






摘要python入门教程的最后一篇了,讲一下关于常用的模块,其实模块的使用需要自己去看文档,毕竟模块这么多,不能全部记住。希望大家看完这个入门系列之后可以把python学会,用好!
如果你看到了这里,那么恭喜你啦,这个是python入门教程的最后一篇了。看完这一篇,你就算把python的一些基本的知识都看完了,之后的学习就是多看看代码。
希望这个系列的教程能对你有所帮助。下面就开始具体内容的介绍。
自定义模块
有的时候, 我们在自己编写Python脚本的时候, 会把相关的脚本放在一个文件夹下, 然后组成一个module, 来方便我们使用. 例如, 这个时候文件夹的整体结构如下所示:
│
│ calSaturation.py
│
└─outputAnalyze
│ outputAnalysis.py
│ __init__.py
这里outputAnalyze相当于是我们自定义的一个模块. 在该文件夹下需要有一个init.py文件. 这个文件可以没有内容, 也可以将outputAnalysis.py文件中的类引入.
在init.py文件的内容如下所示, 需要注意的是, 我们需要在文件前加一个点(.), 表示是在当前文件夹内.
from .outputAnalysis import detector_parse
之后, 我们在外面, calSaturation.py引入的时候, 只需要使用下面的方式即可.
from outputAnalyze import *
添加搜索目录
有的时候,当我们自定义了多个 module 之后,我们需要添加搜索目录,来方便我们导入各个
module。按下面方式在主文件的最前面加上即可。
import os
import sys
filePath = os.path.dirname(os.path.abspath(__file__)) # 获取当前的路径
rootPath = os.path.abspath(os.path.join(filePath, "..")) # 获取上级路径
sys.path.append(filePath)
sys.path.append(rootPath)
pickle
pickle可以将一个Python对象序列化为一个字节流,以便将它保存到一个文件、存储到数据库或者通过网络传输它。
写入方法
f = open('permissionList.pkl', 'wb')
pickle.dump(permissionList, f)
这里注意写入完毕之后需要使用close, 所以完整的步骤如下
f = open('./ProcessData/NSL-KDD_MEAN.pkl', 'wb')
pickle.dump(nsl_kdd_data.dataMean, f)
f.close()
读取方法
with open('permissionList.pkl', 'rb') as f:
permissionList = pickle.load(f)
datetime
datetime 模块提供了一些类用于操作日期时间及其相关的计算。比较常用三个类型:
date 封装了日期操作
datetime 封装日期+时间操作, 这个一定要注意, 有的时候是datetime.datetime, 注意不要少写了.
timedelta 表示一个时间间隔,也就是日期时间的差值
下面看一下使用的例子:
from datetime import date,datetime,timedelta
t = datetime.now() #获取现在的时间
>> datetime.datetime(2018, 1, 25, 20, 3, 13, 311169)
datetime.strftime(t,'%Y-%m-%d %H:%M:%S') #把时间转换为字符串
>> '2018-01-25 20:03:13'
datetime.strptime('2018-01-25 20:03:13', '%Y-%m-%d %H:%M:%S') #把字符串转换为时间
>> datetime.datetime(2018, 1, 25, 20, 3, 13)
tnow = t + timedelta(weeks=1,days=0,hours=0,minutes=0)#对时间进行加减运算
datetime.strftime(tnow,'%Y-%m-%d %H:%M:%S')
>> '2018-02-01 20:03:13'
我们也可以获得毫秒级的时间:
t = datetime.now() #获取现在的时间
datetime.strftime(t,'%Y-%m-%d_%H_%M_%S_%f')
我们也可以直接将秒转换为其对应的时间, 这里时间都是从1970年开始的
datetime.datetime.fromtimestamp(1)
上面的结果如下所示, 可以看到结果是1970年1月1日, 1时1秒:

可以看到这里是从1小时开始计算的, 如果我们只要秒, 我们可以使用上面讲的timedelta减掉一小时.
datetime.datetime.fromtimestamp(1) - datetime.timedelta(hours=1)
上面的结果如下所示:

最后就是将时间转换为小时, 分钟, 秒, 微秒的格式, 这个格式可以用在字幕文件上面.
time = datetime.datetime.fromtimestamp(1) - datetime.timedelta(hours=1)
time.strftime('%H:%M:%S,%f')
最终的结果如下图所示,

因为微秒有6位, 所以要想保留前面3位, 可以使用下面的方式来进行操作.
time.strftime('%H:%M:%S,%f')[:-3]
最终结果如下图所示:

与pandas组合使用
有的时候, 在pandas中的内容都是string格式的, 为了要进行时间的相关操作, 我们需要转换为datetime格式的.
df = pd.read_excel('上班时间.xlsx', encoding='utf-8')
a = pd.to_datetime(df['上班时间'], format="%H:%M:%S")
b = pd.to_datetime(df['下班时间'], format="%H:%M:%S")
这样的数据是Timedelta的数据, 我们可以将其转换为分钟或是小时为单位的数据.
df['minute'] = [times/pd.Timedelta('1 minute') for times in (b-a)]
df['hour'] = [times/pd.Timedelta('1 hour') for times in (b-a)]
os
这个模块在文件处理那里也讲过,可以转到那里去看一下,这里就讲一下其他的用法.
创建文件夹
import os
os.getcwd() #获取当前目录
>> '/home/wmn'
os.mkdir('test') #创建文件夹
os.mknod(os.path.join(os.getcwd(),'text.txt'))#在当前目录创建一个text.txt文件
创建文件所在文件夹
下面这个可以创建文件所在的目录, 比如file_name是./a/file, 但是a这个文件夹不存在, 可以先使用这个来创建文件夹.
os.makedirs(os.path.dirname(file_name), exist_ok=True) # 没有就创建文件夹
获取当前文件地址和上级地址
下面第一行是获取所在文件的绝对路径地址. 第二个是获得其父级目录的地址.
filePath = os.path.dirname(os.path.abspath(__file__)) # 获取当前的路径
rootPath = os.path.abspath(os.path.join(filePath, "..")) # 获取上级路径
我们可以使用os.path.join来合成我们需要的文件的路径. 例如:
os.path.join(filePath, 'images/')
文件路径格式化
在 windows 下直接使用 os.path 会出现反斜杠的问题,如下所示:
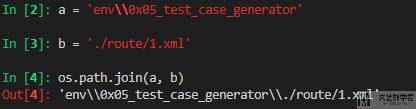
这个时候我们可以使用 os.path.normpath 来进行格式的转化.

分割文件夹路径
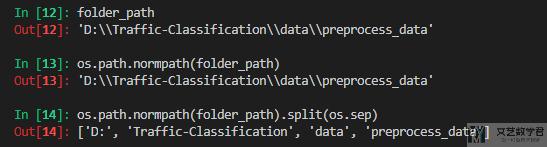
有的时候我们需要将我们的文件路径划分为文件夹的名称。如我们的路径为如下所示:
folder_path = 'D:\Traffic-Classification\data\preprocess_data'
那么我们可以使用 os.path.normpath(folder_path) 来转换路径的形式,接着使用 string.split 来进行分割。可以看一下下面的具体的例子:
listdir的使用
我们看一个修改文件名的例子,这里要求是把例如 1.jpg=>(1+num).jpg:
import os
import fire
def addNum(num,path):
for file in reversed(os.listdir(path)):
# os.listdir('.')遍历文件夹内的每个文件名,并返回一个包含文件名的list
# 这里要倒序,防止小的把大的文件覆盖了
# file为文件名
filename,suffix = file.split('.')
if suffix == 'jpg':
# 改名文件名,比如原来为1.jpg=>(1+num).jpg
newfilename = "{:0>3d}".format(int(filename)+num)
newfilename = "{}.{}".format(newfilename,suffix)
print("Have changed {} to {}".format(file,newfilename))
os.rename("{}/{}".format(path,file), "{}/{}".format(path,newfilename))
def main():
fire.Fire(addNum)
if __name__=='__main__':
# python changeFileName.py 100 ./pic/filename
main()
os.walk的使用
有的时候, 我们需要处理的目录是多层的, 第一层目录下还有其他的目录, 这个时候就需要使用os.walk来进行相关的操作. 下面是一个简答的用法.
import os
for (root, dirs, files) in os.walk(rawPath):
for Ufile in files:
Path = os.path.join(root, Ufile) # 文件的所在路径
File = root.split('/')[-1] # 文件所在文件夹的名字
我们下面再给出一个更加详细的例子, 对文件夹内的图像进行遍历, 对每个文件夹内的图片进行大小的调整, 转换为灰度图, 并重新保存.
文件夹的结构大致如下图所示:

我们也是使用os.walk来完成文件夹的遍历.
# 将图片重新存储
# - 调整大小
# - 调整为灰色
def image_preprocess(dir_path='./dogs_cats_gray/cat/'):
"""图片预处理
"""
i = 0
for img in tqdm(os.listdir(dir_path)): # 调用 tqdm 可视化循环处理过程
img_path = os.path.join(dir_path, img) # 图像的完整路径
img_data = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE) # 使用 opencv读取图像
img_data = cv2.resize(img_data, (64, 64)) # 图片处理成统一大小
os.remove(img_path) # 删除原始图像
cv2.imwrite(img_path, img_data)# 保存新的图像
i = i + 1
if i%5000 == 0:
print('i:',i,'img_name:',img,image_label(img))
创建文件夹
在进行文件的复制的时候, 需要保证文件夹的存在, 我们可以使用以下的方式来进行判断和新建文件夹.
os.makedirs(os.path.dirname(dest_fpath), exist_ok=True)
shutil.copycopy(src_fpath, dest_fpath)
执行shell命令
使用os模块,还可以实现简单执行shell命令。这里除了使用下面的方式执行 shell 命令之外,我们还可以使用 subprocess 来执行命令,具体操作可以查看 Python 子进程管理–subprocess。这里建议使用 subprocess 来执行程序,不要直接使用 os.system。
os.system()
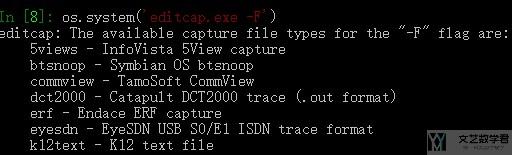
同时, 我们可以使用sys来执行cmd命令, 比如执行相应目录下的文件, 如下所示.
import os
print os.system('command')
下面是一个运行的示意图.
统计文件大小
可以使用os.path.getsize(file)来获得文件的大小, 单位是bytes.
def visitDir(path):
global totalSize
global fileNum
global dirNum
for lists in os.listdir(path):
sub_path = os.path.join(path, lists)
print(sub_path)
if os.path.isfile(sub_path):
fileNum = fileNum+1 # 统计文件数量
totalSize = totalSize+os.path.getsize(sub_path) # 文件总大小
elif os.path.isdir(sub_path):
dirNum = dirNum+1 # 统计文件夹数量
visitDir(sub_path) # 递归遍历子文件夹
上面是一段参考代码, 获取文件夹内文件的数量和文件的大小.
shutil
我们可以使用shutil模块来进行文件的复制, 粘贴, 等操作. 下面是一个简单的说明.
shutil.copyfile( src, dst) 从源src复制到dst中去。当然前提是目标地址是具备可写权限。抛出的异常信息为IOException. 如果当前的dst已存在的话就会被覆盖掉
shutil.move( src, dst) 移动文件或重命名
shutil.copymode( src, dst) 只是会复制其权限其他的东西是不会被复制的
shutil.copystat( src, dst) 复制权限、最后访问时间、最后修改时间
shutil.copy( src, dst) 复制一个文件到一个文件或一个目录
shutil.copy2( src, dst) 在copy上的基础上再复制文件最后访问时间与修改时间也复制过来了,类似于cp –p的东西
shutil.copy2( src, dst) 如果两个位置的文件系统是一样的话相当于是rename操作,只是改名;如果是不在相同的文件系统的话就是做move操作
shutil.copytree( olddir, newdir, True/Flase)
把olddir拷贝一份newdir,如果第3个参数是True,则复制目录时将保持文件夹下的符号连接,如果第3个参数是False,则将在复制的目录下生成物理副本来替代符号连接
shutil.rmtree( src ) 递归删除一个目录以及目录内的所有内容
这里再强调一下,如果只是文件的复制,使用 shutil.copy 即可;如果是文件夹的复制,那么需要使用 shutil.copytree。
sys
sys模块可以用于获取python解释器当前的一些状态变量,可以获取当前python的模块路径。
import sys
sys.path #查看当前python的环境变量
我们创建1.py文件写入如下代码
import sys
for i in sys.argv:
print(i)
接着运行 python3 1.py 1 2 3
可以看到输出为:
1.py
1
2
3
更多入门教程链接
关于更多入门教程, 可以通过下面的链接查看.
到这里这个系列就全部结束了,欢迎大家继续关注后面的内容。















 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









