







算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我
文章目录
一、项目背景
数据集《2021春运火车票余量数据》中,包含了从2021年2月6日至11日,一线城市出发前往二三四线城市的火车票余量数据。
本问题关注点在火车班次,问题就可以转变为 2021年2月6日至11日,对一线城市出发前往二三四线城市的火车班次进行热力图可视化。
但是,这个数据集中呈现的是出发站和到达站的信息,而不是城市的信息。由于一个城市可能有多个火车站,如广州市就有广州南、广州东、广州北、广州站等多个站点,故需要先将站点信息转化为城市信息才能进行进一步的分析和可视化。
数据集《中国火车站站点地理数据》含全国3K个火车站站点数据,包含站点名称、站点地址、铁路局、省、市、经纬度
通过这个数据集,就可以把站点数据转变为城市数据了。
二、数据说明
本数据集一共28个文件,为:从2021年2月6日-11日,一线城市出发前往二三四现城市的火车票余量数据。
- 文件名后4位为查询日期,具体时间见「查询时间」字段,查询时间为1月14、15、17、18日,不同查询日期同一车次可能余票情况不一;
- 可通过「页面网址」字段,URL后缀中的日期来判别车票出发日期;
- 「历时1」表示火车行驶时间
- 「可以预定」字段:若有“预定”两字表示还有余票,若为空表示所有类型的票都卖完了
三、数据分析
1、分析始发站、到达站及城市分析
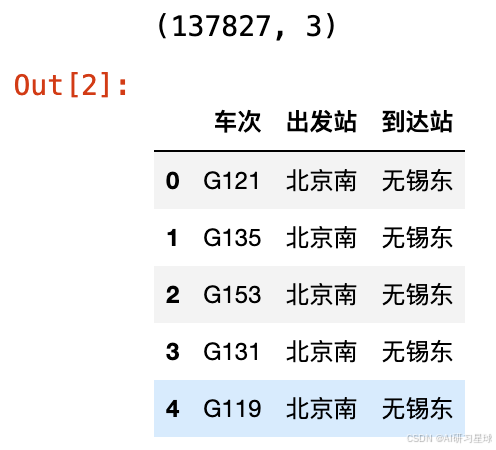
a、获取始发站及到达站数据
数据的查询时间为1月14、15、17、18日,因此这四天能查到的班次理论上是一致的,只有余票的区别(本题不考虑余票),因此只要读取18日的7个文件做下一步分析
import pandas as pd
df_lst = []
for i in range(7):
df = pd.read_csv(f'2020trainticket5346/一线2二三四线0118({i+1}).csv')
df = df.iloc[:,:3] # 只获取前3列
df_lst.append(df)
# 纵向合并
dat = pd.concat(df_lst,axis=0)
print(dat.shape)
dat.head()
b、将站点转换为所属城市
df_cnstation = pd.read_csv('cnstation.csv')
df_cnstation.head()
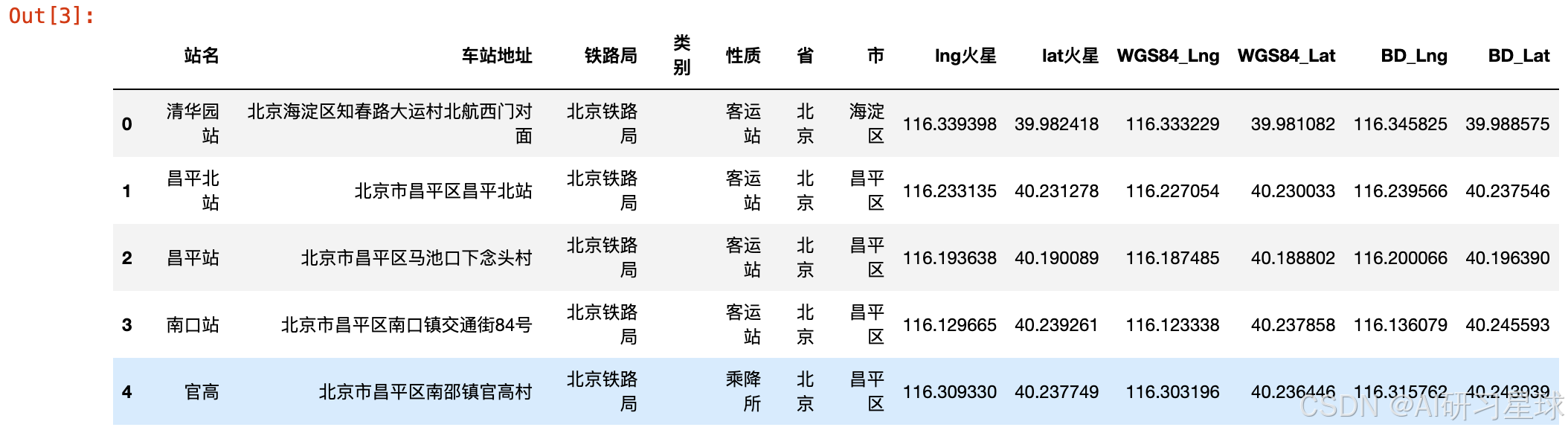
第一眼就发现了问题,“北京”划分到了省,因此有可能直辖市都归属到了省
同时站名中有的有“站”,有的没有“站”。为了明确可以先做一些数据探索
df_cnstation = df_cnstation.iloc[:,[0,5,6]]
df_cnstation.head()

df_cnstation.iloc[:,1].value_counts()

重庆、北京、天津、上海4个城市被划分到了“省”,而相应的“市”实际上是区。简单的修正策略就是将这4个城市的“市”都改为城市名即可。
df_cnstation.loc[:,'市'][df_cnstation.loc[:,'省']=='北京'] = '北京'
df_cnstation.loc[:,'市'][df_cnstation.loc[:,'省']=='重庆'] = '重庆'
df_cnstation.loc[:,'市'][df_cnstation.loc[:,'省']=='天津'] = '天津'
df_cnstation.loc[:,'市'][df_cnstation.loc[:,'省']=='上海'] = '上海'
df_cnstation.head()

# 去掉站名中的“站”字
df_cnstation['站名'] = df_cnstation['站名'].str.split('站').str[0]
df_cnstation.head()

c、获取出发市和到达市
df1 = pd.merge(dat,df_cnstation,left_on='出发站',right_on='站名')
df2 = pd.merge(df1,df_cnstation,left_on='到达站',right_on='站名')
df2.head()
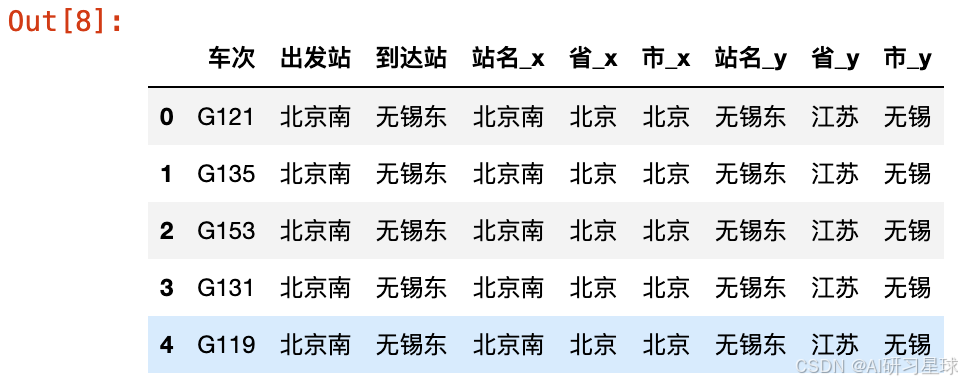
res = df2.iloc[:,[0,5,8]]
res.rename(columns={'市_x': '出发市', '市_y': '到达市'}, inplace = True)
res.head()

虽然出发城市均为“一线城市”,但范围较广。为了方便后面理解和可视化,只从其中筛选出北上广深作为一线城市
res_bj = res[res.loc[:,'出发市']=='北京'].iloc[:,2].value_counts()
res_sh = res[res.loc[:,'出发市']=='上海'].iloc[:,2].value_counts()
res_gz = res[res.loc[:,'出发市']=='广州'].iloc[:,2].value_counts()
res_sz = res[res.loc[:,'出发市']=='深圳'].iloc[:,2].value_counts()
# 获取目的地和班次数元祖列表
bj_arr_num = list(zip(res_bj.index.tolist(),res_bj.tolist()))
sh_arr_num = list(zip(res_sh.index.tolist(),res_sh.tolist()))
gz_arr_num = list(zip(res_gz.index.tolist(),res_gz.tolist()))
sz_arr_num = list(zip(res_sz.index.tolist(),res_sz.tolist()))
# 以北京为例
bj_arr_num[:6]

# 获取出发地和目的地元祖列表
bj_dep_arr = list(zip(['北京']*len(bj_arr_num),res_bj.index.tolist()))
sh_dep_arr = list(zip(['上海']*len(sh_arr_num),res_sh.index.tolist()))
gz_dep_arr = list(zip(['广州']*len(gz_arr_num),res_gz.index.tolist()))
sz_dep_arr = list(zip(['深圳']*len(sz_arr_num),res_sz.index.tolist()))
# 以北京为例
bj_dep_arr[:6]

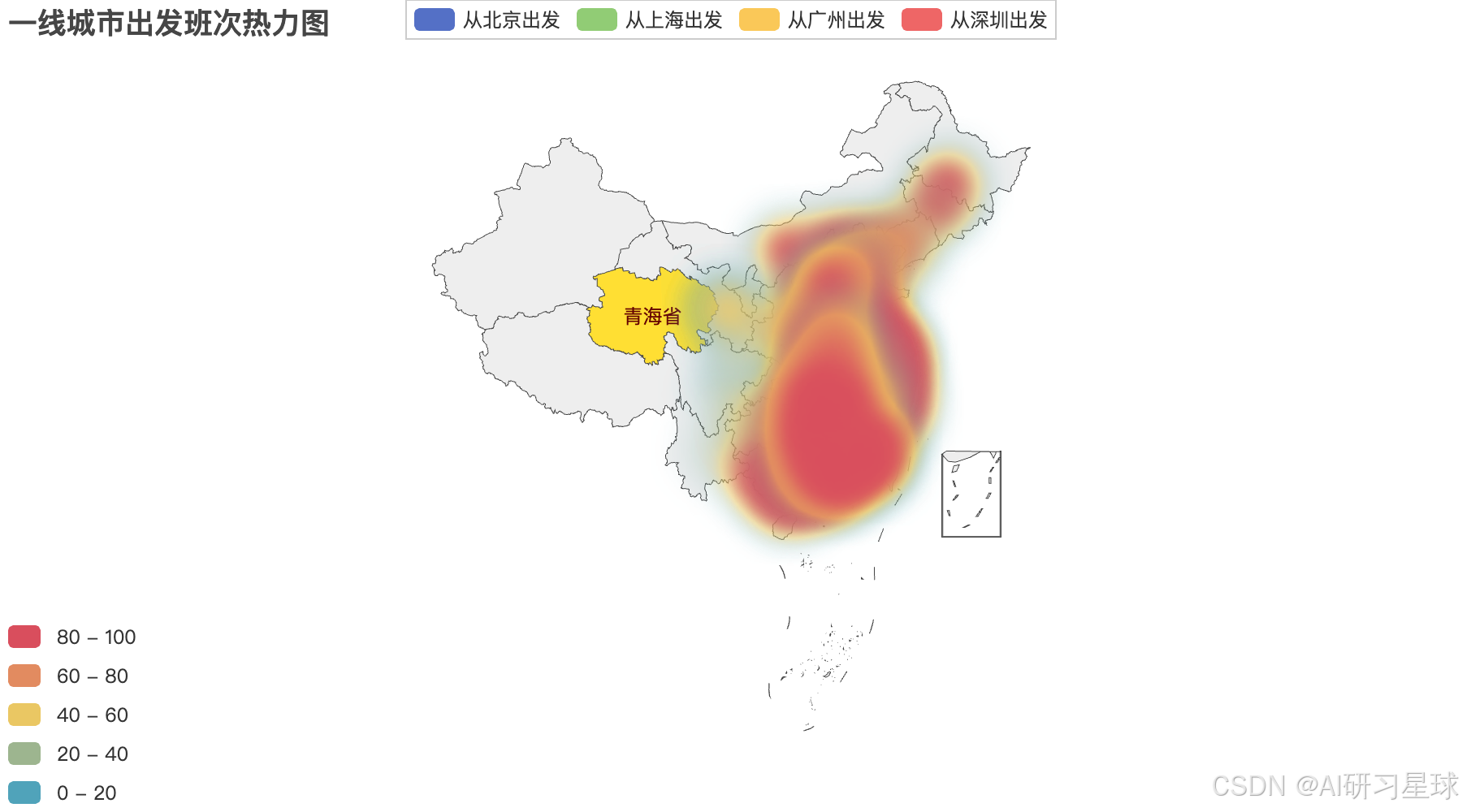
d、可视化
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ChartType, SymbolType
c = (
Geo()
.add_schema(maptype="china")
.add("从北京出发", bj_arr_num,type_=ChartType.HEATMAP)
.add("从上海出发", sh_arr_num,type_=ChartType.HEATMAP)
.add("从广州出发", gz_arr_num,type_=ChartType.HEATMAP)
.add("从深圳出发", sz_arr_num,type_=ChartType.HEATMAP)
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
visualmap_opts=opts.VisualMapOpts(is_piecewise=True),
title_opts=opts.TitleOpts(title="一线城市出发班次热力图"),
)
)
# 获得了动态热力图
c.render_notebook()
2、通过余票情况,分析春运返乡热度
跟上一问类似,也直接分析18号查询2021年2月6日至11日,对一线城市出发前往二三四线城市的火车班次情况
不同之处在于,这一问需要关注【商务座特等座、软卧一等卧、硬卧二等卧、硬座、可以预定】这几列
import pandas as pd
df_lst = []
for i in range(7):
df = pd.read_csv(f'2020trainticket5346/一线2二三四线0118({i+1}).csv')
df_lst.append(df)
dat = pd.concat(df_lst,axis=0)
dat = dat.iloc[:,0:12].drop(columns=['出发时间','到达时间','历时1','历时2'])
dat.head()
# 合并出发和到达站并调整位置
dat["出发-到达"] = '-'
dat["出发-到达"] = dat["出发站"] + dat["出发-到达"]+ dat["到达站"]
dat = dat.drop(columns=['出发站','到达站'])
test = dat['出发-到达']
del dat['出发-到达']
dat.insert(1,'出发-到达', test)
dat.head()
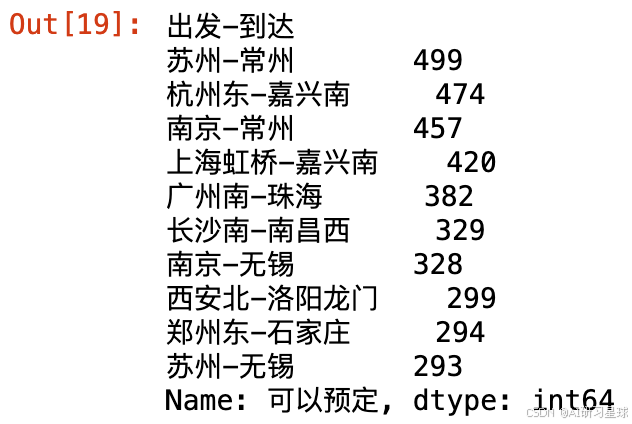
a、哪些出发站-到达站可预订车次的数量最高?哪些全部车次可预定?
dep_arr_grouped = dat.groupby(by=['出发-到达'])
dep_arr_num = dep_arr_grouped.count()['可以预定']
dep_arr_prob = dep_arr_grouped.count()['可以预定']/dep_arr_grouped.count()['车次']
# 数量排序及可视化
top10_num = dep_arr_num.sort_values(ascending=False)[0:10]
top10_num
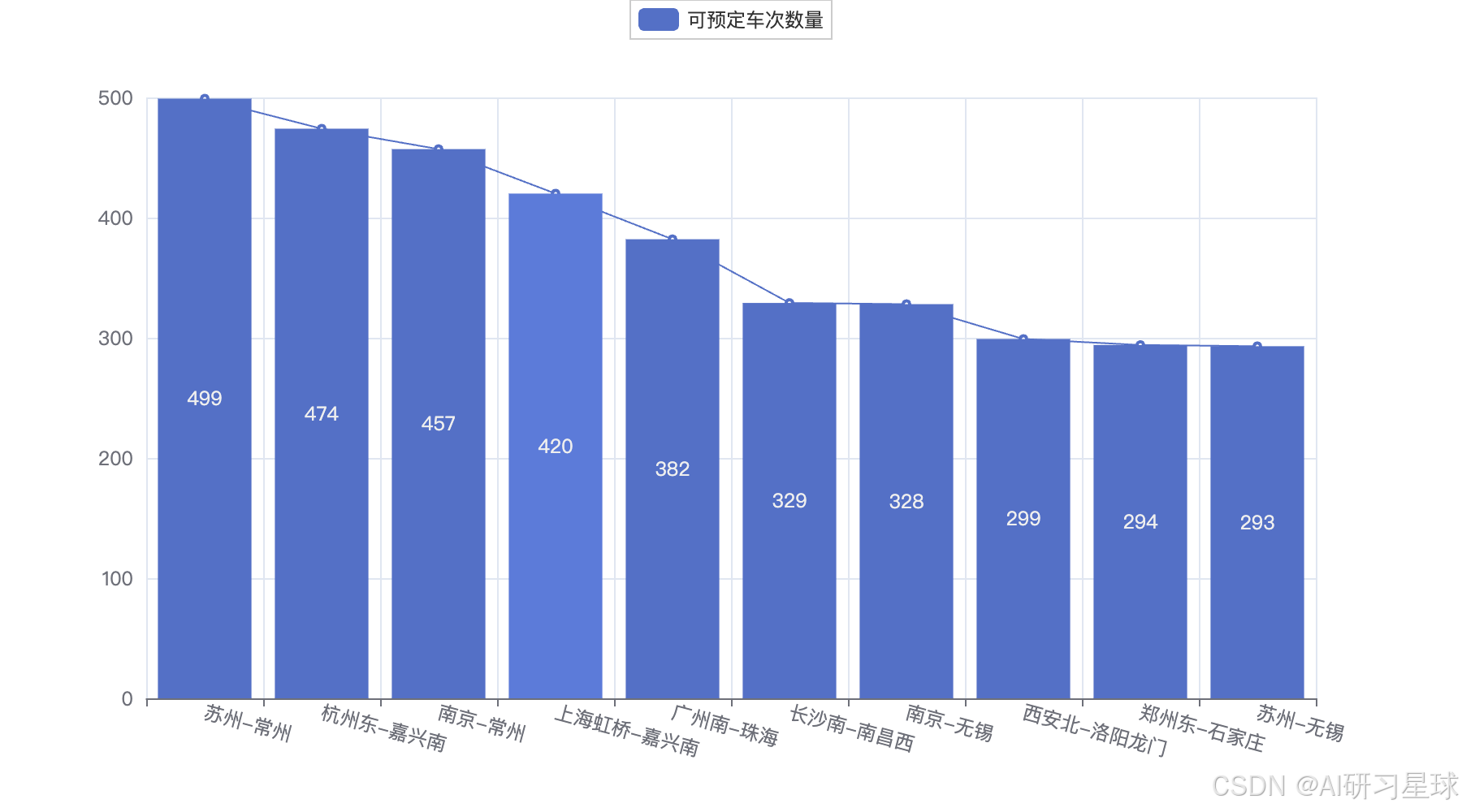
from pyecharts.charts import Bar, Line
from pyecharts import options as opts
bar = (
Bar(opts.InitOpts(js_host="https://cdn.kesci.com/lib/pyecharts_assets/"))
.add_xaxis(top10_num.index.tolist())
.add_yaxis("可预定车次数量", top10_num.tolist())
.set_global_opts(
datazoom_opts=[opts.DataZoomOpts(is_show=True)],
title_opts=opts.TitleOpts(title="出发-到达车次数量 Top10")
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15))
)
)
line = (
Line()
.add_xaxis(xaxis_data=top10_num.index.tolist())
.add_yaxis(
series_name="可预定车次数量",
y_axis=top10_num.tolist(),
label_opts=opts.LabelOpts(is_show=False),
)
)
# 重叠折线图到柱形图上
bar.overlap(line).render_notebook()
# 也可以直接反映出Top10可预定数量它们各自真实的比例
dep_arr_prob[top10_num.index.tolist()]

bar = (
Bar(opts.InitOpts(js_host="https://cdn.kesci.com/lib/pyecharts_assets/"))
.add_xaxis(top10_num.index.tolist())
.add_yaxis("可预定车次数量", top10_num.tolist())
.set_global_opts(
datazoom_opts=[opts.DataZoomOpts(is_show=True)],
title_opts=opts.TitleOpts(title="出发-到达车次数量 Top10")
)
.extend_axis(
yaxis=opts.AxisOpts(
name="比例",
type_="value",
min_=0,
max_=1,
interval=0.2
)
)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15))
)
)
new_line = (
Line()
.add_xaxis(xaxis_data=top10_num.index.tolist())
.add_yaxis(
series_name="可预定车次占比",
y_axis=dep_arr_prob[top10_num.index.tolist()].tolist(),
yaxis_index=1,
label_opts=opts.LabelOpts(is_show=False),
)
)
# 重叠折线图到柱形图上
bar.overlap(new_line).render_notebook()
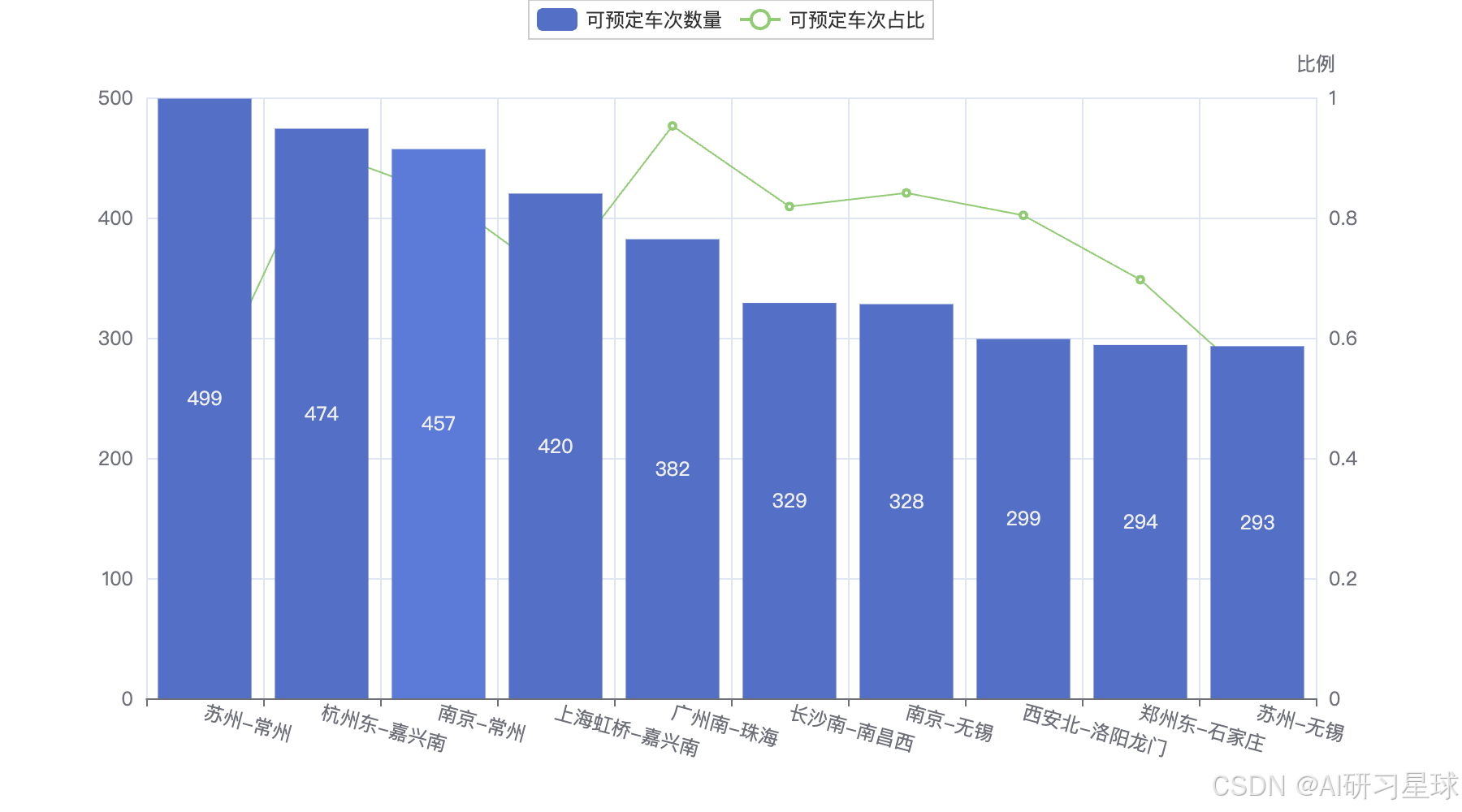
可见有的出发地-到达地,可预定车次数量多是由于本身车次多。
如果要查看哪些出发地-到达地可预定是100%,简单两行代码也能搞定:
print(len(dep_arr_prob[dep_arr_prob == 1]))
dep_arr_full = dep_arr_prob[dep_arr_prob == 1].index.tolist()
# 有1547个出发地-到达地符合要求,具体可见列表
dep_arr_full[0:10]

b、哪些车次剩余票数最多?
要回答这一问绕不开一个实际问题:很多车次显示的票数不是一个具体数值,而是“有”字
根据官网的设定20张以内就显示纯数字,20张以上的显示的是有票,因此假设“有”代表20张票(实际上可能要多很多)
# 数据之前已经处理了一部分
# 重置索引
dat = dat.reset_index()
dat = dat.iloc[:,1:]
dat.head()
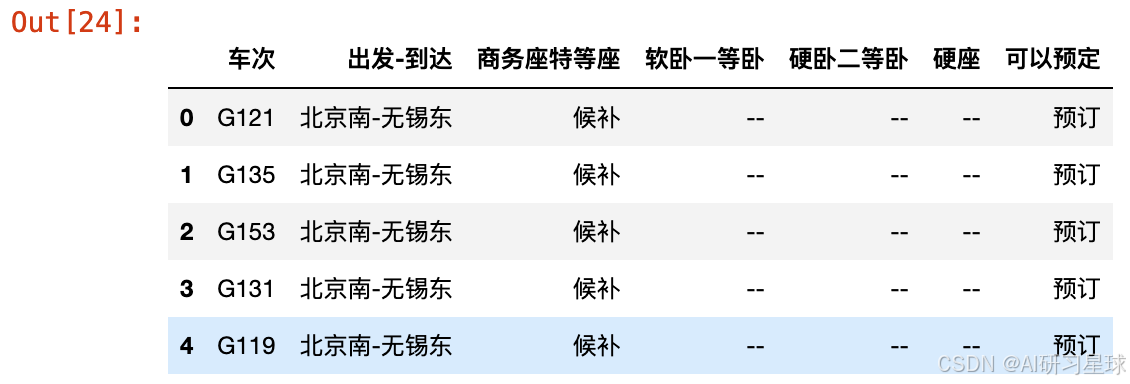
# 接下来需要将“候补”和“--”都改为数字0,“有”改为数字20,其他存在的干扰项都转为数字0
# str.contains也可以,用比较不懂脑筋的方法逐个替换不合适的
dat.iloc[:,2:6] = dat.iloc[:,2:6].replace('候补', 0).replace('--', 0).replace('有', 20).replace('*', 0)\
.replace('有折', 0).replace('有\n折', 0).replace('1折', 0).replace('11折', 0).replace('1\n折', 0).replace('20\n折', 0).replace('17\n折', 0)\
.replace('5\n折', 0).replace('13\n折', 0).replace('3\n折', 0)
print(dat.dtypes)

dat['剩余票数'] = dat['商务座特等座'].astype('int') + dat['软卧一等卧'].astype('int') + dat['硬卧二等卧'].astype('int') + dat['硬座'].astype('int')
dat.head(10)
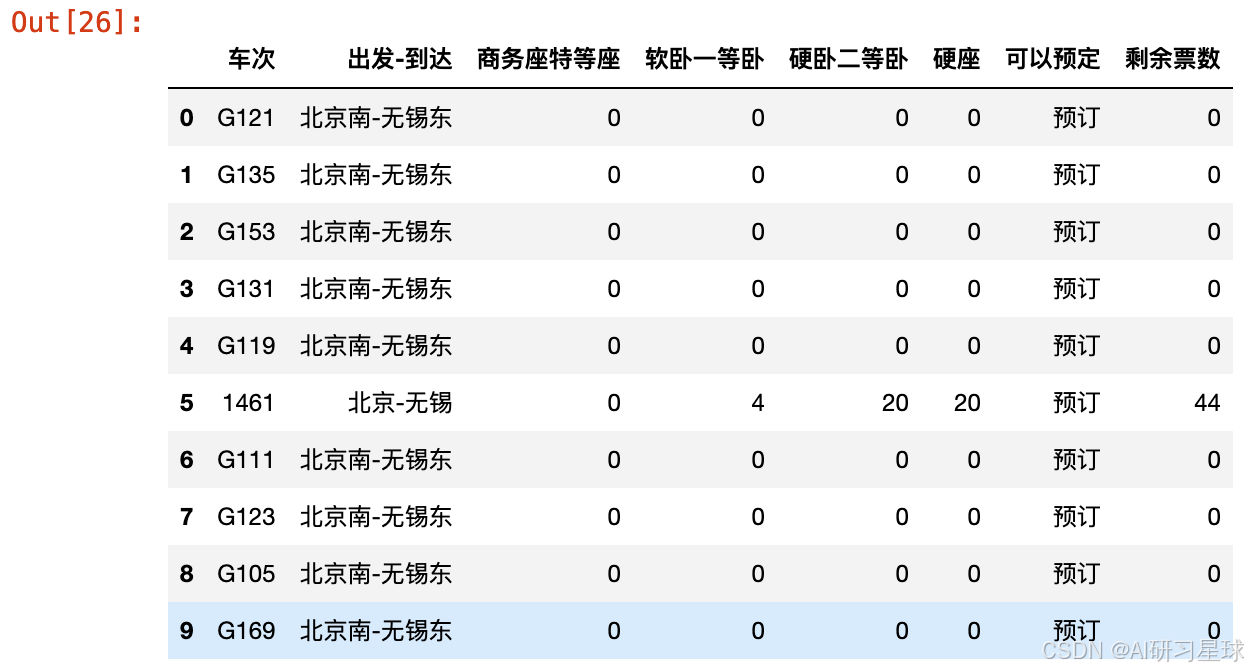
从结果中看到,车次剩余票数最多均为60张,这是由于分析的开头假定了“有”字代表20张,因此这些车次只能说票源依然充足,但不确定具体的票数。
算法学习、4对1辅导、论文辅导、核心期刊
项目的代码和数据下载可以通过公众号滴滴我




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











