






搬来大佬的啊 感谢大佬啊~
这里主要面向具备一定的深度学习基础,但是新接触NLP和大模型领域的读者,目的是能提纲挈领地快速把握这个领域的一系列关键工作节点。是GPT 系列
这篇是对 GPT 系列文章的一个学习笔记,从个人角度梳理了 GPT 系列的迭代逻辑,相对来说更关注整体的技术逻辑连续性和关联性,对于部分个人感兴趣的内容也会稍微展开多列举一些。
这个系列的笔记主要面向已经具备一定的深度学习基础,但是新接触 NLP 和大模型领域的读者,目的是能提纲挈领地快速把握这个领域的一系列关键工作节点。
这篇笔记涵盖的内容有:
- GPT-1 论文
- GPT-2 论文
- GPT-3 论文
- InstructGPT 论文(GPT-3.5 背后的技术)
- GPT-4 技术报告
- GPT-4 微软评测报告
- GPT-4V 微软评测报告
作为一个从 CV 转到 LLM 的新人,难免犯一些常见或低级的错误,欢迎任何读者及时指出和斧正,也欢迎任何留言讨论。
TL;DL
- 注重能力,而非过程:预训练任务其实形式不重要,可以是 classification,可以是预测 next token,真正重要的是 model 和 data 的 scaling up,以此快速高效地得到一个有优异泛化能力的特征提取器:
- data:找到/设计一个能把海量的数据用起来的任务,能用的数据越多越好,训练越快越好
- model:模型性能可以随着参数量巨量地提升而不会快速饱和,一个优秀的模型架构是 scaling up 的基础保障
- 三种范式:
- 我们可以将专属任务上微调得到的模型,看成一种用户输入 0 个特殊 token,解决 1 种任务的范式,所以第一范式下的每个模型只能用于解决一个专属任务。
- 第二范式的模型是为每一种任务准备 1 个特殊 token,因此通过改变输入 token,就能用一个模型解决不同的任务。
- 第三范式的模型把特殊 token 替换成了特殊 token 序列,而自然语言正好就是一种最符合人类习惯和直觉的特殊 token 序列。
- RLHF:
- SFT 模型(16 epoch)
- RM
- PPO 继续训练出来的最终模型
- SFT 数据(13k 条):人工设计的问题,人工标注答案
- Feedback 数据(33k 条):针对上面人工设计的问题,模型输出的几份答案的排序(打分)
- PPO 使用的数据(31k 条):人工设计的问题(上面的模型没见过的新问题),用 RM 的评分来继续训练,这份数据不需要人工标注答案
- 对 GPT-4 的全面探索:
- 心理学角度:人类思维是快思考与慢思考两个系统的混合体,而 GPT-4 目前更类似于单纯的快思考
- GPT-4 还有哪些局限性,以及哪些可以改进的地方(见 GPT-4 微软报告)
- GPT-4V 的全面探索:
- 支持哪些输入和工作模式
- 在不同领域和任务上的能力质量和通用性如何
- 有效使用和提示方法
- 未来方向
1. Improving Language Understanding by Generative Pre-Training (2018.06)
GPT 系列的第一篇论文,定下了纯 Transformer-Decoder 路线。
深度学习的早期突破很多来自于 CV 领域,其中很重要的一个原因是 CV 有 ImageNet 这个百万量级的有标注数据集,在 ImageNet 上训练分类任务得到的模型 Backbone 天然就是一个优秀的图片特征提取器,基于这个特征提取器去任意的子任务上做 fine-tuning 效果都不会太差(至少能展现出一定的泛化能力)。而 NLP 领域缺少这样大的数据集,因此一直以来 NLP 模型发力卡在了特征提取器的构筑上,GPT 提出用训练语言模型的方式来得到这个特征提取器,然后用它来做子任务上的微调。
语言模型由于做的是“预测下一个词”这样的一个任务,因此不依赖于人工标注,可以实现海量数据的预训练和泛化。
GPT 工作是在 BERT 之前的,很多的 setting 都被 BERT 直接沿用了,比如 12 层 Transformer,768 的维度,800M 的 BookCorpus 数据集 等。
文章剩余部分介绍了如何在 NLP 四大主流任务类型上运用 GPT,即如何把不同形式的任务都表示成一个序列+对应的标签的形式。
对笔者的启示:
- 注重能力,而非过程:预训练任务其实形式不重要,可以是 classification,可以是预测 next token,真正重要的是 model 和 data 的 scaling up,以此快速高效地得到一个有优异泛化能力的特征提取器:
- data:找到/设计一个能把海量的数据用起来的任务,能用的数据越多越好,训练越快越好
- model:模型性能可以随着参数量巨量地提升而不会快速饱和,一个优秀的模型架构是 scaling up 的基础保障
2. Language Models are Unsupervised Multitask Learners (2019.02)
GPT 系列的第二篇工作。
参数量提升到了 1.5B,也用了更大量的数据。GPT-2 最大的贡献是把研究的重点从单个任务上的针对性调参刷榜,转向了 zero-shot,即,训练好的模型不再需要微调就能去做不同任务了,尽管性能上距离每个任务的 SOTA 都还有距离,但方案的可行性已经验证了。要实现这一点,原来为特殊任务准备特殊 token 的做法就不合适了,因为预训练阶段模型是没见过这些 token 的,毕竟语言模型预训练阶段只见过自然语言,所以非常自然地就引出了 prompt 的概念,用自然语言来替代原本的任务 token,实现不同任务的 zero-shot。
可以看到,在这个时候 GPT-2 就已经初具 ChatGPT 的雏形了,只不过用户的输入还不完全是任意自然语言,而是类似于这样的模板输入。:
3. Language Models are Few-Shot Learners (2005.14165)
GPT 系列的第三篇工作。
GPT-3 的参数量来到了 175B,训练数据从一开始 GPT-1 的几千本书的数据集,开始进入到了网站爬虫数据和清洗的模式。
其实在 GPT-2 中就已经提到了一个叫 Common Crawl 的公开网络数据,但是因为他们觉得这份数据实在太脏了所以放弃了,而现在为了训练更大的模型也不得不用起来,因此清洗数据是免不了的。
数据清洗经历了两个过程:
- 过滤:他们将原来 GPT-2 训练用的数据作为正样本,Common Crawl 作为负样本训练了一个二分类器,然后用这个分类器来做数据筛选,过滤掉一些特别显著的脏数据。
- 去重:用经典的 LSH 算法进行去重
另一方面,GPT-3 也正式提出了“in-context learning”的概念,在模型参数不进行更新的情况下,通过输入的上下文来帮助模型提升表现。
对于笔者而言,这张图相当形象:

这揭示了模型学习的另一个维度,提升模型表现并不只有 SGD 梯度更新这一个优化方向。结合 GPT-2 中 prompt 的由来,prompt 的前身是语言模型做多任务 zero-shot 时,针对不同任务给的特殊 token,因此一个更加富有信息量的“特殊 token 序列”能提升模型表现似乎是一件非常符合直觉的事情。
相比于过去使用一个特殊 token 来代表某一种特定的任务,GPT-3 的 few-shot prompt,或者说 in-context learning 形式,在笔者看来是一种推广,用户输入的自然语言和 few-shot 样例可以看成是一组特殊 token 的序列,因为自然语言的 token 具有语义和逻辑关联性,一个强大的预训练模型做到了“特殊 token”之间的泛化。
通过实验我们也可以观察到,随着给出的示例样本数变多,模型的表现也在提升:
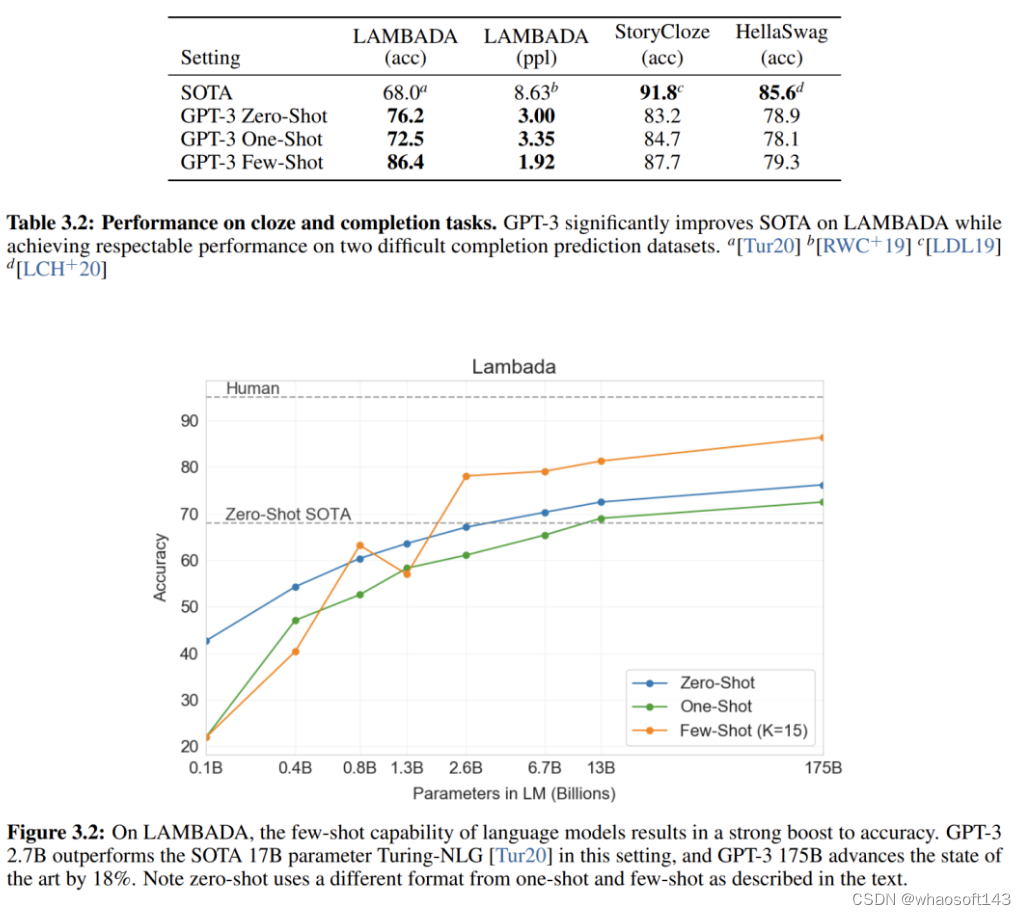
从笔者个人的角度来总结:
- 我们可以将专属任务上微调得到的模型,看成一种用户输入 0 个特殊 token,解决 1 种任务的范式,所以第一范式下的每个模型只能用于解决一个专属任务。
- 第二范式的模型是为每一种任务准备 1 个特殊 token,因此通过改变输入 token,就能用一个模型解决不同的任务。
- 第三范式的模型把特殊 token 替换成了特殊 token 序列,而自然语言正好就是一种最符合人类习惯和直觉的特殊 token 序列。
4. Training language models to follow instructions with human feedback (2203.02155)
InstructGPT 被认为是 ChatGPT(GPT3.5) 背后的技术,核心点是把 RLHF,即基于人类反馈的强化学习,用到了语言模型上来进行人类喜好对齐。经过 RLHF 的 1.3B GPT 模型能在人类主观评分上超过 175B 的 GPT-3.
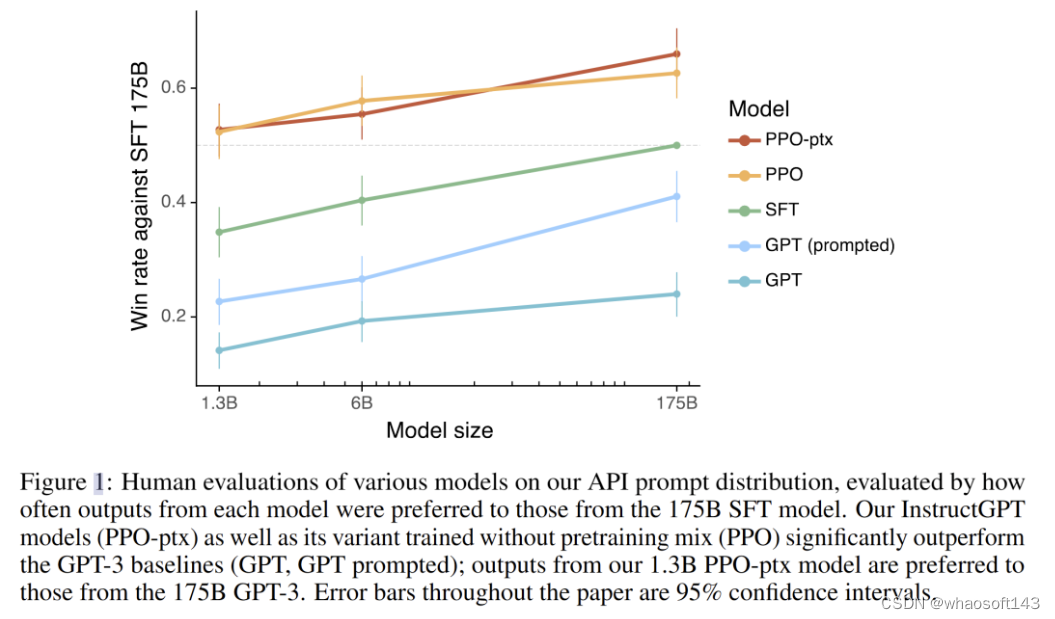
这篇工作里将模型输出与人类意愿不一致的这个现象称为“misaligned”,并分析原因在于语言模型的训练目标只是预测下一个 token,这跟我们希望模型“follow the user's instructions helpfully and safely”的目标之间显然是存在差距的。
用 Anthropic 的工作里的话来说,大模型应该遵循 3H 原则,即:
- helpful:帮助用户解决问题
- honest:不能伪造信息或误导用户
- harmless:不能对人或环境造成身体、心理或社会伤害
语言模型之所以存在这个问题,原因也很简单,因为使用的是无监督学习,本身的学习目标里就没有人为控制,所以很直观地可以想到用监督微调(SFT)的方式来把缺失的人类监督信号加进来。
但是前面 GPT 三篇工作好不容易才把模型做到 175B 这么大,现在又重新开始标数据做监督学习显然是有点不聪明的,而且模型大了以后也更容易过拟合,对于人类偏好这一类的问题标注起来难度又很大,简单地全靠 SFT 肯定是行不通的。所以很自然地,OpenAI 想到了用他们家的拿手好戏强化学习,要知道 OpenAI 本身就是做强化学习起家的,本文使用的强化学习方法 PPO 也全是之前他们已经提出的算法,没有任何新的算法被提出,甚至论文里都没有对已有的算法进行太多的解释和铺垫,需要你感兴趣自己去翻他们的论文。
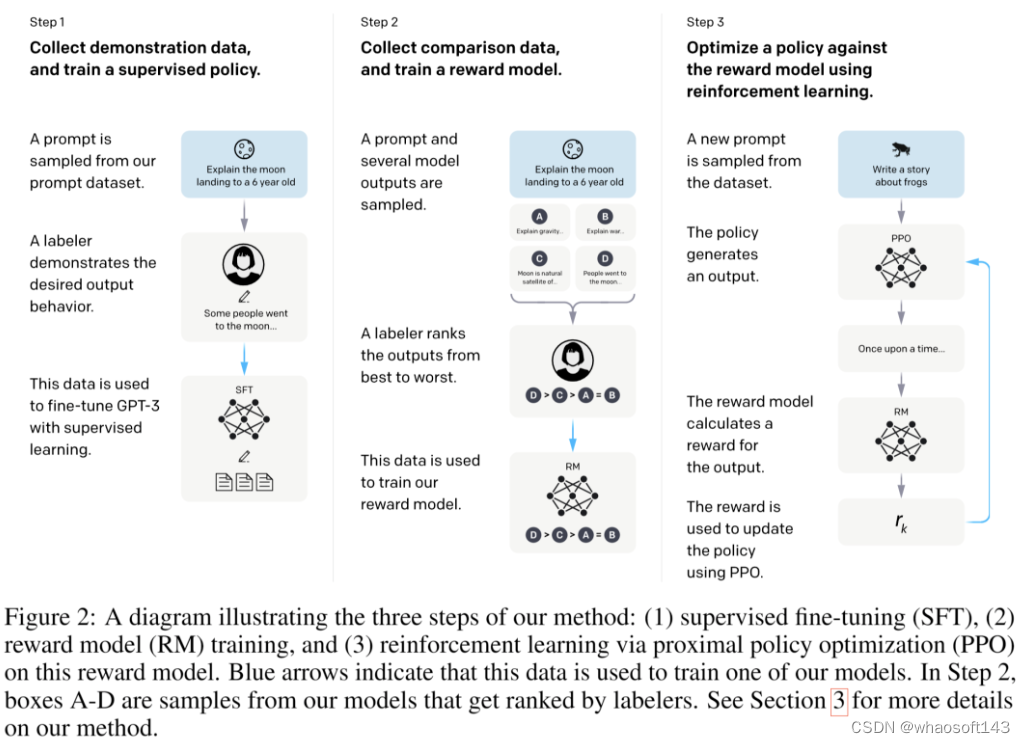
他们的方法整体可以概括如下:
- 人工标一批 SFT 数据(包含问题和回答),对 GPT-3 模型(在强化学习里对应 Policy)进行微调
- 用 SFT 得到的模型,针对每个问题生成几份回答,然后人工给这些回答质量打分(排序)
- 用这份打分数据训练一个奖励模型(Reward Model, RM),让奖励模型代替人工打分
- 采用 PPO 算法,基于奖励模型的评分来继续训练 GPT-3 模型
换言之,他们一共造了三份数据:
- SFT 数据(13k 条):人工设计的问题,人工标注答案
- Feedback 数据(33k 条):针对上面人工设计的问题,模型输出的几份答案的排序(打分)
- PPO 使用的数据(31k 条):人工设计的问题(上面的模型没见过的新问题),用 RM 的评分来继续训练,这份数据不需要人工标注答案
训练三个模型:
- SFT 模型(16 epoch)
- RM
- PPO 继续训练出来的最终模型
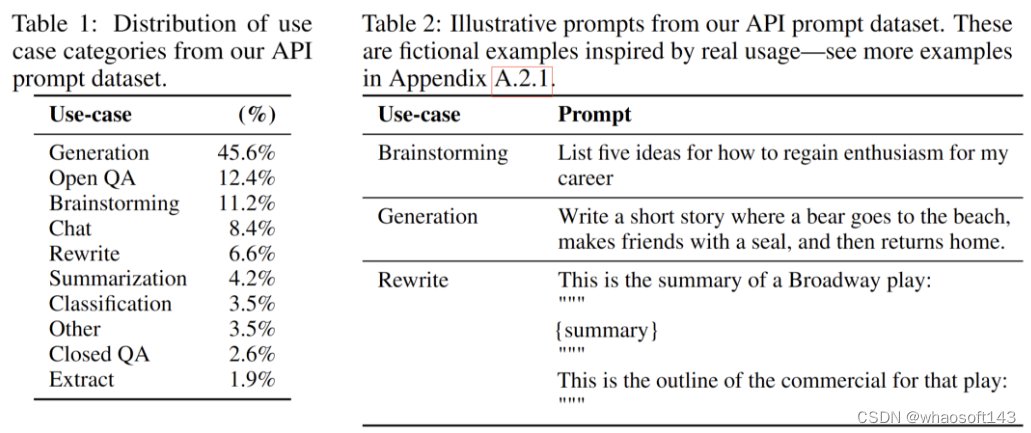
他们甚至对问题类型进行了一些分类:
模型训练部分,个人觉得值得注意的点有:
- SFT 阶段,在训了 1 epoch 后模型就已经过拟合了,但他们发现继续训练过拟合的模型依然可以提升 RM 性能,所以他们训练了 16 epoch
- RM 的权重是直接用 SFT 模型初始化的,因为评分模型也需要语言能力,直接拷贝一份权重是比较省事的。RM 的输入是问题+几份答案,输出是排序。
- RM 模型只有 6B,因为 175B 的 RM 很难训
- 强化学习阶段加了一个逐 token 的 KL 散度,用来让最终模型跟第一版 SFT 模型的要输出分布尽量保持一致,因为 RM 是在训练 SFT 模型的数据上训的,如果分布差异太大,RM 的评分就不准了
强化学习的目标函数如下:

其中:
- RM 评分是 RM 对当前正在训练的模型在新问题(第三份数据)上的输出的评分
- KL 散度是当前模型跟旧的 SFT 模型输出之间计算的
- 旧问题 SFT 损失是用第一份数据集继续按 SFT 方法训当前模型得到的
另外,关于训练数据和评测方面的取舍也有所不同,训练中他们更看重 helpful,而评测阶段则更看重 honest 和 harmless。
5. GPT-4 Technical Report (2303.08774)
多模
基于上面笔者三种模型范式的思路,多模态的模型可以看成是让特殊 token 的类型从文本 token 拓宽到了视觉 token,将模型解决的任务从 NLP 任务拓宽到了 CV 任务,而两种模态 token 对齐的技术也早被 OpenAI 研究过了,也就是大名鼎鼎的 CLIP。因此,GPT-4 具备多模能力本身并不是一件意外的事情。
RLHF
在笔者看来,RLHF 等技术更多地是在不限制输入 token 序列的情况下,去约束模型输出的技术,当然从某种意义上,也可以看成是在监督 prompts -> task 的映射关系的技术(其实发展到现在,task 这个词已经不太准确了,可以意会一下)。
GPT-4 的报告中明确指出,RLHF 并不能提升模型解决任务的质量(不会增加知识),甚至很多时候调的不好还会损害各个任务上的指标。RLHF 更多地是在构建一些明确的 prompts -> task 映射关系,因为自然语言是具有歧义性的,尤其是在输入信息较少的情况下,模型根据 prompts “理解”到的那个 task,并不一定是人类真正心里的那个意图,RLHF 实现了一种定制化的映射搭建,或者说,人类喜好对齐。
Predictable scaling
由于大模型实验的成本日渐高昂,我们不再能像小模型那样随便起实验调参了。因此 OpenAI 的大部分实验应该是在一个比 GPT-4 小很多倍的模型上进行的,然后通过这个小模型的训练 loss,来预测大模型最终训练出来的 loss
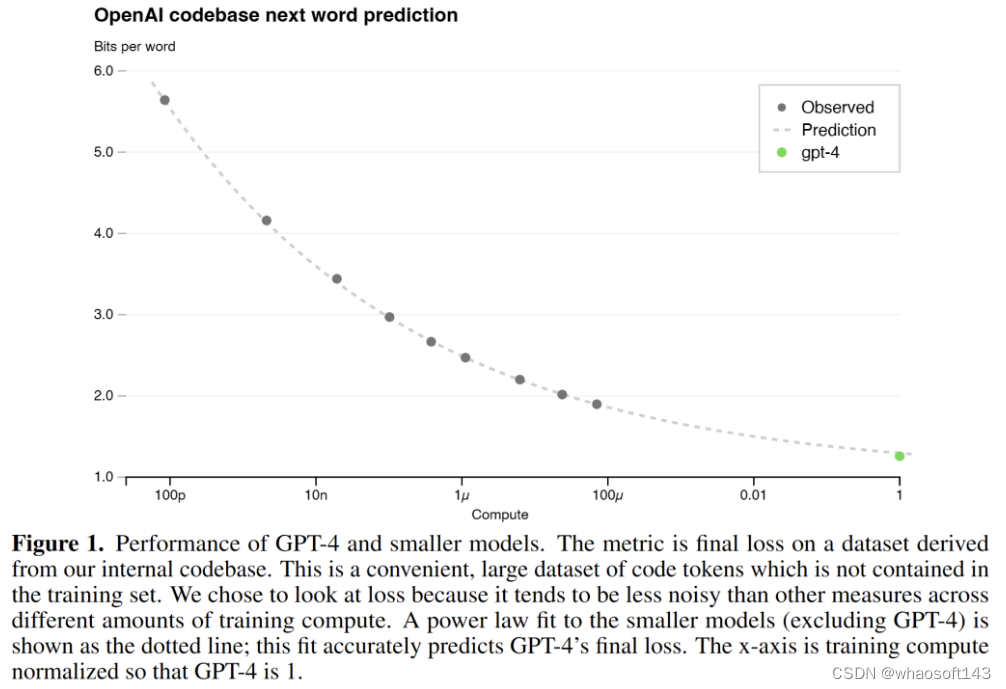
同样的, predictable scaling laws 也在很多 HumanEval 集上得到了观察。当然,在一部分的任务上也还无法被拟合的性能曲线,因此 OpenAI 说后续还会进一步优化他们模型性能预测的方法。
6. Sparks of Artifificial General Intelligence: Early experiments with GPT-4 (2303.12712)
智能(Intelligence)是一个多方面且难以捉摸的概念,长期以来缺乏一个共识性的定义。1994 年 52 名 心理学家组成的公式小组出版的关于智力科学的社论中,将只能定义为一种非常普遍的心理能力,包括推理、计划、解决问题、抽象思考、理解复杂想法、快速学习和从经验中学习的能力。
这篇是微软关于 GPT-4 的研究报告,长达 55 页,文中的实验都是在 早期的文本单一模态版的 GPT-4 上进行的(而不是后面更新的多模态版本), 其目标是生成一些新颖而困难的任务和问题,来证明 GPT-4 的能力并不是单纯的记忆,并且它对概念、技能和领域有深刻而灵活的理解。另外还旨在探索 GPT-4 的响应和行为,以验证其一致性、连贯性和正确性,揭示其局限性和偏差。
如何衡量 GPT-4 的智能
传统机器学习的标准做法是准备一组标准评测数据集,确保它们独立于训练数据之外,覆盖一系列的任务和领域。但这种方法并不太适用于 GPT-4,因为 GPT-4 是闭源模型,相关的训练数据集信息不公开,并且可以预见地非常庞大,因此我们不能保证目前公开的基准测试集不在它的训练数据里。也正因为此,本文采用的研究方法更接近于传统心理学,而不是机器学习方法。
多模态与跨学科整合
智能的一个重要衡量指标是综合不同领域信息的能力,以及跨学科地应用知识和技能的能力。这一节中作者举了四个例子来说明 GPT-4 具有很强的多模态与跨学科整合能力:
- 写 JavaScript 代码来生成画家 Wassily Kandinsky 风格的作品。图一是该画家的原作,后面分别是 GPT-4 和 ChatGPT 写的代码画出的。

2. 用莎士比亚的文风来证明素数无穷定理

3. 以圣雄甘地的口吻写一封信给他的妻子,内容是支持“电子”成为美国总统候选人

4. 写 Python 代码,以年龄、性别、体重、身高和血液测试结果向量作为输入,来预测用户是否有患糖尿病的风险
这些对比可以体现 GPT-4 能创新性地整合不同领域的概念,并且显著强于 ChatGPT。除此之外作者也测试了 GPT-4 在音乐、绘图、空间理解方面的能力。
代码
除了常见的 leetcode 刷题,作者测试了 GPT-4 生成逆向工程代码、解释已有代码、用自然语言模拟代码执行过程、运行伪代码等能力。
数学
在一系列的分析实验后,作者从以下三方面总结了GPT-4的数学能力:
- 创造性推理:识别每个阶段可能相关的参数、中间步骤、计算或代数操作的能力。该组件通常基于启发式猜测或直觉,通常被认为是数学解决问题的最实质性和最深刻的方面
- 技术熟练程度:执行遵循指定步骤集的常规计算或操作的能力
- 批判性推理:批判性地检查论点的每个步骤的能力,将其分解为其子组件,解释它需要的内容,它与其余论点相关以及为什么是正确的
这一节作者发现 GPT-4 的很多缺陷,如:
- 在执行一些很常规且机械的计算时经常算错和混淆
- GPT-4 由于是自回归模型,因此是实时线性输出的,而没有办法“打腹稿”
与世界的交互
智能的另一重要方面是交互能力,即跟外界环境和智能体进行交互的能力,作者主要通过工具调用和具身交互两个维度来评估。
工具调用这里不多赘述了,具身交互方面测试了文字跑团游戏,以及交互式地指导人员找到天花板漏水的地方并进行修补,逐步根据人类的每一步反馈,给出行动建议和指示。
与人类的交互
GPT-4 在推理他人心理状态方面表现非常突出,特别是在模拟现实场景中,它的解释能力也很强,能对自己的判断和言论进行自我解释。
判别能力
判别能力主要指模型区别不同事物、概念和情景的能力。比如,区分两个食物哪个是可以安全食用,哪个是有毒的。
这一节的测试里,揭示出当前的评测指标存在的缺陷:对于语句相似度捕捉不够,依然严重依赖单词和短句的相似度,因此在很多时候参考答案很短,而 GPT-4 生成的答案很长,会被 ROUGE 这样的指标判定为答案不匹配,而人工检查后发现 GPT-4 的答案更加高质量和具有说服力。
另一方面作者也测试了用 GPT-4 作为评分员,对回答进行打分,实验现实尽管距离人类打分还存在一些差距,但在一些强约束的场景下已经很具有竞争力了。
自回归结构的局限性
自回归结构的输出是实时进行的,因此不存在“打草稿”的机会,因此无法“step-by-step”地处理问题,而引入思维链则可以显著地提升模型准确度。
对于一些依赖递归回溯的问题,比如一步一步输出汉诺塔问题的解法,GPT-4 表现非常差,在解决不能以连续方式处理的复杂或创造性问题时,都暴露出了严重的局限性。
比如要求 GPT-4 修改“9 * 4 + 6 * 6 = 72”这个等式左边的一个数字,来让等式计算结果变成 99,这就是一个无法简单“step-by-step”推理得到答案的问题,GPT-4 最后的准确率也非常低。
这一节的讨论中,作者指出,理解这些局限性的一个方法是类比诺奖作者卡尼曼提出的“快思考”和“慢思考”的概念。卡尼曼认为人类思维分成快、慢两个系统,快思考是一种自动的、直观的、不需要花费精力的思考方式,速度快但是容易出错和偏见。慢思考是一种受控的、理性的、耗费精力的思考方式,虽然速度慢但是准确可靠。
当前的 GPT-4 很大程度上可以看成是在执行快思考,但缺少慢思考能力。
未来方向
作者在这一节总结了未来 GPT-4 可以研究和改进的方向:
- 置信度校验:模型的输出缺乏置信度,既会编造训练集中没有的内容(open-domain 幻觉),也会生成与 Prompt 不一致的内容(close-domain 幻觉)

- 长期记忆:即长的上下文
- 持续学习:当前微调和自我更新成本过高、缺乏有效且稳定的手段(保持已有能力不丢失和遗忘)
- 个性化:根据应用和需求进行定制、扮演、调整风格等
- 提前规划和概念性跳跃:推理过程过于线性,在需要思维跳跃性的任务上表现不佳
- 透明度、可解释性和一致性
- 认知谬误和非理性:数据中存在的偏见、成见或错误引入了认知偏差和非理性
- 对输入的敏感性:对于 Prompt 过于敏感,鲁棒性不够
这些局限性均指向一个核心问题:哪些缺陷是自回归架构的先天缺陷,哪些是在已有架构上可以通过处理数据、增加外挂的组件和增大参数量解决的。
7. The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) (2309.17421)
微软发布的 166 页的 GPT-4V 报告,主要围绕以下四个点进行展开研究:
- GPT-4V 支持哪些输入和工作模式?
- GPT-4V 在不同领域和任务上的能力质量和通用性如何?
- GPT-4V 有效使用和提示方法有哪些?
- 未来有哪些有前途的方向?
GPT-4V 的输入模式
- 纯文本
- 单个图像-文本对
- 图像文本交替输入
前两种相对来说比较简单,第三种交替输入的情况,已经非常接近于人的聊天模式了。

GPT-4V 的工作模式和提示技术
实验证明,在 LLM 上研究出来上各种提示技术,在 GPT-4V 上也是好使的,比如思维链、few-shot 提示等。
这一节提到了一个“LLMs don't want to succeed”的理论,貌似是来自于 Andrej Karpathy 的某次演讲,里面展示了一种类似于催眠一样的提示技术,即,你想要你的 LLM 表现更出色,你就要用直接的提示词说“你是xxx方面的专家”,否则它之后表现出一般普通人水平的能力。

完整的 PPT 可以看这里:https://karpathy.ai/stateofgpt.pdf
在论文中作者是举了一个数苹果的案例,让 GPT-4V 来数一下画面中有几个苹果。一开始 GPT-4V 并不能轻易得到正确答案,但经过一系列我们已知的 LLM Prompt 技巧加强后,GPT-4V 变得可靠,能够正确计数:

在日常的人和人交互中,在图片中画圈、画箭头来指向关键信息是一种很自然且常见的方式, 经实验 GPT-4V 在这方面的理解能力非常强大。

作者实验了一些很有挑战性的 case,发现基本上难不倒它:
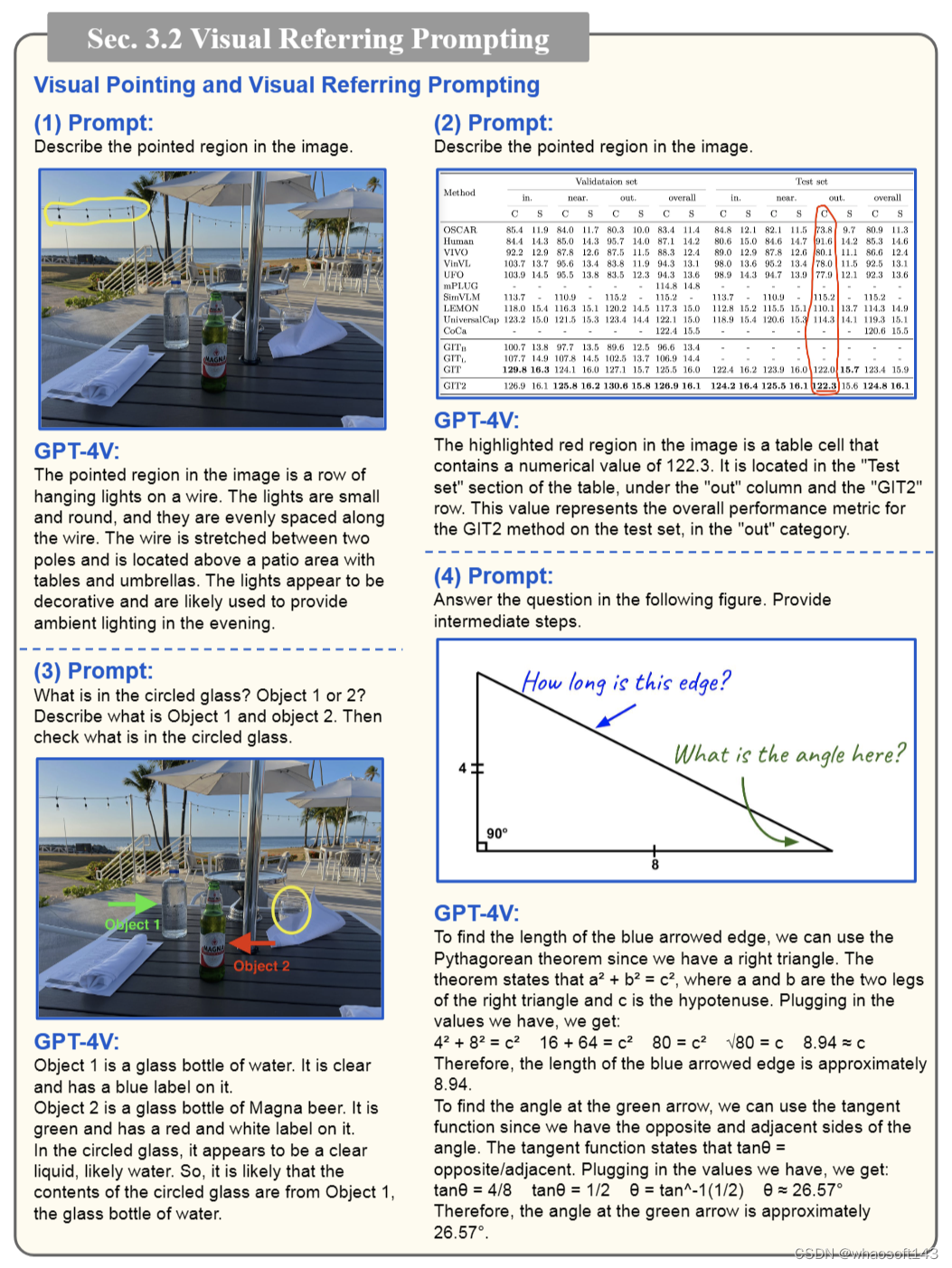
在 In-context few-shot learning 方面,作者也用一个很有代表性的例子说明了提供示例样本的重要性。作者给了一张仪表的图,让 GPT-4V 读出当前仪表指针指向的数值,一开始不论如何改良 prompt 都无法得到正确的结果。

甚至在给出一个示例的情况下模型仍然表现不佳,但当示例增加到两个后,GPT-4V 就突然能成功读数了,可见提供上下文示例对于提升大模型性能至关重要。


视觉语言能力
在大部分已有的 CV 子任务上,GPT-4V 都表现出了不错的能力,常见的场景描述等更是表现出色,在相对小众的领域,如医学图像上,同样让人印象深刻,GPT-4V 可以根据 CT 图判断出智齿和骨折等。

当然,在一些已经被做得非常深入的子任务上,GPT-4V 相较于 SOTA 模型还有不小的差距,但还是那句话,潜力大于绝对精度,目前 GPT-4V 已经展现出了让人鼓舞的性能,优化个别任务上的表现只是时间问题。

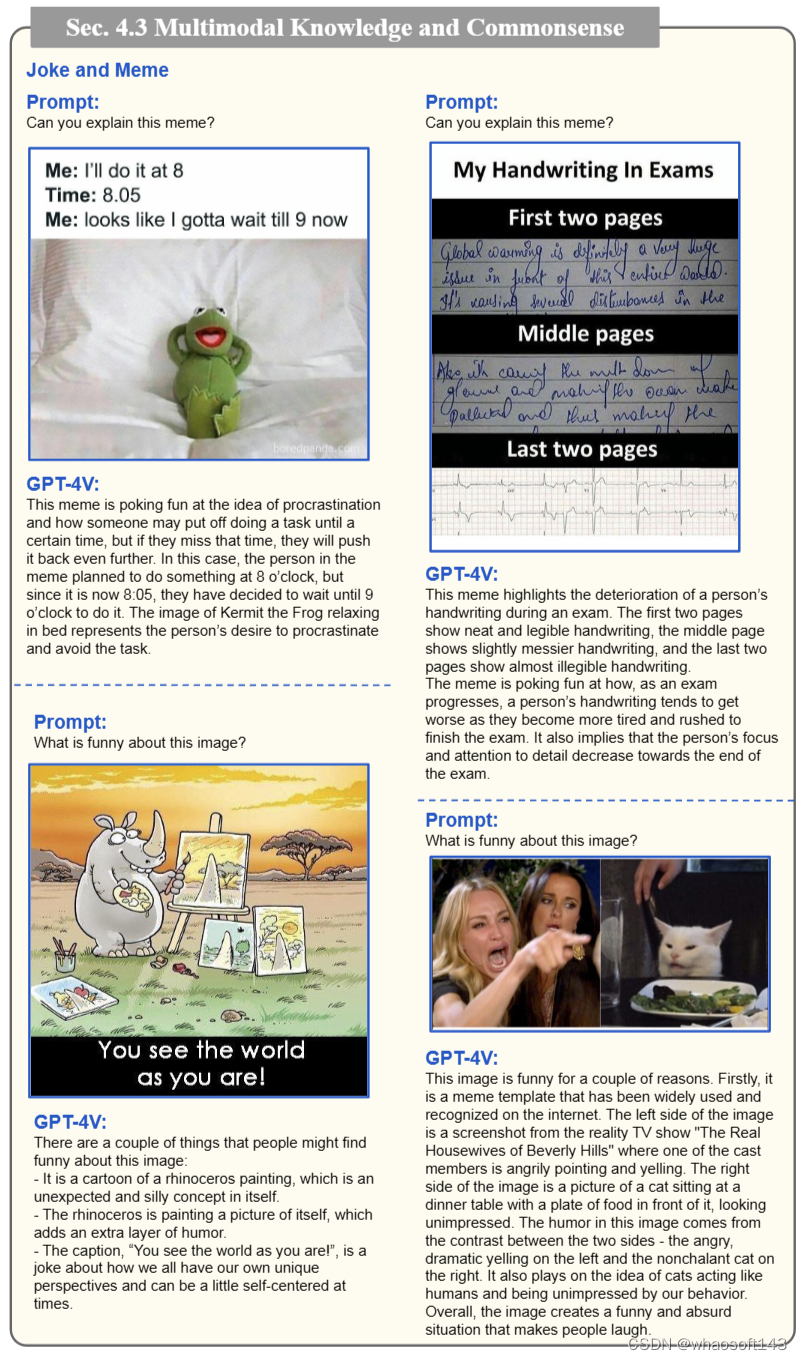
GPT-4V 甚至能看懂梗图,解释其中的笑点:
借助 GPT-4V 强大的推理能力和具备的常识,我们甚至可以“假如你是一名侦探,你可以从图中推理出哪些线索?”

时间序列和视频理解
作者实验了多图像序列,GPT-4V 能够识别出这是一组动态图像序列,并且能结合起来判断画面中的人正在做俯卧撑:

情商测试
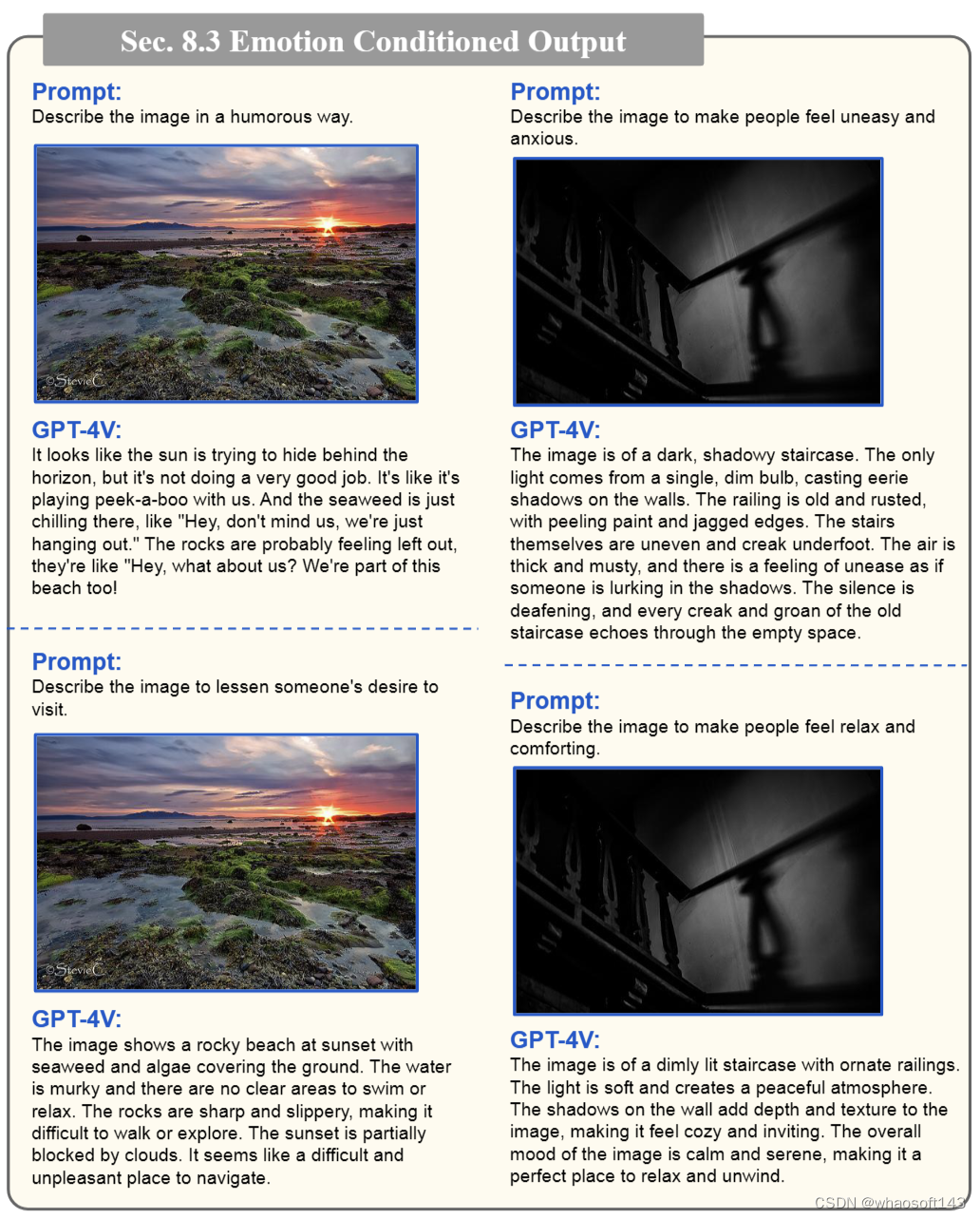
在这一节,GPT-4V 可以基于予以内容和图像样式解释视觉情感,如满意、愤怒、敬畏和恐惧等:

甚至可以一张图片让 GPT-4V 用两种不同方式来描述,分别让人感到不安和感到舒适(新闻学让它玩明白了):
新兴应用亮点
- 行业:
- 缺陷检测
- 安全检查
- 杂货结账
- 医疗
- 汽车保险
- 损害评估
- 保险报告
- 定制化
- 照片组织
- 密集标注与分割
- 图像生成
- 生成图像的评估
- 图像编辑的提示生成
- 具象化智能体
- 操作机器
- 导航
- GUI 导航(软件层面的交互和导航)
整篇报告篇幅较多,并且举了大量详细的例子,在这里就不一一展开了,感兴趣的同学可以自行翻阅。















 381
381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









