







 超级会员免费看
超级会员免费看
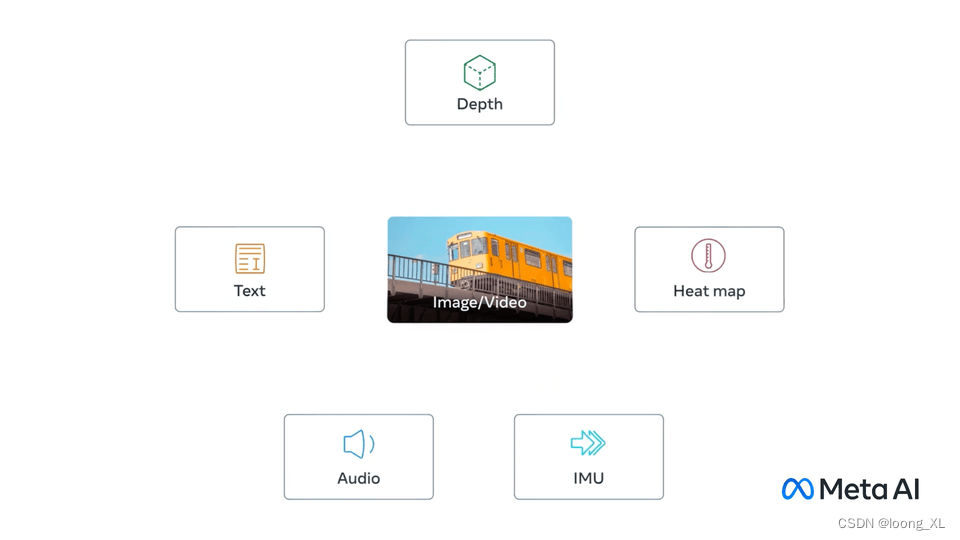
 ImageBind是一个能学习六种不同模态(图像、文本、音频、深度、热成像和IMU数据)联合嵌入的模型。它允许在单一空间中检索不同模态的相似信息。在Windows环境下,对文本和图像模态的相似度召回进行了测试,模型的Embedding向量维度为1024。预训练模型保存在.checkpoints/imagebind_huge.pth。
ImageBind是一个能学习六种不同模态(图像、文本、音频、深度、热成像和IMU数据)联合嵌入的模型。它允许在单一空间中检索不同模态的相似信息。在Windows环境下,对文本和图像模态的相似度召回进行了测试,模型的Embedding向量维度为1024。预训练模型保存在.checkpoints/imagebind_huge.pth。
参考:
https://github.com/facebookresearch/ImageBind
ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data
ImageBind 多个模态共享同一个空间Embedding,这样可以通过一个模态检索相似其他模态,相比CLIP文本图像两个模态,向外扩展了很多

代码测试
1、这边windows上测试的,由于audio相关库没装好,所以只测试了文本与图形相关模态的相似度召回计算;使用尽量还是linux机器

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











