







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
文章目录
项目背景
小红书的用户画像是小红书品牌营销的必备技能,也是小红书推广种草的一个重要前提。通过对小红书用户画像进行分析,对品牌进行精准营销,实现更高的流量转化。
字段描述
该数据共1000条数据,共16个字段,分别是
- 达人名称
- 小红书号
- 性别
- 地域
- 简介
- 更新时间
- 认证信息
- 粉丝数
- 赞藏总数
- 品牌合作人
- 签约MCN
- 图文笔记报价
- 视频笔记报价
- 达人标签
- 认证类型
- 商业笔记数
以下是表的部分数据:

一、了解并处理数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font='Microsoft YaHei',font_scale=1.1,palette = 'Set2')
from warnings import filterwarnings
filterwarnings('ignore')
pd.set_option("display.max_columns",30) #设置显示的最大列数
1、读取数据
# 导入数据
data_dp = pd.read_csv('达人列表小红书.csv')
data_dp.shape
(1000, 16)
data_dp.head()
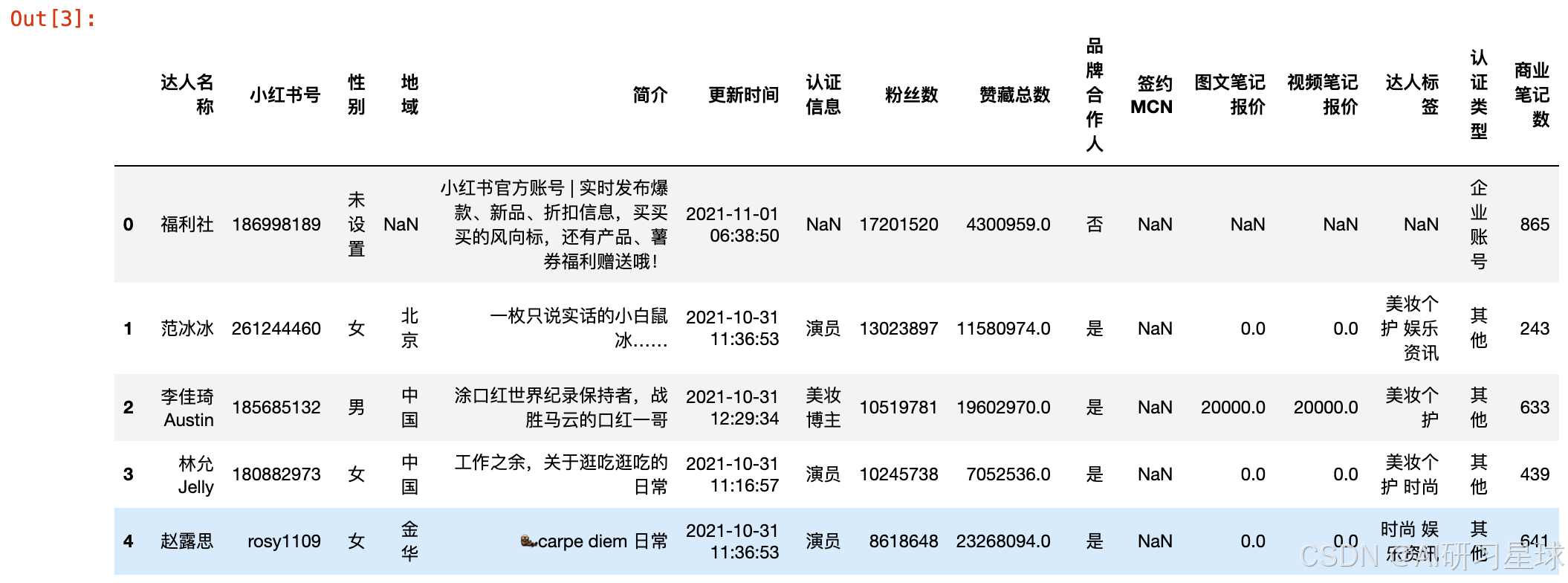
2、查看数据类型
data_dp.info()

3、统计空值并对空值进行处理
数据分析过程中对空值的处理有几种方式:填充法,删除法,替换法,这里采用填充的方式对空值进行处理
data_dp.isnull().sum()

# 处理空值
data_dp['地域'].fillna("未填写",inplace = True)
data_dp['认证信息'].fillna("无认证信息",inplace = True)
data_dp['签约MCN'].fillna("未签约",inplace = True)
data_dp['图文笔记报价'].fillna("无报价",inplace = True)
data_dp['视频笔记报价'].fillna("无报价",inplace = True)
4、了解关键字段信息
columns_list = ['性别','认证信息','品牌合作人', '签约MCN','达人标签','认证类型']
for l in columns_list:
print(l,":")
print(data_dp[l].unique())
print() #打印空行

5、用lambda函数处理关键字段
由于认证信息中存在 “ | ”字符,为了统计的结果更准确些,这里采取重新提取新字段的方式来进行处理,这里使用匿名函数 lambda来处理并创建新的列
data_dp['认证信息_2'] = data_dp['认证信息'].apply(lambda x:x.split(' | ')[1] if " | " in x else x)
data_dp['是否有认证信息'] = data_dp['认证信息_2'].apply(lambda x:"无" if x in "无认证信息" else "有")
data_dp['是否有签约'] = data_dp['签约MCN'].apply(lambda x:"未签约" if x in "未签约" else "有签约")
关键字段基本整理完整,下面进行数据的统计与可视化
二、达人信息可视化
1、性别 & 品牌合作人 & 认证类型 的分布
plt.figure(figsize = (16,13))
n = 0
for x in ['性别','品牌合作人','是否有认证信息','是否有签约','认证类型']:
size_n = data_dp[x].value_counts()
n += 1
plt.subplot(2,3,n)
plt.pie(size_n.values,labels = size_n.index,wedgeprops={'width':0.35,'edgecolor':'w'},
autopct='%.1f%%',pctdistance=0.8,startangle = 180)
plt.axis("equal")
plt.title(x)
plt.show()
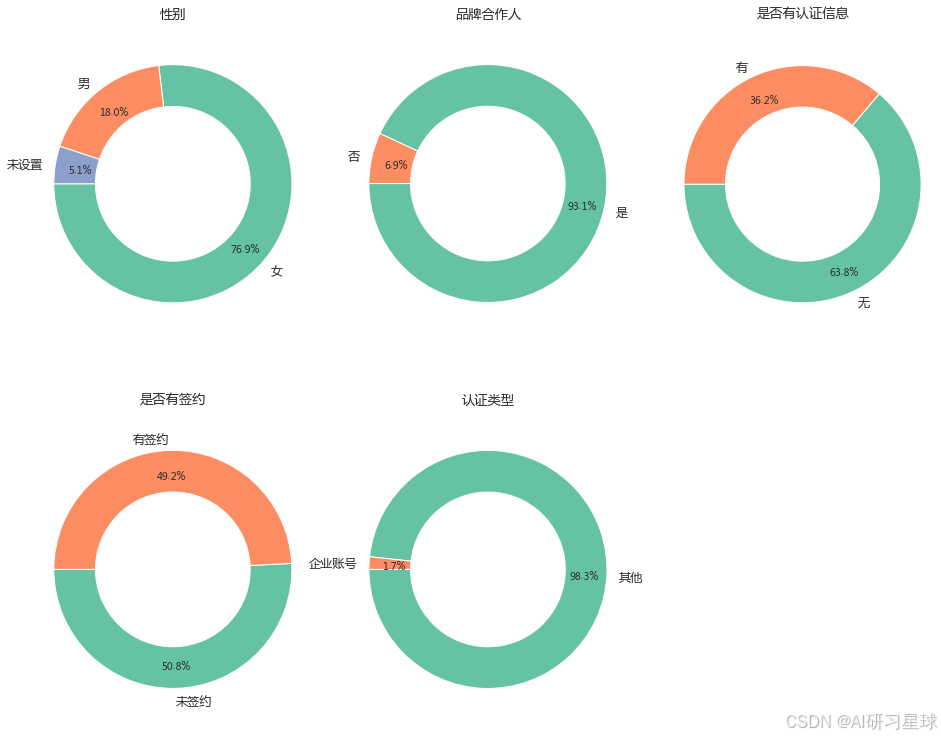
假设原始数据无误,则根据上图得到信息如下:
- 77%的达人为女性;
- 64% 的达人账号没有认证信息
- 超过98%的账号为企业认证类型
- 超93% 的达人均为品牌合作人
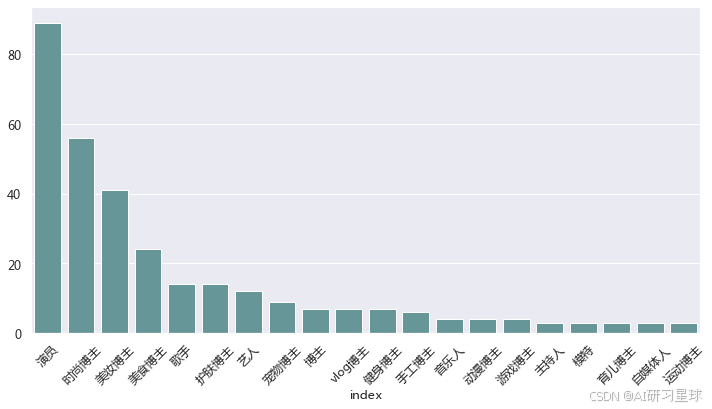
2、认证信息排名 TOP20
result = data_dp['认证信息_2'].value_counts()[:21].reset_index(name = 'total')
result = result[result['index']!='无认证信息']
plt.figure(figsize = (12,6))
sns.barplot(x = result['index'],y = result['total'],data = result,color = 'CadetBlue')
plt.xticks(rotation = 45)
plt.ylabel('')
plt.show()
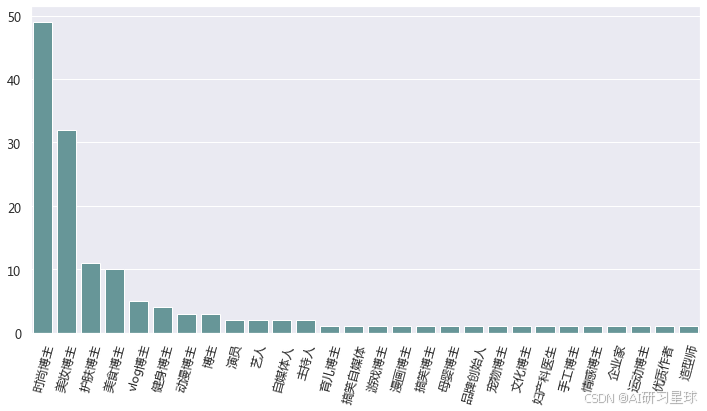
3、有认证信息的达人中签约最多博主排名
result = data_dp[(data_dp['是否有签约']== '有签约')&(data_dp['是否有认证信息']=='有')]
result = result['认证信息_2'].value_counts().reset_index(name = 'total')
plt.figure(figsize = (12,6))
sns.barplot(x = result['index'],y = result['total'],data = result,color = 'CadetBlue')
plt.xticks(rotation = 75)
plt.ylabel('')
plt.xlabel('')
plt.show()
4、达人标签
import pyecharts.options as opts
from pyecharts.charts import WordCloud
result = data_dp['达人标签'].value_counts().reset_index(name = 'total')
x_data = result['index'].tolist()
y_data = result['total'].tolist()
(
WordCloud()
.add(" ", [list(z) for z in zip(x_data, y_data)],word_size_range=[30, 90])
.set_global_opts(
title_opts=opts.TitleOpts(
title="达人标签排名", title_textstyle_opts=opts.TextStyleOpts(font_size=18)
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
).render_notebook()





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











