









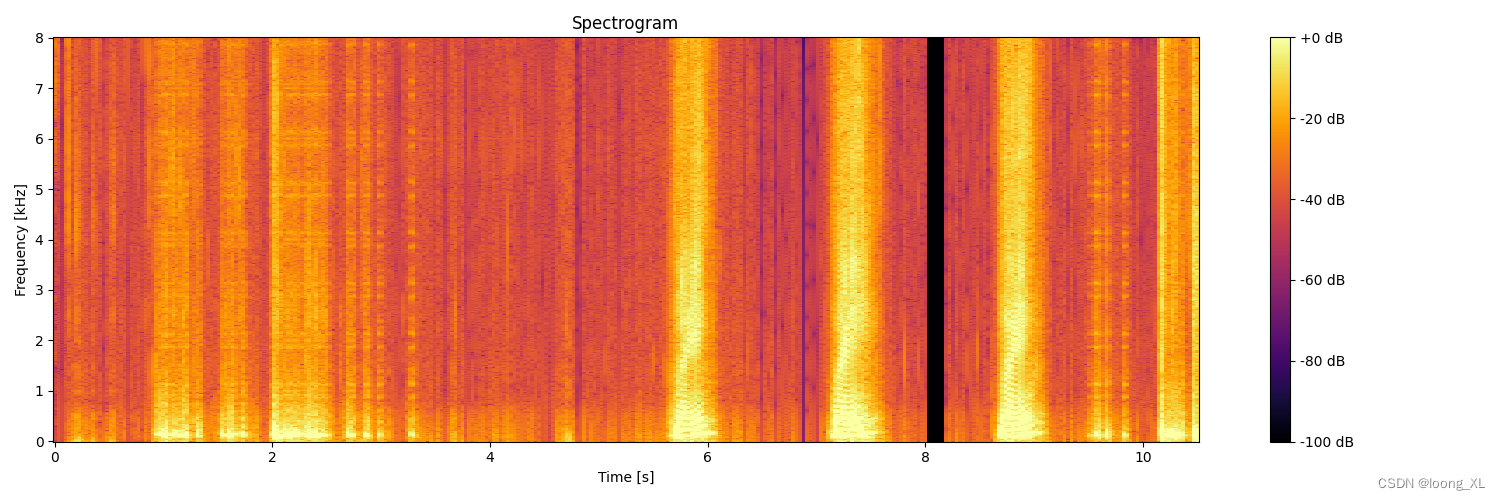
1、简单图形展示
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchaudio
def plot_waveform(waveform, sample_rate, title="Waveform", xlim=None, ylim=None):
waveform = waveform.numpy()
num_channels, num_frames = waveform.shape
time_axis = torch.arange(0, num_frames) / sample_rate
figure, axes = plt.subplots(num_channels, 1, figsize=(15, 5))
if num_channels == 1:
axes = [axes]
for c in range(num_channels):
axes[c].plot(time_axis, waveform[c], linewidth=1)
axes[c].grid(True)
if num_channels > 1:
axes[c].set_ylabel(f'Channel {c+1}')
if xlim:
axes[c].set_xlim(xlim)
if ylim:
axes[c].set_ylim(ylim)
figure.suptitle(title)
plt.xlabel('Time [s]')
plt.show()
# 示例音频文件路径
audio_path = r"E:\allchat\output_16000_mono_0.wav"
# 加载音频文件
waveform, sample_rate = torchaudio.load(audio_path)
# 绘制波形图
plot_waveform(waveform, sample_rate)
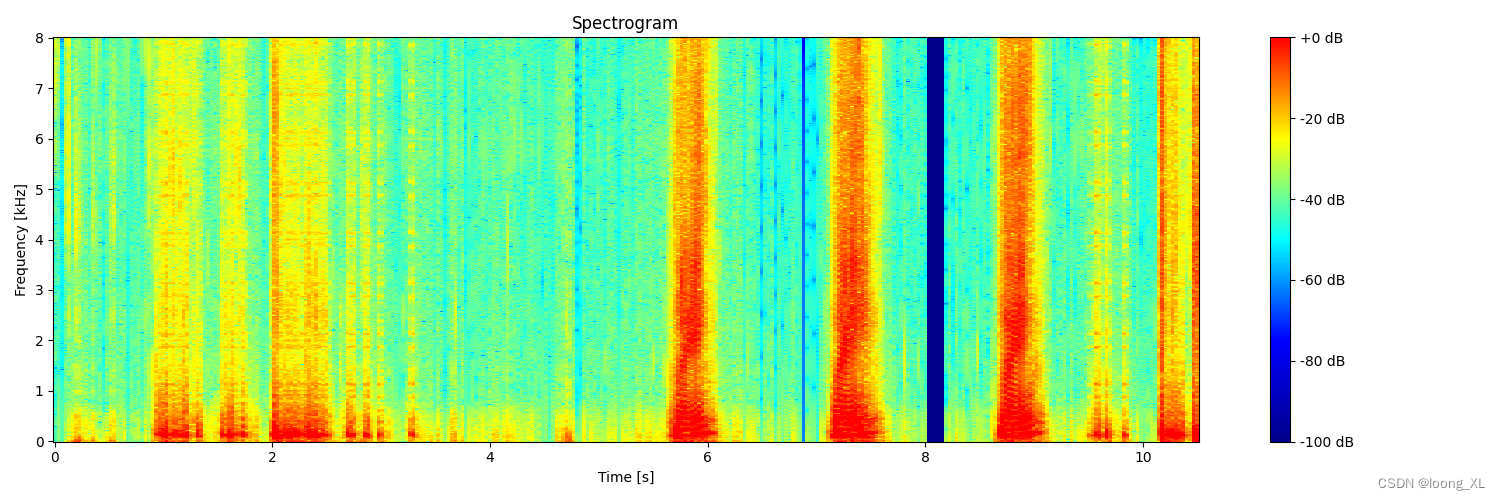
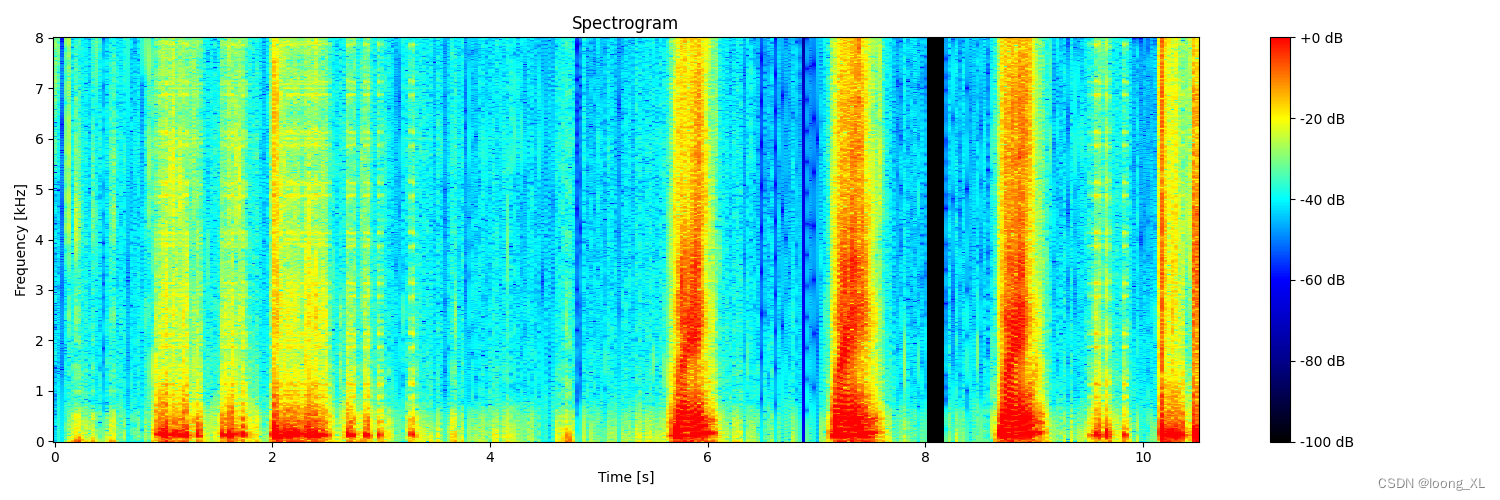
2、更美观可视化
import numpy as np
import matplotlib.pyplot as plt
import torch
from PIL import Image
def create_spectrogram(audio, sr=48000, n_fft=1024, hop=512, vmin=-100, vmax=0):
# 确保音频是 torch.Tensor 类型
audio = torch.as_tensor(audio)
# 应用短时傅里叶变换(STFT)
window = torch.hann_window(n_fft)
spec = torch.stft(audio, n_fft, hop, window=window, return_complex=True)
# 计算幅度谱并转换为分贝刻度
spec = spec.abs().clamp_min(1e-12).log10().mul(10)
# 如果是多声道,取平均
if spec.dim() > 2:
spec = spec.mean(0)
# 将谱图转换为numpy数组
spec_np = spec.cpu().numpy()
# 计算时间和频率轴
t = np.arange(0, spec_np.shape[1]) * hop / sr
f = np.arange(0, spec_np.shape[0]) * sr / 2 / (n_fft // 2) / 1000
# 创建图形
fig, ax = plt.subplots(figsize=(15, 5))
# 绘制谱图
im = ax.pcolormesh(t, f, spec_np, shading='auto', vmin=vmin, vmax=vmax, cmap='inferno')
# 设置标签
ax.set_xlabel('Time [s]')
ax.set_ylabel('Frequency [kHz]')
ax.set_title('Spectrogram')
# 添加颜色条
plt.colorbar(im, ax=ax, format='%+2.0f dB')
# 调整布局
plt.tight_layout()
# 将图形转换为PIL图像
fig.canvas.draw()
img = Image.frombytes('RGB', fig.canvas.get_width_height(), fig.canvas.tostring_rgb())
# 关闭matplotlib图形以释放内存
plt.close(fig)
return img
# 读取 WAV 文件
sr, audio = wavfile.read(r"E:\allchat\output_16000_mono_0.wav")
# 如果音频是整数类型,将其转换为 -1.0 到 1.0 之间的浮点数
if audio.dtype == np.int16:
audio = audio.astype(np.float32) / 32768.0
elif audio.dtype == np.int32:
audio = audio.astype(np.float32) / 2147483648.0
# 如果音频是立体声,取平均得到单声道
if audio.ndim > 1:
audio = audio.mean(axis=1)
# 创建谱图
spectrogram = create_spectrogram(audio, sr=sr)
# 显示图像
spectrogram.show()
# 保存图像
spectrogram.save('1_spectrogram.png')
颜色自定义:
颜色映射(colormap)来改变频谱图的颜色方案
import numpy as np
import matplotlib.pyplot as plt
import torch
from PIL import Image
from scipy.io import wavfile
from matplotlib.colors import LinearSegmentedColormap
def create_custom_cmap(base_color):
if base_color == 'blue':
colors = ['darkblue', 'blue', 'cyan', 'yellow', 'red']
elif base_color == 'black':
colors = ['black', 'darkblue', 'blue', 'cyan', 'yellow', 'red']
else:
raise ValueError("base_color must be 'blue' or 'black'")
return LinearSegmentedColormap.from_list("custom", colors)
def create_spectrogram(audio, sr=48000, n_fft=1024, hop=512, vmin=-100, vmax=0, base_color='blue'):
# 确保音频是 torch.Tensor 类型
audio = torch.as_tensor(audio)
# 应用短时傅里叶变换(STFT)
window = torch.hann_window(n_fft)
spec = torch.stft(audio, n_fft, hop, window=window, return_complex=True)
# 计算幅度谱并转换为分贝刻度
spec = spec.abs().clamp_min(1e-12).log10().mul(10)
# 如果是多声道,取平均
if spec.dim() > 2:
spec = spec.mean(0)
# 将谱图转换为numpy数组
spec_np = spec.cpu().numpy()
# 计算时间和频率轴
t = np.arange(0, spec_np.shape[1]) * hop / sr
f = np.arange(0, spec_np.shape[0]) * sr / 2 / (n_fft // 2) / 1000
# 创建自定义颜色映射
custom_cmap = create_custom_cmap(base_color)
# 创建图形
fig, ax = plt.subplots(figsize=(15, 5))
# 绘制谱图
im = ax.pcolormesh(t, f, spec_np, shading='auto', vmin=vmin, vmax=vmax, cmap=custom_cmap)
# 设置标签
ax.set_xlabel('Time [s]')
ax.set_ylabel('Frequency [kHz]')
ax.set_title('Spectrogram')
# 添加颜色条
plt.colorbar(im, ax=ax, format='%+2.0f dB')
# 调整布局
plt.tight_layout()
# 将图形转换为PIL图像
fig.canvas.draw()
img = Image.frombytes('RGB', fig.canvas.get_width_height(), fig.canvas.tostring_rgb())
# 关闭matplotlib图形以释放内存
plt.close(fig)
return img
# 读取 WAV 文件
sr, audio = wavfile.read(r"E:\allchat\output_16000_mono_0.wav")
# 如果音频是整数类型,将其转换为 -1.0 到 1.0 之间的浮点数
if audio.dtype == np.int16:
audio = audio.astype(np.float32) / 32768.0
elif audio.dtype == np.int32:
audio = audio.astype(np.float32) / 2147483648.0
# 如果音频是立体声,取平均得到单声道
if audio.ndim > 1:
audio = audio.mean(axis=1)
# 创建蓝色底的谱图
spectrogram_blue = create_spectrogram(audio, sr=sr, base_color='blue')
spectrogram_blue.save('1_spectrogram_blue.png')
# 创建黑色底的谱图
spectrogram_black = create_spectrogram(audio, sr=sr, base_color='black')
spectrogram_black.save('1_spectrogram_black.png')
# 显示图像
spectrogram_blue.show()
spectrogram_black.show()
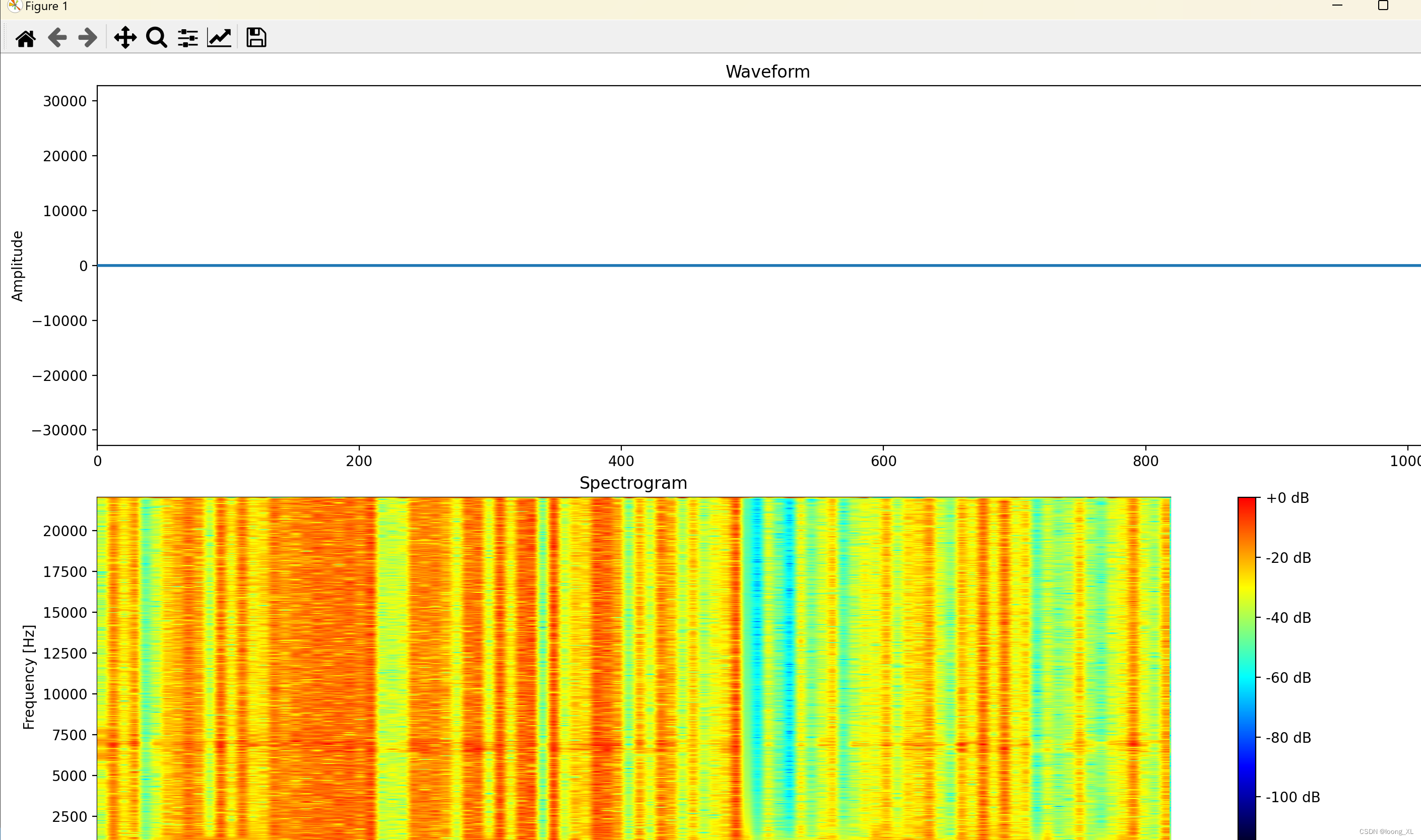
3、实时波纹显示可视化
pyaudio实时获取麦克风声音
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import pyaudio
import struct
from matplotlib.colors import LinearSegmentedColormap
def create_custom_cmap():
colors = ['black', 'blue', 'cyan', 'yellow', 'red']
return LinearSegmentedColormap.from_list("custom", colors)
# PyAudio 参数
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 1
RATE = 44100
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 10))
custom_cmap = create_custom_cmap()
# 波形图
line, = ax1.plot([], [], lw=2)
ax1.set_ylim(-32768, 32767)
ax1.set_xlim(0, CHUNK)
ax1.set_title('Waveform')
ax1.set_ylabel('Amplitude')
# 频谱图
spec = np.zeros((CHUNK//2, 100))
im = ax2.imshow(spec, cmap=custom_cmap, aspect='auto', origin='lower',
extent=[0, 5, 0, RATE//2], vmin=-120, vmax=0)
ax2.set_title('Spectrogram')
ax2.set_xlabel('Time [s]')
ax2.set_ylabel('Frequency [Hz]')
plt.colorbar(im, ax=ax2, format='%+2.0f dB')
def animate(i):
global spec
# 读取音频数据
raw_data = stream.read(CHUNK, exception_on_overflow=False)
data = np.frombuffer(raw_data, dtype=np.int16)
# 更新波形图
line.set_data(range(CHUNK), data)
# 计算频谱
fft_data = np.fft.rfft(data)
fft_data = np.abs(fft_data)
fft_data = 20 * np.log10(fft_data / np.max(fft_data) + 1e-10)
# 应用噪音门限
noise_floor = -80
fft_data = np.maximum(fft_data, noise_floor)
# 更新频谱图数据
spec = np.roll(spec, -1, axis=1)
spec[:, -1] = fft_data[:CHUNK//2]
# 更新频谱图
im.set_array(spec)
return line, im
anim = FuncAnimation(fig, animate, interval=30, blit=True)
plt.tight_layout()
plt.show()
stream.stop_stream()
stream.close()
p.terminate()
上面是声音波形图变化,下面是波纹变化
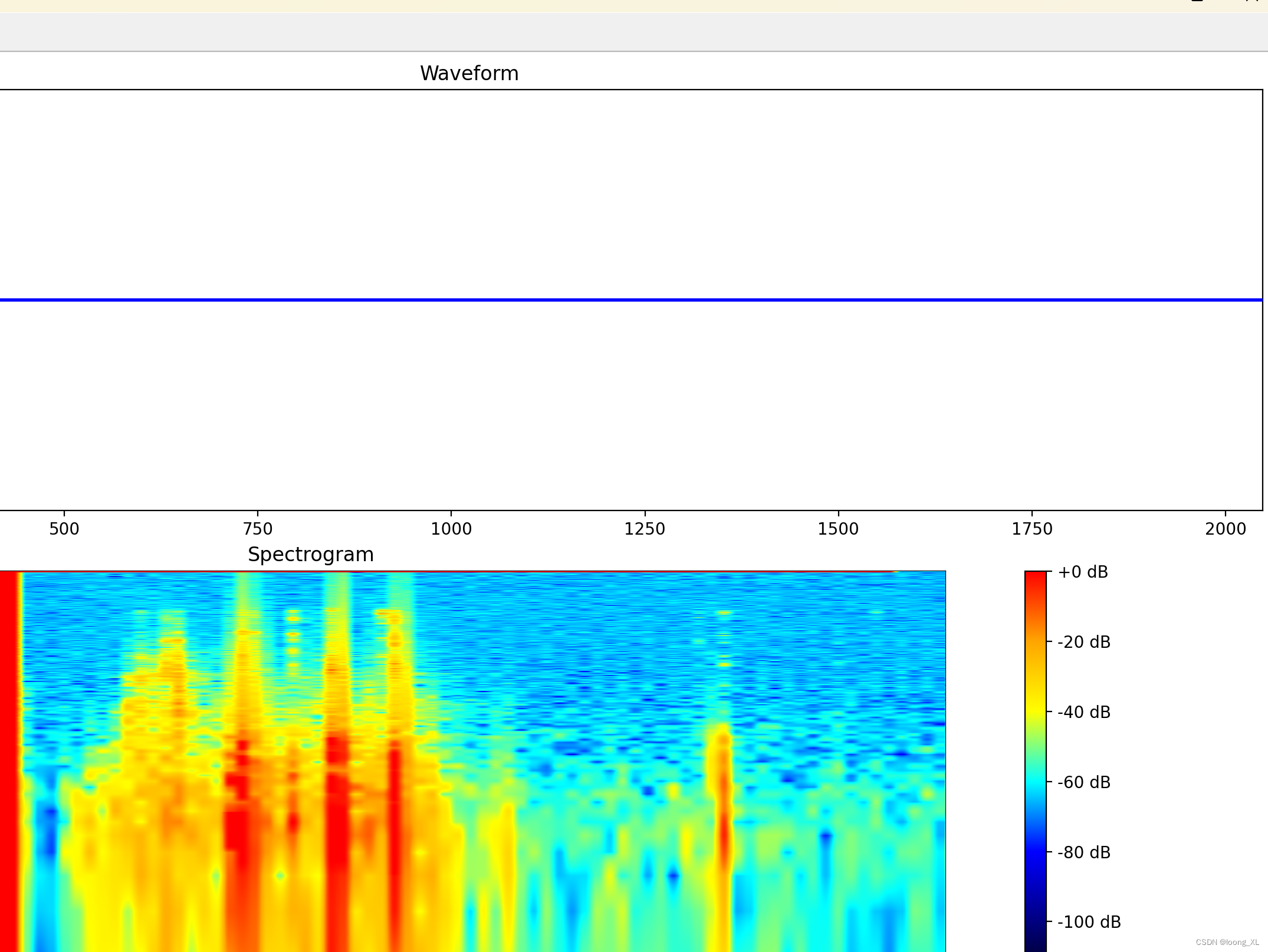
波谱显示美化优化版本:
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
import pyaudio
from matplotlib.colors import LinearSegmentedColormap
# PyAudio 参数
CHUNK = 2048 # 增加chunk大小以获得更好的频率分辨率
FORMAT = pyaudio.paFloat32
CHANNELS = 1
RATE = 44100
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(15, 10))
# 波形图
line, = ax1.plot([], [], lw=2, color='blue')
ax1.set_ylim(-1, 1)
ax1.set_xlim(0, CHUNK)
ax1.set_title('Waveform')
ax1.set_ylabel('Amplitude')
# 频谱图
max_freq = RATE // 2
freq_bins = CHUNK // 2
# 创建更丰富的颜色映射
colors = ['black', 'navy', 'blue', 'cyan', 'yellow', 'orange', 'red']
n_bins = 1000
cmap = LinearSegmentedColormap.from_list('custom', colors, N=n_bins)
# 使用对数频率刻度
freq_scale = np.logspace(np.log10(20), np.log10(max_freq), freq_bins)
spec = np.zeros((freq_bins, 100))
im = ax2.imshow(spec, aspect='auto', origin='lower',
extent=[0, 5, np.log10(20), np.log10(max_freq)],
vmin=-120, vmax=0, cmap=cmap)
ax2.set_title('Spectrogram')
ax2.set_xlabel('Time [s]')
ax2.set_ylabel('Frequency [Hz]')
ax2.set_yscale('log')
ax2.set_yticks([np.log10(20), np.log10(100), np.log10(1000), np.log10(10000), np.log10(20000)])
ax2.set_yticklabels(['20', '100', '1k', '10k', '20k'])
plt.colorbar(im, ax=ax2, format='%+2.0f dB')
def animate(i):
global spec
# 读取音频数据
raw_data = stream.read(CHUNK, exception_on_overflow=False)
data = np.frombuffer(raw_data, dtype=np.float32)
# 更新波形图
line.set_data(range(CHUNK), data)
# 计算频谱
fft_data = np.fft.rfft(data)
fft_data = np.abs(fft_data[:freq_bins])
# 应用对数频率刻度
fft_data = np.interp(freq_scale, np.linspace(0, max_freq, len(fft_data)), fft_data)
# 转换为dB,并应用动态范围压缩
fft_data = 20 * np.log10(fft_data + 1e-10)
fft_data = np.clip(fft_data, -120, 0)
# 更新频谱图数据
spec = np.roll(spec, -1, axis=1)
spec[:, -1] = fft_data
# 更新频谱图
im.set_array(spec)
return line, im
anim = FuncAnimation(fig, animate, interval=30, blit=True)
plt.tight_layout()
plt.show()
stream.stop_stream()
stream.close()
p.terminate()

















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











