
>>> hungry = False
>>> if hungry:
... print("I'm hungry") # 使用空白字符进行缩进
... else:
... print("I'm not hungry")
... print("I'm sleepy")
...
I'm not hungry
I'm sleepy
Python中的空白字符具有重要的意义。上面的if语句中, if hungry:下面的语句开头有4个空白字符。它是缩进的意思,表示当前面的条件(if hungry)成立时,此处的代码会被执行。这个缩进也可以用tab表示, Python中推荐使用空白字符。
for 语句
进行循环处理时可以使用 for语句。
>>> for i in [1, 2, 3]:
... print(i)
...
1 2 3
函数
可以将一连串的处理定义成函数(function)。
>>> def hello():
... print("Hello World!")
...
>>> hello()
Hello World!
此外,函数可以取参数。
>>> def hello(object):
... print("Hello " + object + "!")
...
>>> hello("cat")
Hello cat!
另外,字符串的拼接可以使用 +。
关闭Python解释器时, Linux或Mac OS X的情况下输入Ctrl-D(按住Ctrl,再按D键); Windows的情况下输入Ctrl-Z,然后按Enter键。
Python脚本文件
Python解释器能够以对话模式执行程序,非常便于进行简单的实验。但是,想进行一
连串的处理时,因为每次都需要输入程序,所以不太方便。这时,可以将Python程序保存为文件,然后(集中地)运行这个文件。
保存为文件
-
打开文本编辑器,新建一个 hungry.py的文件。 hungry.py只包含下面一行语句。
print("I'm hungry!") -
接着,打开终端(Windows中的命令行窗口),移至 hungry.py所在的位置。
-
然后,将 hungry.py文件名作为参数,运行 python命令。
这里假设 hungry.py在 ~/deep-learning-from-scratch/ch01目录下(在本书提供的源代码中,hungry.py文件位于 ch01目录下)。
$ cd ~/deep-learning-from-scratch/ch01 # 移动目录
$ python hungry.py
I'm hungry!
类
int和 str等数据类型是“内置”的数据类型,是Python中一开始就有的数据类型。如果用户自己定义类的话,就可以自己创建数据类型。此外,也可以定义原创的方法(类的函数)和属性。
Python中使用 class关键字来定义类,类要遵循下述格式(模板)。
class 类名:
def __init__(self, 参数, …): # 构造函数
...
def 方法名1(self, 参数, …): # 方法1
...
def 方法名2(self, 参数, …): # 方法2
...
__init__方法,这是进行初始化的方法,也称为构造函数(constructor),只在生成类的实例时被调用一次。
此外,在方法的第一个参数中明确地写入表示自身(自身的实例)的 self是Python的一个特点(学过其他编程语言的人可能会觉得这种写 self的方式有一点奇怪)。
例子:
class Man:
def __init__(self, name):
self.name = name
print("Initialized!")
def hello(self):
print("Hello " + self.name + "!")
def goodbye(self):
print("Good-bye " + self.name + "!")
m = Man("David")
m.hello()
m.goodbye()
从终端运行 man.py。
$ python man.py
Initialized!
Hello David!
Good-bye David!
类 Man的构造函数(初始化方法)会接收参数 name,然后用这个参数初始
化实例变量 self.name。 实例变量是存储在各个实例中的变量。 Python中可
以像 self.name这样,通过在 self后面添加属性名来生成或访问实例变量。
NumPy
NumPy的数组类(numpy.array)中提供了很多便捷的方法,在实现深度学习时,我们将使用这些方法。
导入NumPy
NumPy是外部库。这里所说的“外部”是指不包含在标准版 Python中。因此,我们首先要导入NumPy库。
>>> import numpy as np
直译的话就是“将 numpy作为 np导入”的意思。通过写成这样的形式,之后NumPy相关的方法均可通过 np来调用。
生成NumPy数组
要生成NumPy数组,需要使用np.array()方法。 np.array()接收Python列表作为参数,生成NumPy数组(numpy.ndarray)。
>>> x = np.array([1.0, 2.0, 3.0])
>>> print(x)
[ 1. 2. 3.]
>>> type(x)
<class 'numpy.ndarray'>
NumPy 的算术运算
下面是NumPy数组的算术运算的例子。
>>> x = np.array([1.0, 2.0, 3.0])
>>> y = np.array([2.0, 4.0, 6.0])
>>> x + y # 对应元素的加法
array([ 3., 6., 9.])
>>> x - y
array([ -1., -2., -3.])
>>> x * y # element-wise product
array([ 2., 8., 18.])
>>> x / y
array([ 0.5, 0.5, 0.5])
数组 x和数组 y的元素个数是相同的(两者均是元素个数为3的一维数组)。
当 x和 y的元素个数相同时,可以对各个元素进行算术运算。如果元素个数不同,程序就会报错,所以元素个数保持一致非常重要。另外,“对应元素的”的英文是 element-wise,比如“对应元素的乘法”就是element-wise product。
NumPy数组不仅可以进行element-wise运算,也可以和单一的数值(标量)组合起来进行运算。此时,需要在NumPy数组的各个元素和标量之间进行运算。这个功能也被称为广播(详见后文)
>>> x = np.array([1.0, 2.0, 3.0])
>>> x / 2.0
array([ 0.5, 1. , 1.5])
NumPy的N维数组
NumPy不仅可以生成一维数组(排成一列的数组),也可以生成多维数组。比如,可以生成如下的二维数组(矩阵)
>>> A = np.array([[1, 2], [3, 4]])
>>> print(A)
[[1 2]
[3 4]]
>>> A.shape
(2, 2)
>>> A.dtype
dtype('int64')
这里生成了一个2 × 2的矩阵 A。另外,矩阵 A的形状可以通过 shape查看,矩阵元素的数据类型可以通过 dtype查看。下面,我们来看一下矩阵的算术运算。
>>> B = np.array([[3, 0],[0, 6]])
>>> A + B
array([[ 4, 2],
[ 3, 10]])
>>> A * B
array([[ 3, 0],
[ 0, 24]])
和数组的算术运算一样,矩阵的算术运算也可以在相同形状的矩阵间以对应元素的方式进行。并且,也可以通过标量(单一数值)对矩阵进行算术运算。这也是基于广播的功能。
>>> print(A)
[[1 2]
[3 4]]
>>> A * 10
array([[ 10, 20],
[ 30, 40]])
NumPy 数组(np.array)可以生成 N 维数组,即可以生成一维数组、二维数组、三维数组等任意维数的数组。数学上将一维数组称为向量,将二维数组称为矩阵。另外,可以将一般化之后的向量或矩阵等统称为张量(tensor)。本书基本上将二维数组称为“矩阵”,将三维数组及三维以上的数组称为“张量”或“多维数组”。
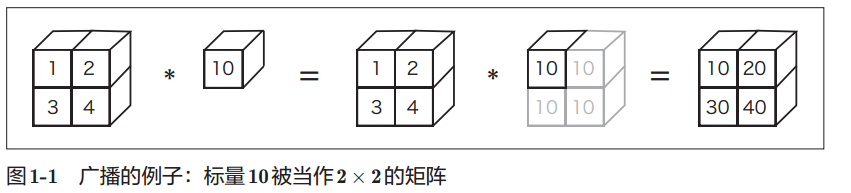
广播
NumPy中,形状不同的数组之间也可以进行运算。之前的例子中,在
2×2的矩阵 A和标量 10之间进行了乘法运算。在这个过程中,如图1-1所示,
标量 10被扩展成了2 × 2的形状,然后再与矩阵 A进行乘法运算。这个巧妙
的功能称为广播(broadcast)。
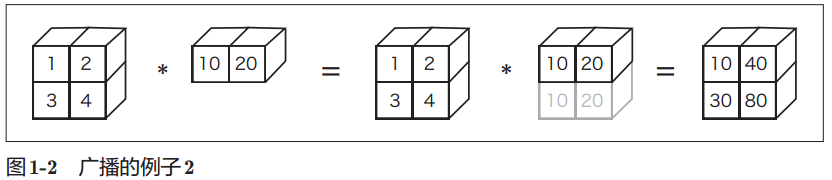
我们通过下面这个运算再来看一个广播的例子。
>>> A = np.array([[1, 2], [3, 4]])
>>> B = np.array([10, 20])
>>> A * B
array([[ 10, 40],
[ 30, 80]])
在这个运算中,如图1-2所示,一维数组 B被“巧妙地”变成了和二位数组 A相同的形状,然后再以对应元素的方式进行运算。
综上,因为NumPy有广播功能,所以不同形状的数组之间也可以顺利地进行运算。
访问元素
元素的索引从0开始。对各个元素的访问可按如下方式进行。
>>> X = np.array([[51, 55], [14, 19], [0, 4]])
>>> print(X)
[[51 55]
[14 19]
[ 0 4]]
>>> X[0] # 第0行
array([51, 55])
>>> X[0][1] # (0,1)的元素
55
也可以使用 for语句访问各个元素。
>>> for row in X:
... print(row)
...
[51 55]
[14 19]
[0 4]
除了前面介绍的索引操作, NumPy还可以使用数组访问各个元素。
>>> X = X.flatten() # 将X转换为一维数组
>>> print(X)
[51 55 14 19 0 4]
>>> X[np.array([0, 2, 4])] # 获取索引为0、 2、 4的元素
array([51, 14, 0])
运用这个标记法,可以获取满足一定条件的元素。例如,要从 X中抽出大于15的元素,可以写成如下形式。
>>> X > 15
array([ True, True, False, True, False, False], dtype=bool)
>>> X[X>15]
array([51, 55, 19])
对NumPy数组使用不等号运算符等(上例中是 X > 15),结果会得到一个布尔型的数组。上例中就是使用这个布尔型数组取出了数组的各个元素(取出 True对应的元素)。
Python等动态类型语言一般比C和C++等静态类型语言(编译型语言)运算速度慢。实际上,如果是运算量大的处理对象,用C/C++写程序更好。为此,当 Python 中追求性能时,人们会用 C/C++ 来实现处理的内容。Python 则承担“中间人”的角色,负责调用那些用 C/C++写的程序。NumPy中,主要的处理也都是通过C或C++实现的。因此,我们可以在不损失性能的情况下,使用Python便利的语法。
Matplotlib
在深度学习的实验中,图形的绘制和数据的可视化非常重要。 Matplotlib是用于绘制图形的库,使用Matplotlib可以轻松地绘制图形和实现数据的可视化。这里,我们来介绍一下图形的绘制方法和图像的显示方法。
绘制简单图形
可以使用 matplotlib的 pyplot模块绘制图形。话不多说,我们来看一个绘制sin函数曲线的例子。
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x = np.arange(0, 6, 0.1) # 以0.1为单位,生成0到6的数据
y = np.sin(x)
plt.plot(x, y)
plt.show()
这里使用NumPy的 arange方法生成了 [0, 0.1, 0.2, …, 5.8, 5.9]的数据,将其设为 x。对 x的各个元素,应用NumPy的sin函数 np.sin(),将 x、y的数据传给 plt.plot方法,然后绘制图形。最后,通过 plt.show()显示图形。运行上述代码后,就会显示图1-3所示的图形。

pyplot的功能
在刚才的sin函数的图形中,我们尝试追加cos函数的图形,并尝试使用pyplot的添加标题和x轴标签名等其他功能。
import numpy as np
import matplotlib.pyplot as plt
# 生成数据
x = np.arange(0, 6, 0.1) # 以0.1为单位,生成0到6的数据
y1 = np.sin(x)
y2 = np.cos(x)
# 绘制图形
plt.plot(x, y1, label="sin")
plt.plot(x, y2, linestyle = "--", label="cos") # 用虚线绘制
plt.xlabel("x") # x轴标签
plt.ylabel("y") # y轴标签
plt.title('sin & cos') # 标题
plt.legend()
plt.show()
结果如图1-4所示,我们看到图的标题、轴的标签名都被标出来了。

显示图像
pyplot 中还提供了用于显示图像的方法 imshow()。另外,可以使用matplotlib.image模块的 imread()方法读入图像。下面我们来看一个例子。
import matplotlib.pyplot as plt
from matplotlib.image import imread
img = imread('lena.png') # 读入图像(设定合适的路径!)
plt.imshow(img)
plt.show()
运行上述代码后,会显示图 1-5所示的图像。

这里,我们假定图像 lena.png在当前目录下。读者根据自己的环境,可能需要变更文件名或文件路径。另外,本书提供的源代码中,在 dataset目录下有样本图像 lena.png。比如,在通过 Python解释器从 ch01目录运行上述代码的情况下,将图像的路径 'lena.png’改为 ‘…/dataset/lena.png’,即可正确运行。
小结
本章只介绍了关于Python的最低限度的知识,想进一步了解Python的读者,可以参考下面这些图书。首先推荐《Python语言及其应用》[1]一书。这是一本详细介绍从Python编程的基础到应用的实践性的入门书。关于NumPy,《利用Python进行数据分析》[2]一书中进行了简单易懂的总结。此外,“Scipy Lecture Notes” [3]这个网站上也有以科学计算为主题的NumPy和Matplotlib的详细介绍,有兴趣的读者可以参考。
下面,我们来总结一下本章所学的内容,如下所示:

[1]: Bill Lubanovic. Introducing PythonA. O’Reilly Media, 2014.
[2]: Wes McKinney. Python for Data AnalysisB. O’Reilly Media.
[3]: Scipy Lecture Notes.















 1264
1264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









