







 本文提出了一种新型的Combiner模型,它改进了Transformer架构,通过稀疏注意力门和层次注意力块,从自然语言中学习树状结构,增强了模型的可解释性和性能。在Search Session Understanding任务和无监督的PTB数据集实验中,Combiner模型表现出优于BERT的性能,展示了深度学习在捕捉自然语言结构方面的潜力。
本文提出了一种新型的Combiner模型,它改进了Transformer架构,通过稀疏注意力门和层次注意力块,从自然语言中学习树状结构,增强了模型的可解释性和性能。在Search Session Understanding任务和无监督的PTB数据集实验中,Combiner模型表现出优于BERT的性能,展示了深度学习在捕捉自然语言结构方面的潜力。

一、背景介绍
自从Tansformer结构提出以来,以BERT以代表的模型横扫NLP领域的各个任务。然而,Transformer中密集的注意力机制无法利用自然语言中的内在结构。这篇文章提出了一种新的Transfomer架构—Combiner模型,可以从自然语言中学习树状结构的注意力模式,从而增强了模型的可解释性。
二、方法介绍
传统的Transfomer中使用Self-attention机制对词向量进行了融合,获取了更多的上下文信息。例如:给定输入词向量为H,将词向量H 映射到三个空间Q,K,V,并通过如下公式1来计算注意力分值。
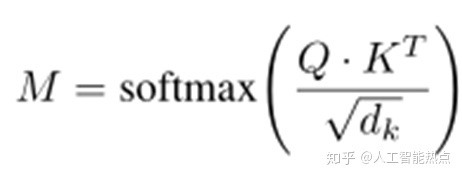
为了克服传统Transfomer中的密集输出,该文章提出了一种稀疏多层次的Transformer结构。它包含两个模块Sparse attention gate以及Hierarchical attention block。其中,Sparse atte
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









