









目录
在复习《Tensorflow实战Google深度学习框架(第2版)》一书的第5章,第97页时,遇到了一个问题。EMA,大家都知道,指数滑动平均,好处在于1.平滑数据、2.可以存储近似n个时刻的平均值,而不用在内存中保留n个时刻的历史数据,减少了内存消耗。但是,EMA在深度学习中的使用场景是什么?参与了训练过程还是测试过程?哪些场景不需要使用ema?
什么是EMA
EMA(Exponential Moving Average)是指数移动平均值。 也叫EXPMA 指标,它也是一种趋向类指标,指数移动平均值是以指数式递减加权的移动平均。ema的具体实现就不多说,《Tensorflow实战Google深度学习框架》第四章对ema的使用已经介绍的非常清楚了。这边再简单地提一下:
滑动平均可以看作是变量的过去一段时间取值的均值,相比对变量直接赋值而言,滑动平均得到的值在图像上更加平缓光滑,抖动性更小,不会因为某次的异常取值而使得滑动平均值波动很大,如下图所示,绿色和棕色的线表示使用不同的ema公式。
TensorFlow 提供了 tf.train.ExponentialMovingAverage 来实现滑动平均。在初始化 ExponentialMovingAverage 时,需要提供一个衰减率(decay)。这个衰减率将用于控制模型的更新速度。ExponentialMovingAverage 对每一个变量(variable)会维护一个影子变量(shadow_variable),这个影子变量的初始值就是相应变量的初始值,而每次运行变量更新时,影子变量的值会更新为:
![]()
decay 决定了影子变量的更新速度,decay 越大影子变量越趋于稳定。在实际运用中,decay一般会设成非常接近 1 的数(比如0.999或0.9999)。为了使得影子变量在训练前期可以更新更快,ExponentialMovingAverage 还提供了 num_updates 参数动态设置 decay 的大小。如果在初始化 ExponentialMovingAverage 时提供了 num_updates 参数,那么每次使用的衰减率将是:
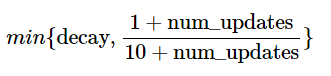
现在的这一长串公式我们都不去过多的深究,有一点可以提一下,就是为什么ema值在上述公式中称为shadow(影子变量)。我们从吴恩达的公开课里面可以看出原因,下图是温度数据(蓝点)和拟合曲线(红线)、EMA曲线(绿线),可以看到绿线有明显滞后性,亦步亦趋,如影随形,所以称之为影子变量,确实也很形象了:
EMA在深度学习中的使用场景
上文简单介绍了一下背景知识,现在回到正题,什么场景使用ema,是训练还是测试?其实实际使用中,EMA主要还是维护tf.trainable_variables(),通常是W和b,使用代码一般如下:
ema = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
ema_op = ema.apply(tf.trainable_variables())但是ema不参与实际的训练过程,是用在测试过程的,作用是使得模型在测试数据上更加健壮,有更好的鲁棒性。或者是最后save模型时存储ema的值,取最近n次的近似平均值,使模型具备更好的测试指标(accuracy)等,更强的泛化能力。
滑动平均可以使模型在测试数据上更健壮(robust)。“采用随机梯度下降算法(一般是指batch-SGD)训练神经网络时,使用滑动平均在很多应用中都可以在一定程度上提高最终模型在测试数据上的表现。”
对神经网络边的权重 weights 使用滑动平均,得到对应的影子变量 shadow_weights。在训练过程仍然使用原来不带滑动平均的权重 weights,不然无法得到 weights 下一步更新的值,又怎么求下一步 weights 的影子变量 shadow_weights。之后在测试过程中使用 shadow_weights 来代替 weights 作为神经网络边的权重,这样在测试数据上效果更好。因为 shadow_weights 的更新更加平滑,对于随机梯度下降而言,更平滑的更新说明不会偏离最优点很远;对于梯度下降 batch gradient decent,我感觉影子变量作用不大,因为梯度下降的方向已经是最优的了,loss 一定减小;对于 mini-batch gradient decent,可以尝试滑动平均,毕竟 mini-batch gradient decent 对参数的更新也存在抖动。
设 decay=0.999,一个更直观的理解,在最后的 1000 次训练过程中,模型早已经训练完成,正处于抖动阶段,而滑动平均相当于将最后的 1000 次抖动进行了平均,这样得到的权重会更加 robust。
实际代码比对-验证无法使用ema进行训练
使用实际值训练,使用ema测试,正常
# 指数衰减的学习率设置,使用正则化来避免过度拟合,使用滑动平均模型使得最终模型更加健壮
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# MNIST数据集相关的常熟
INPUT_NODE = 784
OUTPUT_NODE = 10
# 配置神经网络的参数
LAYER1_NODE = 500 #
BATCH_SIZE = 100 # 一个训练batch中的训练数据个数。数字越小时,训练过程越接近随机梯度下降。数字越大时,训练越接近梯度下降
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARZATION_RATE = 0.0001
TRANING_STEPS = 30000 # 训练轮数
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均衰减率
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
if avg_class == None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
else:
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
# 训练模型的过程
def train(mnist):
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name="y-input")
# 生成隐藏层的参数,不需要给定具体的数值。只需要知道出和入的维度,然后生成满足正态随机分布的数值即可
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成输出层的参数
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
# 计算当前参数下神经网络前向传播的结果,这里给出的用于计算滑动平均的类为None。
y = inference(x, None, weights1, biases1, weights2, biases2)
global_step = tf.Variable(0, trainable=False)
# 给定滑动平均衰减率和训练轮数的变量,初始化滑动平均类。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
# 在所有代表神经网络参数的变量上使用滑动平均。其余辅助变量则不适用如global_step
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算使用滑动平均之后的前向传播结果
average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
# 计算当前batch中所有样例的交叉熵平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 计算L2正则化损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARZATION_RATE)
# 计算模型的正则化损失。一般只计算权重,而不计算偏置项
regularization = regularizer(weights1) + regularizer(weights2)
# 总损失等于交叉熵损失和正则化损失的和
loss = cross_entropy_mean + regularization
# 设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
##初始化会话并开始训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run()
validate_feed = {x: mnist.validation.images,
y_: mnist.validation.labels}
test_feed = {x: mnist.test.images,
y_: mnist.test.labels}
# 迭代地训练神经网络:
for i in range(TRANING_STEPS):
if i % 1000 == 0:
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print("After %d traning step(s), validation accuracy using average model is %g" % (i, validate_acc))
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op, feed_dict={x: xs, y_: ys})
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("After %d traning step(s), test accuracy using average model is %g" % (TRANING_STEPS, test_acc))
def main(argv=None):
mnist = input_data.read_data_sets(r"C:\Users\PycharmProjects\Daily_Learning\TF_learning\TFOrg\MNIST_data",
one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()

使用ema测试与训练,accuracy异常
# 指数衰减的学习率设置,使用正则化来避免过度拟合,使用滑动平均模型使得最终模型更加健壮
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# MNIST数据集相关的常熟
INPUT_NODE = 784
OUTPUT_NODE = 10
# 配置神经网络的参数
LAYER1_NODE = 500 #
BATCH_SIZE = 100 # 一个训练batch中的训练数据个数。数字越小时,训练过程越接近随机梯度下降。数字越大时,训练越接近梯度下降
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARZATION_RATE = 0.0001
TRANING_STEPS = 30000 # 训练轮数
MOVING_AVERAGE_DECAY = 0.99 # 滑动平均衰减率
def inference(input_tensor, avg_class, weights1, biases1, weights2, biases2):
if avg_class == None:
layer1 = tf.nn.relu(tf.matmul(input_tensor, weights1) + biases1)
return tf.matmul(layer1, weights2) + biases2
else:
layer1 = tf.nn.relu(tf.matmul(input_tensor, avg_class.average(weights1)) + avg_class.average(biases1))
return tf.matmul(layer1, avg_class.average(weights2)) + avg_class.average(biases2)
# 训练模型的过程
def train(mnist):
x = tf.placeholder(tf.float32, [None, INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, OUTPUT_NODE], name="y-input")
# 生成隐藏层的参数,不需要给定具体的数值。只需要知道出和入的维度,然后生成满足正态随机分布的数值即可
weights1 = tf.Variable(tf.truncated_normal([INPUT_NODE, LAYER1_NODE], stddev=0.1))
biases1 = tf.Variable(tf.constant(0.1, shape=[LAYER1_NODE]))
# 生成输出层的参数
weights2 = tf.Variable(tf.truncated_normal([LAYER1_NODE, OUTPUT_NODE], stddev=0.1))
biases2 = tf.Variable(tf.constant(0.1, shape=[OUTPUT_NODE]))
# 计算当前参数下神经网络前向传播的结果,这里给出的用于计算滑动平均的类为None。
y = inference(x, None, weights1, biases1, weights2, biases2)
global_step = tf.Variable(0, trainable=False)
# 给定滑动平均衰减率和训练轮数的变量,初始化滑动平均类。
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
# 在所有代表神经网络参数的变量上使用滑动平均。其余辅助变量则不适用如global_step
variable_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算使用滑动平均之后的前向传播结果
average_y = inference(x, variable_averages, weights1, biases1, weights2, biases2)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=average_y, labels=tf.argmax(y_, 1))
# 计算当前batch中所有样例的交叉熵平均值
cross_entropy_mean = tf.reduce_mean(cross_entropy)
# 计算L2正则化损失函数
regularizer = tf.contrib.layers.l2_regularizer(REGULARZATION_RATE)
# 计算模型的正则化损失。一般只计算权重,而不计算偏置项
regularization = regularizer(weights1) + regularizer(weights2)
# 总损失等于交叉熵损失和正则化损失的和
loss = cross_entropy_mean + regularization
# 设置指数衰减的学习率
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE,
LEARNING_RATE_DECAY
)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variable_averages_op]):
train_op = tf.no_op(name='train')
correct_prediction = tf.equal(tf.argmax(average_y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
##初始化会话并开始训练过程
with tf.Session() as sess:
tf.global_variables_initializer().run()
validate_feed = {x: mnist.validation.images,
y_: mnist.validation.labels}
test_feed = {x: mnist.test.images,
y_: mnist.test.labels}
# 迭代地训练神经网络:
for i in range(TRANING_STEPS):
if i % 1000 == 0:
validate_acc = sess.run(accuracy, feed_dict=validate_feed)
print("After %d traning step(s), validation accuracy using average model is %g" % (i, validate_acc))
xs, ys = mnist.train.next_batch(BATCH_SIZE)
sess.run(train_op, feed_dict={x: xs, y_: ys})
test_acc = sess.run(accuracy, feed_dict=test_feed)
print("After %d traning step(s), test accuracy using average model is %g" % (TRANING_STEPS, test_acc))
def main(argv=None):
mnist = input_data.read_data_sets(r"C:\Users\PycharmProjects\Daily_Learning\TF_learning\TFOrg\MNIST_data",
one_hot=True)
train(mnist)
if __name__ == '__main__':
tf.app.run()
















 225
225











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









